
ABSTRACT
Introduction From the beginning of the COVID-19 pandemic, epidemiological models have been used in a number of ways to aid governments and organizations in efficient planning of resources and decision making. These models have elucidated important epidemiological transmission parameters, in addition to making short-term projections.
Methods We constructed a compartmental mathematical model for the transmission, detection and prevention of SARS-CoV-2 infections for regions where Anglo American has mining operations. We fitted the model to publicly available data and used it to make short-term projections. Finally, we evaluated how the model performed by comparing short-term projections to actual confirmed cases, retrospectively.
Findings The average forecast errors for four-week-ahead projections ranged between 1% and 8% in all the countries and regions considered in this study. All but one region had more than 75% of the true values falling within the range of four-week-ahead projections. The quality of the projections improved with time as expected due to increased historical data.
Conclusion Our model produced four-week forecasts with a sufficiently high level of accuracy to guide operational and strategic planning for business continuity and COVID-19 responses in Anglo American mining sites.
Introduction
Since December 2019, the COVID-19 pandemic has done untold damage to the health of individuals, healthcare systems, and economies across the world. As of 23 August 2021, the WHO estimated over 211 million confirmed cases and 4.4 million deaths1. These numbers continue to compound daily as more infectious variants of the SARS-CoV-2 virus spread rapidly through populations. Thus, countries across the world have adopted different measures to mitigate the spread of infection, and prevent an overload of the health care systems. A variety of non-pharmaceutical interventions (NPIs) that have been proposed and used encompass travel bans, domestic movement restrictions, social distancing, contact tracing of infected cases, self-isolation of symptomatic people, mandatory use of face-masks in public, and shielding of high-risk populations. Vaccines have been rolled out rapidly over the past 8 months, but vaccine coverage remains highly unequal across countries, with poorer countries in the global South lagging far behind2.
From the beginning of the pandemic, epidemiological models have been used in a number of ways to aid governments and organizations in efficient planning of resources and decision making3,4. They have been instrumental in the comparison of the relative impacts of different interventions (e.g. social distancing, restrictions on air travel, school closures, use of face masks, etc.), on the trajectory of the epidemic3,5–10. More recently, models have explored a wide range of biological and behavioural aspects of COVID-19 vaccination programmes, including vaccine efficacy, emerging variants, social determinants of vaccine access and uptake, waning immunity, and changes in behaviour due to vaccination impact11–15. Models have elucidated important epidemiological transmission parameters, and have produced short-term projections of cases, hospitalizations, and deaths that can be expected in different populations16–19.
Despite the usefulness of epidemiological models, it can be difficult to make accurate predictions20,21. Forecasting relies on the use of accurate data about the population for which it is making projections in order to calibrate the model16. Some problems modellers face with regard to data quality range from under-diagnosis of COVID-19 cases, and delays in reporting of case counts, hospitalizations, and deaths21. Moreover, it can be difficult to gain access to key data such as average duration of infection and length of stay in hospital for the populations being studied. There is also a trade-off to be made between having too simplistic and too complex models. If you have models that are overly simple, the predictions may be invalid because they have not captured the full dynamics of biology (e.g. virus evolution) and behaviour of individuals in a population (e.g. societal norms changing through time in regards to mask wearing). When models are too complex, they may become overly sensitive to small changes in parameters that are context-specific and difficult to estimate accurately16.
COVID-19 models, in particular, have problems with non-identifiability. Since there is still a paucity of publicly available data to calibrate models to, modellers tend to fit their data to confirmed cases and deaths only. The problem with this, is that there are many combinations of parameters that can produce a good fit to the data, yet have drastically different projected results22,23. Thus, it is often difficult to know if predictions are accurate, even if the model fits the available data well.
We constructed a mathematical model to assist Anglo American – a leading multinational mining company with operations in over 50 countries in the world and over 90 000 permanent employees worldwide24 –with their efforts to minimize the spread of COVID-19 among their workforce. We developed separate spatially homogeneous models for countries where Anglo American has most of their mining operations - Brazil, Peru, Chile, and South Africa. Additionally, we also constructed separate models for three South African provinces: Limpopo, Northern Cape and North West. The models were calibrated to publicly available data on laboratory-confirmed SARS-CoV-2 infections and deaths in these regions, and then four-week projections were made. Our primary objective here was to evaluate how the model performed when comparing short-term projections to actual confirmed cases, retrospectively.
