
Abstract
Dry eye disease (DED) has a prevalence of between 5 and 50%, depending on the diagnostic criteria used and population under study. However, it remains one of the most underdiagnosed and undertreated conditions in ophthalmology. Many tests used in the diagnosis of DED rely on an experienced observer for image interpretation, which may be considered subjective and result in variation in diagnosis. Since artificial intelligence (AI) systems are capable of advanced problem solving, use of such techniques could lead to more objective diagnosis. Although the term ‘AI’ is commonly used, recent success in its applications to medicine is mainly due to advancements in the sub-field of machine learning, which has been used to automatically classify images and predict medical outcomes. Powerful machine learning techniques have been harnessed to understand nuances in patient data and medical images, aiming for consistent diagnosis and stratification of disease severity. This is the first literature review on the use of AI in DED. We provide a brief introduction to AI, report its current use in DED research and its potential for application in the clinic. Our review found that AI has been employed in a wide range of DED clinical tests and research applications, primarily for interpretation of interferometry, slit-lamp and meibography images. While initial results are promising, much work is still needed on model development, clinical testing and standardisation.
1. Introduction
Dry Eye Disease (DED) is one of the most common eye diseases worldwide, with a prevalence of between 5 and 50%, depending on the diagnostic criteria used and study population [1]. Yet, although symptoms stemming from DED are reported as the most common reason to seek medical eye care [1], it is considered one of the most underdiagnosed and undertreated conditions in ophthalmology [2]. Symptoms of DED include eye irritation, photophobia and fluctuating vision. The condition can be painful and might result in lasting damage to the cornea through irritation of the ocular surface. Epidemiological studies indicate that DED is most prevalent in women [3] and increases with age [1]. However, the incidence of DED is likely to increase in all age groups in coming years due to longer screen time and more prevalent use of contact lenses, which are both risk factors [4]. Other risk factors include diabetes mellitus [5] and exposure to air-pollution [6]. DED can have a substantial effect on the quality of life, and may impose significant direct and indirect public health costs as well as personal economic burden due to reduced work productivity.
DED is divided into two subtypes defined by the underlying mechanism of the disease: (i) aqueous deficient DED, where tear production from the lacrimal gland is insufficient and (ii) evaporative DED (the most common form), which is typically caused by dysfunctional meibomian glands in the eyelids. Meibomian glands are responsible for supplying meibum, which is a concentrated substance that normally covers the surface of the cornea to form a protective superficial lipid layer that guards against evaporation of the underlying tear film. The ability to reliably distinguish between aqueous deficient and evaporative DED, their respective severity levels and mixed aqueous/evaporative forms is important in deciding the ideal modality of treatment. A fast and accurate diagnosis relieves patient discomfort and also spares them unnecessary expense and exposure to potential side effects associated with some treatments. A tailor made treatment plan can yield improved treatment response and maximize health provider efficiency.
The main clinical signs of DED are decreased tear volume, more rapid break-up of the tear film (fluorescein tear break-up time (TBUT)) and microwounds of the ocular surface [7]. In the healthy eye, the tear film naturally ‘breaks up’ after ten seconds and the protective tear film is reformed with blinking. Available diagnostic tests often do not correlate with the severity of clinical symptoms reported by the patient. No single clinical test is considered definitive in the diagnosis of DED[1]. Therefore, multiple tests are typically used in combination and supplemented by information gathered on patient symptoms, recorded through questionnaires. These tests demand a significant amount of time and resources at the clinic. Tests for determining the physical parameters of tears include TBUT, the Schirmer’s test, tear osmolarity and tear meniscus height. Other useful tests in DED diagnosis include ocular surface staining, corneal sensibility, interblink frequency, corneal surface topography, interferometry, aberrometry and imaging techniques such as meibography and in vivo confocal microscopy (IVCM), as well as visual function tests.
artificial intelligence (AI) was defined in 1955 as “the science and engineering of making intelligent machines” [8], where intelligence is the “ability to achieve goals in a wide range of environments” [9]. Within AI, machine learning denotes a class of algorithms capable of learning from data rather than being programmed with explicit rules. AI, and particularly machine learning, is increasingly becoming an integral part of health care systems. The sub-field of machine learning known as deep learning uses deep artificial neural networks, and has gained increased attention in recent years, especially for its image and text recognition abilities. In the field of ophthalmology, deep learning has so far mainly been used in the analysis of data from the retina to segment regions of interest in images, automate diagnosis and predict disease outcomes [10]. For instance, the combination of deep learning and optical coherence tomography (OCT) technologies has allowed reliable detection of retinal diseases and improved diagnosis [11]. Machine learning also has potential for use in the diagnosis and treatment of anterior segment diseases, such as DED. Many of the tests used for DED diagnosis and follow-up rely on the experience of the observer for interpretation of images, which may be considered subjective [12]. AI tools can be used to interpret images automatically and objectively, saving time and providing consistency in diagnosis.
Several reviews have been published that discuss the application of AI in eye disease, including screening for diabetic retinopathy [13], detection of age-related macular degeneration [14] and diagnosis of retinopathy of prematurity [15]. We are, however, not aware of any review on AI in DED. In this article, we therefore provide a critical review of the use of AI systems developed within the field of DED, discuss their current use and highlight future work.