Methods
Model structure and flow
We developed a compartmental model for the transmission and detection of SARS-CoV-2 infections. Figure 1 shows the health states and possible transitions between them. The model assumes that all people except for the seed infections are initially susceptible to SARS-CoV-2 infection. Upon infection, they transition to become “Exposed (Eu)” but not yet infectious and not yet symptomatic. After a few days, they transition to the pre-symptomatic state (I1u) during which they are still asymptomatic, but now infectious, albeit less than during the next state of infection. From the pre-symptomatic state they may transition to either I2u, Imu or Isu. In these three states, they are respectively asymptomatic, mildly symptomatic, or severely symptomatic and very ill. People in the former two states will recover without needing hospital care. Severely ill patients, however, will either die (Ds) before they reach a hospital, or they will be hospitalised (H). Diagnosis of SARS-CoV-2 infection can happen while in any of the infection states, but is more likely for symptomatic and severely symptomatic patients - in the absence of a contact tracing programme. Three events may occur among hospitalised patients: they may recover and be discharged (Rh), they may die (Dh) or they may require an admission to a critical care unit (C). The rate of hospitalisation and admission to critical care is not capped. People may leave the critical care unit either because they die (Dc) or they are moved into a Post Critical care hospital (P) ward, from which they will transition to the recovered state (Rc). The model is formally represented by a system of differential equations, given in the Supplementary information section at the end of this article.

Schematic diagram of the disease transmission model. The capital letters represent different health states and the arrows represent transitions between the states. The letters above the arrows represents the rates of the transitions.
Data
The model was calibrated to publicly available data (which we refer to as target features) on case counts and deaths. For the general South African population, and the South African provinces (Limpopo, Northern Cape and North West), we used data reported by the National Institute for Communicable Diseases (NICD) and the South African National Department of Health (DoH). The dataset was collated by the Data Science for Social Impact research group at the University of Pretoria25. For all the other regions (Brazil, Chile, Peru), we used data from Johns Hopkins University (JHU) Center for Systems Science and Engineering (CSSE) Github repository26. To ensure data consistency and quality, we compared these public data with data reported by Woldometer27.
Model parameterization and calibration
Model parameters were informed by various epidemiological studies that estimated quantities (e.g. rmu; time from onset of symptoms to recovery for mildly symptomatic cases) based upon COVID-19 outbreaks in their respective populations. Most studies presented point estimates in the form of means and standard deviations or medians and inter-quartile ranges. Thus, we derived the bounds of the parameters’ prior distributions based upon descriptions of the spread of data around these point estimates. For some parameters (e.g. rmd; time from diagnosis to recovery for mildly symptomatic cases), we did not have access to studies that directly quantified these particular parameters, and thus we made educated assumptions based on the priors for other parameters (e.g. rmu and dm). Table 3 in the Supplementary information section at the end of this report shows the model parameters and table 4 gives a brief description of the parameters. The first seven parameters determine the effective contact rate between people susceptible to SARS-CoV-2 infection and people who are infected and infectious (in compartments I1*, I2*, Im* or Is*), taking into account the seasonal variation in effective contact rates (bb). All the other parameters (excluding hceil and cceil) determine the rate at which people transition between the health states in the model, as illustrated in Figure 1. Parameters hceil and cceil represent limits of the hospital and critical care capacity. For this modelling exercise, we kept the hospital and critical care limits uncapped by setting very large values for these two parameters. All these parameters drive the model’s features (i.e. cumulatively diagnosed SARS-CoV-2 infections and cumulative COVID-19 related deaths).
Informally, model calibration can be thought of as the process of searching for parameter values that produce model features that match the target features. We conducted a two-step calibration process. The first step involved manually adjusting the model parameters and then visually investigating the model fit. The second step involved using the model parameters from the first step and then applying a simple accept / reject Approximate Bayesian Computation scheme28. Sampling from the parameters’ prior distributions (a mix of unconditional uniform distributions and conditional distributions), the method filters through the explored parameter space and only retains parameter combinations that produce model features close to the target features. The distance between model features and target features was quantified by the relative Root-Mean-Squared-Error (RMSE), where the error terms were calculated by comparing the empirically observed time series of cumulatively diagnosed COVID-19 infections and cumulative deaths against the equivalent time series produced by the model. All time series of cumulative counts were rescaled by dividing all entries in the time series by the last (i.e. highest) value of the observed cumulative count. Due to high COVID-19 mortality underreporting that has been experienced in many regions29, we decided to give the our target features different weights during the calibration process. The cumulative cases time series was given a weight of 1 for all the regions. For the deaths time series, South Africa, Brazil, Peru, Chile and Limpopo were given a weight of 0.5 while Northern Cape and North West were given a weight of 0 (meaning that the model was not fitted to the deaths time series in these regions).