2. Artificial intelligence
AI is informational technology capable of performing activities that require intelligence. It has gained substantial popularity within the field of medicine due to its ability to solve ubiquitous medical problems, such as classification of skin cancer [16], prediction of hypoxemia during surgeries [17] and identification of diabetic retinopathy [18]. Machine learning is a sub-field of AI encompassing algorithms capable of learning from data, without being explicitly programmed. All AI systems used in the studies included in this review, fall within the class of machine learning. The process by which a machine learning algorithm learns from data is referred to as training. The outcome of the training process is a machine learning model, and the model’s output is referred to as predictions. Different learning algorithms are categorised according to the type of data they use, and referred to as supervised, unsupervised and reinforcement learning. The latter is excluded from this review, as none of the studies use it, while the two former are introduced in this section. A complete overview of the algorithms encountered in the reviewed studies is provided in Figure 1, sorted according to the categories described below.

An overview of the machine learning algorithms used in the reviewed studies.
2.1. Supervised learning
Supervised learning denotes the learning process of an algorithm using labelled data, meaning data that contains the target value for each data instance, e.g., tear film lipid layer category. The learning process involves extracting patterns linking the input variables and the target outcome. The performance of the resulting model is evaluated by letting it predict on a previously unseen data set, and comparing the predictions to the true data labels. See Section 2.5 for a brief discussion of evaluation metrics. Supervised learning algorithms can perform regression and classification, where regression involves predicting a numerical value for a data instance, and classification involves assigning data instances to predefined categories. Figure 1 contains an overview of supervised learning algorithms encountered in the reviewed studies.
2.2. Unsupervised learning
Unsupervised learning denotes the training process of an algorithm using unlabelled data, i.e. data not containing target values. The task of the learning algorithm is to find patterns or data groupings by constructing a compact representation of the data. This type of machine learning is commonly used for grouping observations together, detecting relationships between input variables, and for dimensionality reduction. As unsupervised learning data contains no labels, a measure of model performance depends on considerations outside the data [see 19, chap. 14], e.g., how the task would have been solved by someone in the real world. For clustering algorithms, similarity or dissimilarity measures such as the distance between cluster points can be used to measure performance, but whether this is relevant depends on the task [20]. Unsupervised algorithms encountered in the reviewed studies can be divided into those performing clustering and those used for dimensionality reduction, see Figure 1 for an overview.
2.3. Artificial neural networks and deep learning
Artificial neural networks are loosely inspired by the neurological networks in the biological brain, and consist of artificial neurons organised in layers. How the layers are organised within the network is referred to as its architecture. Artificial neural networks have one input layer, responsible for passing the data to the network, and one or more hidden layers. Networks with more than one hidden layer are called deep neural networks. The final layer is the output layer, providing the output of the entire network. Deep learning is a sub-field of machine learning involving training deep neural networks, which can be done both in a supervised and unsupervised manner. We encounter several deep architectures in the reviewed studies. The two more advanced types are convolutional neural networks (CNNs) and generative adversarial networks (GANs). CNN denotes the commonly used architecture for image analysis and object detection problems, named for having so-called convolutional layers that act as filters identifying relevant features in images. CNNs have gained popularity recently and all of the reviewed studies that apply CNNs were published in 2019 or later. Advanced deep learning techniques will most likely replace the established image analysis methods. This trend has been observed within other medical fields such as gastrointestinal diseases and radiology [21, 22]. A GAN is a combination of two neural networks: A generator and a discriminator competing against each other. The goal of the generator is to produce fake data similar to a set of real data. The discriminator receives both real data and the fake data from the generator, and its goal is to discriminate the two. GANs can be used i.a. to generate synthetic medical data, alleviating privacy concerns [23].
2.4. Workflow for model development and validation
The data used for developing machine learning models is ideally divided into three independent parts: A training set, a validation set and a test set. The training set is used to tune the model, the validation set to evaluate performance during training, and the test set to evaluate the final model. A more advanced form of training and validation, is k-fold cross-validation. Here, the data is split into k parts, of which one part is set aside for validation, while the model is trained on the remaining data. This is repeated k times, and each time a different part of the data is used for validation. The model performance can be calculated as the average performance for the k different models [see 19, chap. 7]. It is considered good practice to not use the test data during model development and vice versa, the model should not be tuned further once it has been evaluated on the test data [see 19, chap.7]. In cases of class imbalance, i.e., unequal number of instances from the different classes, there is a risk of developing a model that favors the prevalent class. If the data is stratified for training and testing, this might not be captured during testing. Class imbalance is common in medical data sets, as there are for instance usually more healthy than ill people in the population [24]. Whether to choose a class distribution that represents the population, a balanced or some other distribution depends on the objective. Various performance scores should regardless always be used to provide a full picture of the model’s performance.
2.5. Performance scores
In order to assess how well a machine learning model performs, its performance can be assigned a score. In supervised learning, this is based on the model’s output compared to the desired output. Here, we introduce scores used most frequently in the reviewed studies. Their definitions as well as the remaining scores used are provided in Appendix A.1. A commonly used performance score in classification is accuracy, eq. (A.3), which denotes the proportion of correctly predicted instances. Its use is inappropriate in cases of strong class imbalance, as it can reach high values if the model always predicts the prevalent class. The sensitivity, also known as recall, eq. (A.4), denotes the true positive rate. If the goal is to detect all positive instances, a high sensitivity indicates success. The precision, eq. (A.5), denotes the positive predictive value. The specificity, eq. (A.6), denotes the true negative rate, and is the negative class version of the sensitivity. The F1 score, eq. (A.7), is the harmonic mean between the sensitivity and the precision. It is not symmetric between the classes, meaning it is dependent on which class is defined as positive.
Image segmentation involves partitioning the pixels in an image into segments [25]. This can for example be used to place all pixels representing the pupil into the same segment while pixels representing the iris are placed in another segment. The identified segments can then be compared to manual annotations. Performance scores used include the Average Pompeiu-Hausdorff distance, (A.17), the Jaccard index and the support, all described in Appendix A.1.
2.6. AI regulation
Approved AI devices will be a major part of the medical service landscape in the future. Currently, many countries are actively working on releasing AI regulations for healthcare, including the European Union (EU), the United States, China, South Korea and Japan. On 21 April 2021, the EU released a proposal for a regulatory framework for AI [26]. The US Food and Drug Administration (FDA) is also working on AI legislation for healthcare [27].
In the framework proposed by the EU, AI systems are divided into the four categories low risk, minimal risk, high risk and unacceptable risk [26]. AI systems that fall into the high risk category are expected to be subject to strict requirements, including data governance, technical documentation, transparency and provision of information to users, human oversight, robustness and cyber security, and accuracy. It is highly likely that medical devices using AI will end up in the high risk category. Looking at the legislation proposals [26, 27] from an AI research perspective, it is clear that explainable AI, transparency, uncertainty assessment, robustness against adversarial attacks, high quality of data sets, proper performance assessment, continuous post-deployment monitoring, human oversight and interaction between AI systems and humans, will be major research topics for the development of AI in healthcare.
3. Methods
3.1. Search methods
A systematic literature search was performed in PubMed and Embase in the period between March 20 and May 21, 2021. The goal was to retrieve as many studies as possible applying machine learning to DED related data. The following keywords were used: All combinations of “dry eye” and “meibomian gland dysfunction” with “artificial intelligence”, “machine learning”, “computer vision”, “image recognition”, “bayesian network”, “decision tree”, “neural network”, “image based analysis”, “gradient boosting”, “gradient boosting machine” and “automatic detection”. In addition, searches for “ocular surface” combined with both “artificial intelligence” and “machine learning” were made. See also an overview of the search terms and combinations in Figure 2. No time period limitations were applied for any of the searches.

Search term combinations used in the literature search. Three of the studies found in the searches including “ocular surface” were also found among the studies in the searches including “dry eye”.
3.2. Selection criteria
The studies to include in the review had to be available in English in full-text. Studies not investigating the medical aspects of DED were excluded (e.g., other ocular diseases and cost analyses of DED). Moreover, the studies had to describe the use of a machine learning model in order to be considered. Reviews were not considered. The studies were selected in a three-step process. One review author screened the titles on the basis of the inclusion criteria. The full-texts were then retrieved and studied for relevance. The search gave 640 studies in total, of which 111 were regarded as relevant according to the selection criteria. After removing duplicates, 45 studies were left. The three-step process is shown in Figure 3a.

(a) Illustration of the three steps in the study selection process and number of studies (N) included in each step, and (b) the number of studies published over time, counting the studies included in this review.
4. Artificial intelligence in dry eye disease
4.1. Summary of the studies
Most studies were published in recent years, especially after 2014, see Figure 3b. An overview of the studies is provided in Tables 1 to 4 for the clinical, biochemical and demographical studies, respectively. Information on the data used in each study is shown in Table 5. We grouped studies according to the type of clinical test or type of study: TBUT, interferometry and slit-lamp images, IVCM, meibography, tear osmolarity, proteomics analysis, OCT, population surveys and other clinical tests. We found most studies employed machine learning for interpretation of interferometry, slit-lamp and meibography images.
Overview of the reviewed studies using clinical investigations, part 1 of 2.
Overview of the reviewed studies using clinical investigations, part 2 of 2.
Overview of the reviewed studies using biochemical investigations.
Overview of the reviewed studies using demographical investigations.
Overview of the data applied for the analyses.
4.2. Fluorescein tear break-up time
Shorter break-up time indicates an unstable tear film and higher probability of DED. Machine learning has been employed to detect dry areas in TBUT videos and estimate TBUT [12, 63, 57, 58]. Use of the Levenberg-Marquardt algorithm to detect dry areas achieved an accuracy of 91% compared to assessments by an optometrist [12]. Application of Markov random fields to label pixels based on degree of dryness was used to estimate TBUT resulting in an average difference of 2.34 seconds compared to clinician assessments [63]. Polynomial functions have also been used to determine dry areas, where threshold values were fine-tuned before estimation of TBUT [57]. This method resulted in more than 90% of the videos deviating by less than ±2.5 seconds compared to analyses done by four experts on videos not used for training [58]. Taken together, these studies indicate that TBUT values obtained using automatic methods are within an acceptable range compared to experts. However, we only found four studies, all of them including a small number of subjects. Further studies are needed to verify the findings and to test models on external data.
4.3. Interferometry and slit-lamp images
Interferometry is a useful tool that gives a snapshot of the status of the tear film lipid layer, which can be used to aid diagnosis of DED. Machine learning systems have been applied to interferometry and slit-lamp images for lipid layer classification based on morphological properties [60, 59, 55, 54, 52, 34, 35], estimation of the lipid layer thickness [50, 36], diagnosis of DED [49, 47], determination of ocular redness [61] and estimation of tear meniscus height [48, 29].