A total of one million parameter combinations were sampled from the prior distribution, and applied a tolerance threshold for the RMSE of 0.05. Thus, parameter combinations were retained if their associated model features stayed within 5% from the target features on average. We then narrowed down to get a more precisely calibrated model by setting the tolerance threshold for the RMSE at 0.001 and increasing this tolerance by 0.001 sequentially until at least forty parameter combinations were retained. The calibration scheme produced a posterior distribution for the parameters, consisting of multiple parameter combinations. This calibrated model was then used to generate projections of the number of COVID-19 deaths, active cases (stratified by severity), diagnosed and undiagnosed cases as well as the number of hospitalisations. In this paper, we only focus on projected COVID-19 cases. The model was re-calibrated once every month and the model projections updated.
Model evaluation
We evaluated the performance of the model in making short term projections using frequently used summary metrics discussed below. To assess the difference between the model projections and the observed case counts, we computed the mean absolute percentage error (MAPE), a summary measure of the accuracy of forecasts. It expresses the error in the forecasts as a percentage. MAPE is defined as:
 where yt and ŷt denote the truth and the projected value at time t respectively, and n is the number of projections. The smaller the MAPE, the better.
where yt and ŷt denote the truth and the projected value at time t respectively, and n is the number of projections. The smaller the MAPE, the better.
To measure the of sharpness of the model, defined as the ability of the model to generate predictions within a narrow range of possible values, we used the median absolute deviation (MAD). MAD is a common statistic used to measure the spread out of a set of data. It is a property of the projections only and is defined as:
 where ŷit denotes the projected value from each calibration at time t. A small MAD value means that the model is sharp while a large value means that the model is blurred.
where ŷit denotes the projected value from each calibration at time t. A small MAD value means that the model is sharp while a large value means that the model is blurred.
We also computed the percentage of true values contained in the interquartile range and those contained between the range of all projections (between the minimum and maximum projections).
Results
COVID-19 projections
The calibrated models produced projections of cumulative cases of COVID-19. For all the regions, we conducted four-week ahead forecasts. Figure 2 shows the observed and predicted COVID-19 cases together with prediction intervals for different regions for each prediction period.

Cumulative COVID-19 confirmed cases together with forecasts and prediction intervals for different regions and origins (five time points) from September 2020 to January 2021. The red lines indicate the observed data and the blue lines indicate the projected mean cumulative cases. The shaded area indicates the minimum and maximum range.
The first forecast period covered September 9 - October 6, 2020. The average forecasts for South Africa and Limpopo were very close to the observed data and the range of projections produced were narrow. During the second and third forecast periods covering October 14 - November 10, 2020 and November 4 - December 2, 2020 respectively, the actual number of confirmed COVID-19 cases were contained in the prediction intervals in most of the regions. The prediction intervals were generally narrow as well. The model performed poorly in predicting a new wave of infection as seen in the case of South Africa during the fourth forecast period which covered December 14 - January 11, 2021. The model failed to accurately predict the increase in cases during the second wave of infections in December as seen in the plots for South Africa, Limpopo, Northern Cape and North West. The fifth forecast period covered January 13 - February 9, 2021. During this forecast period, the actual number of confirmed COVID-19 cases were contained in the prediction intervals in all of the regions. However, in some regions such as Chile and Limpopo, the mean estimates for the confirmed cases were far from the observed cases.
Model evaluation
Figure 3 shows the overall model performance for difference regions. In all the regions, the forecast error increased as the forecast horizon increased. Nevertheless, the overall percentage forecast error for the four-week-ahead forecast was below 5% in all the regions besides Limpopo and Northern Cape. At one-week-ahead, most models had between 40% and 60% of the true values contained in the interquartile range. Peru had 100% of the true values contained in the interquartile range for one-week-ahead forecasts while Chile had the least number of true values falling within the interquartile range (35%). In most of the regions, the percentage of true values contained in the interquartile range decreased with time. All the regions had 60% or more of the true values falling within the range of model projections for the four-week-ahead projections. Brazil’s model was the most blurred model because it had the largest median absolute deviation values across the forecast horizon. This model exhibited rapid decrease in sharpness as the forecast horizon increased. Table 1 in the supplementary information section provides more information on overall performance of the model.

Overall model performance for the four week ahead forecasts across different regions.
Next, we analysed the model performance at different calibration time points for all the regions (Figure 4). The percentage forecast error for all the regions and all calibration time points was below 22%. In the first three rounds of forecasts, the forecast error was decreasing with time but then started increasing due to the second wave of infections. The percentage of true values contained in the interquartile range do not seem to have improved in subsequent forecasts, although there was variation in different regions. Table 2 in the supplementary information section shows the accuracy metrics for each region and calibration origin.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Model performance at each calibration time point.
Discussion
The COVID-19 pandemic has continued to spread rapidly throughout the world. Several models have been developed to study the transmission dynamics and make short-term projections into the future about expected cases, hospitalisations and deaths16–19. We developed a compartmental model and calibrated it to publicly available data. We assumed that these data are accurate and reliable. The main objective here was to evaluate how the model performed when comparing short-term projections to actual confirmed cases, retrospectively.