Diagnosis of DED can be based on the following morphological properties: open meshwork, closed meshwork, wave, amorphous and color fringe [74]. Most studies used these properties to automatically classify interferometer lipid layer images using machine learning. Garcia et al. used a K-nearest neighbors model trained to classify images resulting in an accuracy of 86.2% [60]. Remeseiro et al. explored various support vector machine (SVM) models for use in final classification [59, 55, 54]. In one of the studies, the same data was used for training and testing, which is not ideal [55]. Another study did not report the data their system was trained on [54]. Peteiro et al. evaluated images using five different machine learning models [52]. In this study, the amorphous property was not included as one of possible classifications, as opposed to the other studies. A simple neural network achieved the overall best performance with an accuracy of 96%. However, because leave-one-out cross validation was applied, the model may have overfitted on the training data [19]. da Cruz et al. compared six different machine learning models and found that the random forest was the best classifier, regardless of the pre-processing steps used [34, 35]. The highest performance was achieved by application of Ripley’s K function in the image pre-processing phase, and Greedy Stepwise technique used simultaneously with the machine learning models for feature selection [35]. Since all models were evaluated with cross validation, the system should be externally evaluated on new images before being considered for routine use in the clinic.
Hwang et al. investigated whether tear film lipid layer thickness can be used to distinguish meibomian gland dysfunction (MGD) severity groups [50]. Machine learning was used to estimate the thickness from Lipiscanner and slit-lamp videos with promising results. Images were pre-processed and the flood-fill algorithm and canny edge detection were applied to locate and extract the iris from the pupil. A significant difference between two MGD severity groups was detected, suggesting that the technique could be used for the evaluation of MGD. Keratograph images can also be used to determine tear film lipid layer thickness. Comparison of two different image analysis methods using a generalized linear model showed that there was a high correlation between the two techniques [36]. The authors concluded that the simple technique was sufficient for evaluation of tear film lipid layer thickness. However, only 28 subjects were included in the study.
The use of fractal dimension estimation techniques was investigated for feature extraction from interferometer videos for diagnosis of DED [49]. The technique was found to be fast and had an area under the receiver operating characteristic curve (AUC) value of 0.786, compared to a value of 0.824 for an established method (See Appendix A.1 and figure A.4a for a description of the receiver operating characteristic curve). Tear film lipid interferometer images were analysed using an SVM [47]. Extracted features from the images were passed to the SVM model, which classified the images as either healthy, aqueous-deficient DED, or evaporative DED. The agreement between the model and a trained ophthalmologist was high, with a reported Kappa value of 0.82. The model performed best when detecting aqueous-deficient DED.
Ocular redness is an important indicator of dry eyes. Only one of the reviewed studies described an automated system for evaluation of ocular redness associated with DED [61]. Slit-lamp images were acquired from 26 subjects with a history of DED. Features representing the ocular redness intensity and horizontal vascular component were extracted with a Sobel operator. A multiple linear regression model was trained to predict ocular redness based on the extracted features. The system achieved an accuracy of 100%. The authors suggested that an objective system like this could replace subjective gradings by clinicians in multicentered clinical studies.
The tear meniscus contains 75 – 90% of the aqueous tear volume [75]. Consequently, the tear meniscus height can be used as a quantitative indicator for DED caused by aqueous deficiency. When connected component labelling was applied to slit-lamp images, the Pearson’s correlation between the predicted meniscus heights and an established software methodology (ImageJ [76]) was high, ranging between 0.626 and 0.847 [48]. The machine learning system was found to be more accurate than four experienced ophthalmologists. The tear meniscus height can also be estimated from keratography images using a CNN [29]. The automatic machine learning system achieved an accuracy of 82.5% and was found to be more effective and consistent than a well-trained clinician working with limited time.
Many of the studies apply SVM as their type of machine learning model without testing how other machine learning models perform. However, three of the studies tested several types of models and found that SVM did not perform the best [52, 34, 35]. It is difficult to compare the studies due to different applications and evaluation metrics. Despite promising results, most of the studies [60, 59, 55, 52, 34, 35, 50, 36, 49, 61, 48] did not evaluate their systems on external data. The systems should be tested on independent data before they can be considered for clinical application. Moreover, some studies were small [61, 36] or pilots [48, 29], and the suggested models should be tested on a larger number of subjects.
4.4. In vivo confocal microscopy
IVCM is a valuable non-invasive tool used to examine the corneal nerves and other features of the cornea [77]. IVCM images were used in a small study to assess characteristics of the corneal subbasal nerve plexus for diagnosis of DED [42]. Application of random forest and a deep neural network [43] gave promising results with an AUC value of 0.828 for detecting DED [42]. IVCM images of corneal nerves can also be analyzed by machine learning models to estimate the length of the nerve fiber [41]. Authors used a CNN with a U-net architecture that had been pre-trained on more than 5, 000 IVCM images of corneal nerves. The model showed that nerve fiber length was significantly longer after intense pulsed light treatment in MGD patients, which agreed with manual annotations from an experienced investigator with an AUC value of 0.96 and a sensitivity of 0.96. High-resolution IVCM images were also used to detect obstructive MGD [38]. Combinations of nine different CNNs were trained and tested on the images using 5-fold cross validation. Classification by the models was compared to diagnosis made by three eyelid specialists. The best performance was achieved when four different models were combined, with high sensitivity, specificity and AUC values, see Table 1. These promising results suggest that CNNs can be useful for detection and evaluation of MGD. Deep learning methods such as CNNs have the advantage that feature extraction from the images prior to analysis is not required as this is performed automatically by the model.
IVCM images have been investigated for changes in immune cells across different severities of DED for diagnostic purposes [28]. A generalized linear model showed significant differences in dendritic cell density and morphology between DED patients and healthy individuals, but not between the different DED subgroups, see Table 1. While results using machine learning to interpret IVCM images are promising, larger clinical studies are needed to validate findings before clinical use can be considered.
4.5. Meibography
The meibomian glands are responsible for producing meibum, important for protecting the tear fluid from evaporation. Reduced secretion of meibum due to a reduced number of functional meibomian glands and/or obstruction of the ducts is a major cause of evaporative DED and MGD. Classification of meibomian glands using meibography is routine for experienced experts, but this is not the case for all clinicians. Moreover, automatic methods can be faster than human assessment.
Meibography images may require several pre-processing steps before they can be classified. One study trained an SVM on extracted features from the images [62]. Pre-processing included the dilation, flood-fill, skeletonization and pruning algorithms. The model achieved a sensitivity of 0.979 and specificity of 0.961. However, in contrast to all other image analysis methods, this method is not completely automatic as the images need to be manipulated manually before they are passed on to the system.
A combination of Otsu’s method and the skeletonization and watershed algorithms was useful in automatically quantifying meibomian glands [53]. This method was faster than an ophthalmologist and achieved a sensitivity and specificity of 0.993 and 0.975, respectively. Another automatic method applied Bézier curve fitting as part of the analysis [51]. The reported sensitivity was 1.0, while the specificity was 0.98. Xiao et al. sequentially applied a Prewitt operator, Graham scan, fragmentation and skeletonization algorithms for image analysis to quantify meibomian glands [32]. The agreement between the model results and two ophthalmologists was high with Kappa values larger than 0.8 and low false positive rates (< 0.06). The false negative rate was 0.19, suggesting that some glands were missed by the method. A considerable weakness of this study was that only 15 images were used for model development, and consequently it might not work well on unseen data. Another study automatically graded MGD severity using a Sobel operator, polynomial functions, fragmentation algorithm and Otsu’s method [45]. While the method was found to be faster, the results were significantly different from clinician assessments.
Deep learning approaches were used by four studies evaluating meibomian gland features [46, 39, 33, 31]. These systems are fully automated and apply some of the latest technologies within image analysis. Wang et al. used four different CNNs to determine meibomian gland atrophy [46]. The CNNs were trained to identify meibomian gland drop-out areas and estimate the percentage atrophy in a set of images. Comparison of model predictions with experienced clinicians indicated that the best CNN (ResNet50 architecture) was superior. Yeh et al. developed a method to evaluate meibomian gland atrophy by extracting features from meibography images with a special type of unsupervised CNN before application of a K-nearest neighbors model to allocate a meiboscore [33]. The system achieved an accuracy of 80.9%, outperforming annotations by the clinical team. Moreover, hierarchical clustering of the extracted features from the CNN could show relationships between meibography images. Another study used a CNN to automatically assess meibomian gland characteristics [39]. Images from two different devices collected from various hospitals were used to train and evaluate the CNN. This is an example of uncommonly good practice, as most medical AI systems are developed and evaluated on data from only one device and/or hospital. The only study to use a GAN architecture tested it on infrared 3D images of meibomian glands in order to evaluate MGD [31]. Comparing the model output with true labels, the performance scores were better than for state of the art segmentation methods. The Pearson correlations between the new automated method and two clinicians were 0.962 and 0.968.
Four of the studies did not evaluate their proposed systems on external data [53, 51, 45, 32]. Since the number of images used for model development was limited, the models can have overfit, and external evaluations should be performed to test how well the systems generalize to new data.
4.6. Tear osmolarity
Tear osmolarity is a measure of tear concentration, and high values can indicate dry eyes. Cartes et al. [65] investigated use of machine learning to detect DED based on this test. Four different machine learning models were compared. Noise was added to osmolarity measurements during the training phase, while original data without noise was used for final evaluation. The logistic regression model achieved 85% accuracy. However, since the models were trained and tested on the same data, the reported score is most likely not representative for how well the model generalizes to new data.
4.7. Proteomic analysis
Proteomic analysis describes the qualitative and quantitative composition of proteins present in a sample. Grus et al. compared tear proteins in individuals with diabetic DED, non-diabetic DED and healthy controls for discrimination between the groups [70]. The authors used discriminant analysis and principal component analysis combined with k-means clustering. Both models achieved low accuracies when predicting all three categories. However, classification into DED and non-DED achieved accuracies of 72% and 71% for discriminant analysis and k-means clustering, respectively. In another study by the same group, tear proteins analyzed using deep learning discriminated subjects as healthy or having DED with an accuracy of 89% [69]. An accuracy of 71% was achieved using discriminant analysis. A combination of discriminant analysis for detecting the most important proteins and a deep neural network for classification was also investigated [68]. High accuracy, sensitivity and specificity were reported. Discriminant analysis was also used by Gonzalez et al. in analysis of the tear proteome [67]. The most important proteins were selected to train an artificial neural network to classify tear samples as aqueous-deficient DED, MGD or healthy. The model gave an overall accuracy of 89.3%. Principal component analysis yielded good separation of healthy controls, aqueous-deficient DED and MGD data-points, indicating that the proteins were good candidates for classification of the three conditions. This system achieved the highest accuracy of all the reviewed proteomic studies. Considered together, the results from the four studies [70, 69, 68, 67] suggest that neural networks applied alone or together with other techniques perform better than discriminant analysis for detecting DED-related protein patterns in the tear proteome.
Jung et al. used a network model based on modularity analysis to describe the tear proteome with respect to immunological and inflammatory responses related to DED [66]. In this study, patterns in tears and lacrimal fluid were investigated in patients with DED. Since only 10 subjects were included, the study should be performed on a larger cohort of patients to verify the results.
4.8. Optical coherence tomography
Thickening of the corneal epithelium can be a sign of abnormalities in the cornea. Moreover, corneal thickness could potentially be a marker for DED. Kanellopoulos et al. developed a linear regression model to look for possible correlations between corneal thickness metrics measured using anterior segment optical coherence tomography (AS-OCT) and DED [56]. However, neither the model predictions nor performance were reported, making it difficult to assess the usefulness of the study. The type of instrument used to determine the corneal thickness was found to affect the results [37]. Measurements from AS-OCT and Pentacam were compared and multivariable regression was used to detect differences between the two techniques regarding the measured central corneal thickness and the thinnest corneal thickness. Individuals with mild DED, severe DED and healthy subjects were examined. The two techniques gave significantly different results in terms of the resulting β-coefficients in the multivariable regression model for individuals with severe DED. Images from clinical examinations with AS-OCT were used to diagnose DED [30]. A pretrained VGG19 CNN [78] was fine-tuned using separate images for training and validation. Two similar CNN models were developed, and evaluation was performed on an external test set. Both achieved impressively high performance scores. The AUC values were 0.99 and 0.98. This is one out of two studies in this review that used an independent test sets after model development. Such practice is essential for a realistic impression of how well the model generalizes to new data not used during model development. The good performance is likely linked to the large amounts of training data (29, 000 images), which is essential for deep learning methods. Most of the reviewed studies use significantly smaller data sets, which constitutes a disadvantage. Stegmann et al. analysed OCT images from healthy subjects for automatic detection of the lower tear meniscus [40]. Two different CNNs were trained and evaluated using 5-fold cross validation. The tear menisci detected by the models were compared to evaluations from an experienced grader. The best CNN achieved an average accuracy of 99.95%, sensitivity of 0.9636 and specificity of 0.9998. The system is promising regarding fast and accurate segmentation of OCT images. However, more images from different OCT systems, including non-healthy subjects, should be used to verify and improve the analysis.
The two studies [78, 40] showed that CNNs could be an appropriate tool for image analysis. CNNs are likely to increase in popularity within the field of DED due to promising results for solving image related tasks, including feature extraction.
4.9. Other clinical tests
Machine learning models were used to analyse results from a variety of clinical tests to expand understanding of the DED process [64]. The study included subjects with DED and healthy subjects. Subjective cutoff values from clinical tests were used to assign subjects to the DED class. Hierarchical clustering and a decision tree were applied sequentially to group the subjects based on their clinical test results. The resulting groups were compared to the original groups. Because the analysis was based on objective measurements, it could be used to develop more objective diagnostic criteria. This could lead to earlier detection and more effective treatment of DED.
4.10. Population surveys
Population surveys can provide valuable insight regarding the prevalence of DED and help detect risk factors for developing the disease. Japanese visual terminal display workers were surveyed with the objective of detecting DED [73]. Dry eye exam data and subjective reports were used for diagnosis. This was passed to a discriminant analysis model. When compared to diagnosis by a dry eye specialist, the model showed a high sensitivity of 0.931, but low specificity of 0.437. This is a very low specificity, but is not necessarily bad if the aim is to detect as many cases of DED as possible and there is less concern about misclassification of healthy individuals. Data from a national health survey were analysed in order to detect risk factors for DED [72]. Here, individuals were regarded as having DED if they had been diagnosed by an ophthalmologist, and were experiencing dryness. Feature modifications were performed by a decision tree, and the most important features were selected using lasso. β-coefficients from a logistic regression trained on the most important features were used to rank the features. Women, individuals who had received refractive surgery and those with depression were detected as having the highest risk for developing DED. Even though the models in the study were trained on data from more than 3500 participants, the reported performance scores were among the poorest in this review with a sensitivity of 0.66 and a specificity of 0.68. A possible reason could be that the selected features were not ideal for detecting DED. However, the detected risk factors have previously been shown to be associated with DED [3, 79, 80]. The findings suggest that the data quality from population surveys might not be as high as in other types of studies, which could lead to misinterpretation by the machine learning model.
The association between DED and dyslipidemia was investigated by combining data from two population surveys in Korea in [71]. A generalized linear model was used to investigate linear characteristics between features and the severity of DED. The model showed significant increase in age, blood pressure and prevalence of hypercholesterolemia over the range from no DED to severe DED. Evaluation of the association between dyslipidemia and DED using linear regression showed that the odds ratio for men with dyslipidemia was higher than 1 compared to men without dyslipidemia. This association was not found in women. The study results suggest a positive association between DED and dyslipidemia in men, but not in women.
4.11. Future perspectives
In order to benchmark existing and future models, we advocate that the field of DED should have a common, centralized and openly available data set for testing and evaluation. The data should be fully representative for the relevant clinical tests. In order to ensure that models are applicable to all populations of patients, medical institutions, and types of equipment around the world, they must be evaluated on data from different demographic groups of patients across several clinics and, if relevant, from different medical devices. Moreover, the test data set should not be available for model development, but only for final evaluation. A common standard on these processes will increase the reproducibility and comparability of studies. In addition, a cross hospitals/centers data set would solve important challenges of applying AI in clinical practice, such as metrics not reflecting clinical applicability, difficulties in comparing algorithms, and underspecification. These have all been identified as being among the main obstacles for adoption of any medical AI system in clinical practice [81, 82].
A possible challenge regarding implementation in the clinic is that hospitals do not necessarily use the same data platforms, which might prevent widespread use of machine learning systems. Consequently, solutions for implementing digital applications across hospitals should be considered.
Model explanations are important in order to understand why a complex machine learning model produces a certain prediction. For healthcare providers to trust the systems and decide to use them in the clinic, the systems should provide understandable and sound explanations of the decision-making process. Moreover, they could assist clinicians when making medical decisions [17]. When developing new machine learning systems within DED, effort should be made to present the workings of the resulting models and their predictions in an easy to interpret fashion.
5. Conclusions
We observed a large variation in the type of clinical tests and the type of data used in the reviewed studies. This is also true regarding the extent of pre-processing applied to the data before passing it to the machine learning models. The studies analysing images can be divided into those applying deep learning techniques directly on the images, and those performing extensive pre-processing and feature extraction before the data is passed to the machine learning model in a tabular format. The number of studies belonging to the first group has increased significantly over the past 3 years. As deep learning techniques become more established, these will probably replace more traditional image pre-processing and feature extraction techniques.
We noted that there was a lack of consensus regarding how best to perform model development, including evaluation. This made it difficult to estimate how well some models will perform in the clinic and with new patients, and also to compare the different models. Comparison was further complicated by the use of different types of performance scores. In addition there was no culture of data and code sharing, which makes reproducibility of the results impossible. For the future, focus should be put on establishing data and code sharing as a standard procedure.
In conclusion, the results from the different studies’ machine learning models are promising, although much work is still needed on model development, clinical testing and standardisation. AI has a high potential for use in many different applications related to DED, including automatic detection and classification of DED, investigation of the etiology and risk factors for DED, and in the detection of potential biomarkers. Effort should be made to create common guidelines for the model development process, especially regarding model evaluation. Prospective testing is recommended in order to evaluate whether proposed models can improve the diagnostics of DED, and the health and quality of life of patients with DED.
Data Availability
Analysed data is provided in the manuscript.
Disclosure
The authors report no conflicts of interest.
A. Supporting information
A.1. Performance scores used
If there are two categories available, the task is referred to as binary classification, while more than two categories is referred to as multi-class. For binary classification, the true outcome belongs to one of two categories, e.g., healthy or ill, often referred to as positive (P) or negative (N). A binary classifier assigns new data instances to these two categories, and the prediction can be either true (T), meaning correct, or false (F), meaning incorrect. The outcome can then belong to one of the four categories true positive (TP), true negative (TN), false positive (FP) and false negative (FN), and sum to the total number of instances in the data set. From these, we can calculate a variety of performance scores, some of which are listed in Section 2.5. We provide mathematical expression for these below. The remaining performance scores encountered in the reviewed studies are outlined after.


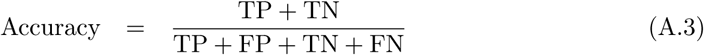



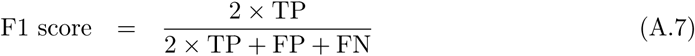

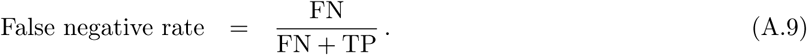
Although binary classification tasks involve assigning instances to one of two classes, e.g., 0 and 1, most machine learning classifiers can output the distance of an instance to the decision boundary, i.e., a decimal number in the interval [0, 1]. A common interpretation of this number is class probability or classification confidence, meaning that an output close to either number indicates a confident classification, while an output closer to the classification threshold indicates that the classifier is not capable of assigning the instance to a class. The classification threshold is thus the numerical value that separates the two classes, and the confusion matrix entries vary with this threshold. Unless otherwise specified, its value is usually 0.5. Here, we introduce two metrics that can be constructed by varying this threshold from 0 to 1. First, the receiver operating characteristic curve is constructed from the curves of the true and false positive rates obtained by varying the classification threshold. Optimally, the true positive rate is 1 for any threshold, while a classifier which always guesses randomly produces a diagonal line, as shown in Figure A.4a. The AUC value is calculated by summing the area under the receiver operating characteristic curve, and its maximum value is 1.

There is a trade-off between the precision and sensitivity: A high precision minimizes the false positives, which might result in missing positive instances, while a high sensitivity minimizes the false negatives, which can result in a increased number of false alarms. Which one should be prioritised depends on the problem at hand, and a study prioritising or reporting only one of these should argue why. The precision and the sensitivity are visualised in Figure A.4b, which highlights the trade-off between the two. They can be combined into a single number, by plotting them against each other for different classification threshold values and calculating the area under the resulting so-called precision-recall curve.
Pearson’s correlation coefficient measures the linear correlation between two data sets, and is calculated as
 where r is the Pearson’s correlation coefficient, xi and yi are the observed values in each data set and
where r is the Pearson’s correlation coefficient, xi and yi are the observed values in each data set and 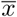 and
and  are the mean values for each data set. The value ranges from −1 to 1, where −1 indicates perfect negative linear correlation and 1 perfect positive linear correlation, while 0 indicates no linear correlation between the data. For binary classification, Pearson’s correlation coefficient takes on a simple form, referred to as Matthews correlation coefficient [83]. It measures the correlation between the true and predicted class instances, and ranges from −1 to 1. Here, 0 indicates that the classifier guesses randomly, and 1 and −1 indicate complete agreement and disagreement, respectively, between the model predictions and the true outcome. It can be calculated from the confusion matrix entries as
are the mean values for each data set. The value ranges from −1 to 1, where −1 indicates perfect negative linear correlation and 1 perfect positive linear correlation, while 0 indicates no linear correlation between the data. For binary classification, Pearson’s correlation coefficient takes on a simple form, referred to as Matthews correlation coefficient [83]. It measures the correlation between the true and predicted class instances, and ranges from −1 to 1. Here, 0 indicates that the classifier guesses randomly, and 1 and −1 indicate complete agreement and disagreement, respectively, between the model predictions and the true outcome. It can be calculated from the confusion matrix entries as

The concordance correlation coefficient measures the agreement between two data sets by measuring the variation around the 45 degrees concordance line through the origin [84]. The value ranges between 1 and −1. When the two data sets share mean and standard deviation, the concordance correlation coefficient equals the Pearsons’s correlation coefficient. In all other cases, the concordance correlation coefficient will be lower than the Pearson’s correlation coefficient. The value is calculated as
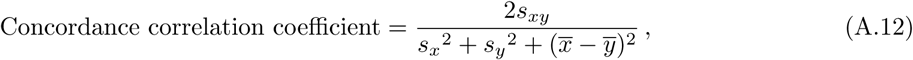 where
where  and
and 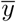 are the mean values of the two data sets x and y, sx2 and sy2 are the variances for each data set and sxy2 is the covariance between the data sets [84].
are the mean values of the two data sets x and y, sx2 and sy2 are the variances for each data set and sxy2 is the covariance between the data sets [84].
Root mean squared error is commonly used for regression problems and represents the difference between the model predictions and the observed values. The value is calculated as
 where n is the number of instances in the data set and ŷi and yi is the model prediction and observed value for instance i, respectively.
where n is the number of instances in the data set and ŷi and yi is the model prediction and observed value for instance i, respectively.
The Kappa index measures the agreement between two raters, e.g., the model predictions and labels during classification [85]. It is calculated as
 where po is the observed probability of agreement, which equals the accuracy defined in eq. (A.3), and pe is the expected probability of agreement due to chance, defined as
where po is the observed probability of agreement, which equals the accuracy defined in eq. (A.3), and pe is the expected probability of agreement due to chance, defined as
 where Total is the total number of instances. The highest possible value is 1, representing perfect agreement, and values above 0.8 are typically regarded as excellent [85]. An illustration of the κ index values for the proportion of correct model predictions is provided in Figure A.5.
where Total is the total number of instances. The highest possible value is 1, representing perfect agreement, and values above 0.8 are typically regarded as excellent [85]. An illustration of the κ index values for the proportion of correct model predictions is provided in Figure A.5.

Cramér’s V measures the association between two categorical variables that belong to more than two categories each. When there are two categories for each variable, Cramér’s V equals the ϕ coefficient [87]. It is calculated via
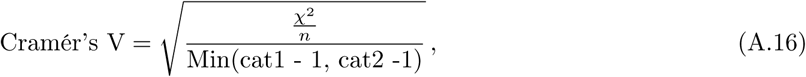 where χ2 is the usual chi-squared statistic, n is the number of instances, and cat1 and cat2 are the number of possible categories for each variable. The value ranges from 0 to 1, representing no and perfect correlation between the variables, respectively [88].
where χ2 is the usual chi-squared statistic, n is the number of instances, and cat1 and cat2 are the number of possible categories for each variable. The value ranges from 0 to 1, representing no and perfect correlation between the variables, respectively [88].
In hypothesis testing, the p-value is the probability under a specific model of obtaining test results at least as extreme as those observed, under the assumption that the null hypothesis H0 is true. H0 is commonly defined as no difference between two data sets, while the alternate hypothesis Ha states that there is a difference. Consequently, a low p-value indicates that the result is not likely under the null hypothesis, and thus strengthens the belief in Ha [89].
The Average Pompeiu-Hausdorff distance reflects the distance between estimated values and true values in a metric space [90]. Lower values imply small differences between the two metric spaces. The Pompieu-Hausdorff distance H between the subsets a and b is calculated via

The aggregated Jaccard index is an extension of the global Jaccard index also used to measure the similarities between two sample sets [91]. A high value indicates small differences between the sample sets. The calculation of the aggregated Jaccard index is described by Kumar et al. [92], and Figure A.6 shows a visualisation. For image segmentation, the support for a segmented area can be calculated as the number of pixels in the segmented area divided by the number of background pixels [40].

A visual representation of the Jaccard index. FN = False Negative; TN = True Negative; TP = True Positive; FP = False Positive; Jacc = Jaccard index.
A.2. Measuring model uncertainty
Uncertainty estimates are useful in order to evaluate how certain a machine learning model is about the predictions. High uncertainty might suggest that a human expert also should have a look at the instance [93]. Among the reviewed studies, some choose not to use the model predictions of DED when the predicted probabilities are too close to 0.5, reflecting that the model is uncertain [73]. Others report the standard deviation of the model performance scores [12, 34, 35, 62, 32, 33, 40, 47, 61]. Some computes the confidence intervals for the model performance scores [30, 37, 72, 61, 61]. A comprehensive discussion about quantifying uncertainty for medical machine learning models can be found in [93].
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].↵
- [72].↵
- [73].↵
- [74].↵
- [75].↵
- [76].↵
- [77].↵
- [78].↵
- [79].↵
- [80].↵
- [81].↵
- [82].↵
- [83].↵
- [84].↵
- [85].↵
- [86].↵
- [87].↵
- [88].↵
- [89].↵
- [90].↵
- [91].↵
- [92].↵
- [93].↵




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}