Our model performed very well in producing short term projections with reported case counts falling within the range of projections. We obtained an overall forecast error of below 8% on average for four-week-ahead projections in all the countries and regions. As expected, the performance of the projections declined as the forecast horizon increased. This is because many processes that shape the epidemic continue to evolve as the disease evolves, most crucially processes at the molecular level (viral evolution, giving rise to viral variants with substantially different infectivity levels) as well as socio-political processs at the population level (government decisions to tighten or relax lockdown regulations). Neither of these sets of processes were explicitly captured by the model.
As the epidemic continues to evolve, more data will become available. The model’s parameter estimates will become more accurate, and the model-based inference will be less affected by parameter uncertainty. One such model-based epidemiological metric that may prove to be useful for continuous monitoring and evaluation of the COVID-19 response is the ratio of the moving averages of newly infected and newly recovered patients. An increase in this metric would indicate that the epidemic is getting worse, while a decrease would indicate the opposite.
Resurgence of the second wave of infections in different regions resulted in poor forecasts. Future improvements to the model involve redefining the effective contact rate 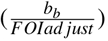 . As lockdown regulations are loosened, we expect more contacts and hence high likelihood of increase in transmission.
. As lockdown regulations are loosened, we expect more contacts and hence high likelihood of increase in transmission.
Our model had an explicit observation process built-in to it. This was done for two reasons: firstly, it allowed us to calibrate the model to the available empirical data, since that data is based upon laboratory confirmed infections - which by definition exclude undiagnosed infections. Secondly, it will allow us to model the effect of interventions (e.g. amplified screening initiatives) that might change how many cases get diagnosed (i.e. what we observe in the real world). However, the challenge is that to date, there is very little literature on epidemiological parameters of those who are undiagnosed versus diagnosed. This influenced the uncertainties for relative infectiousness. For example, we assumed that being diagnosed likely makes a person relatively less infectious, because knowledge of infection would cause a case to modify their behaviour resulting in contact with fewer people through self-isolation. However, it is possible that diagnosed people with severe symptoms could be better at infecting others since those who remain undiagnosed likely have milder symptoms, which is suggestive of lower viral loads30. A related challenge is that we have almost no direct evidence to inform the various detection rates (parameters de, d1, d2, dm and ds) in the model. That in turn makes it virtually impossible to estimate what the impact of intensified contact tracing or screening might be. Relevant improvements in the South African SARS-CoV-2 surveillance system would therefore be immensely helpful in reducing parameter uncertainty and subsequently the uncertainty around model-based estimates and projections.
Our assumptions about the average time spent in each of the different compartments may also require future adjustments. Published estimates of duration spent in hospital or ICU, were not specific enough for our purposes. For instance, for ρ and dc, we used published estimates of length of stay in ICU. The estimate we based our priors on aggregated people together who may have died in ICU with those who were discharged back to a non-ICU hospital bed once they started to get better. Because of this, we made the assumption that those who don’t die have a longer time in ICU than those who do. This may affect how quickly all hospital and ICU beds fill up and how long they stay occupied, which in turn may affect the number total deaths resulting from the model.
The results presented here may also be influenced by the assumptions we made regarding disease severity, particularly in regards to the proportion of cases that remain completely asymptomatic throughout the duration of infection. It has been estimated that as many as 70% or more of infections31,32 could be asymptomatic. However, these studies do not follow-up cases past the full duration of the incubation period in order to see if symptoms develop later. Here, we assumed between 20-40% would be asymptomatic, based upon a systematic review of studies that estimated the proportion of asymptomatic cases when cases were followed-up for at least 14 days to determine their final symptoms status33. If asymptomatic cases are more common than we assumed, then we may expect fewer people to become cases in our model, since they are assumed to be less infectious than symptomatic cases.
In conclusion, even though limited data and considerable uncertainty around the transmission dynamics posed constraints to the accuracy and precision of our model forecasts, our model produced four-week forecasts with a sufficiently high level of accuracy to guide operational and strategic planning for business continuity and COVID-19 responses in Anglo American mining sites.
Several aspects of the model are being revised, in response to emerging knowledge that was not available at the start of the model development. In particular, waning immunity after naturally acquired SARS-CoV-2 infection, and the increasing coverage of COVID vaccines, yet with imperfect protection against infection, are important new features that are being added to the model. With respect to model calibration, comparison of smoothed time series of daily new cases and deaths rather than cumulative cases and deaths is being implemented.
Data Availability
All data referred to in the manuscript are publicly available. https://github.com/dsfsi/covid19za Marivate, V. & Combrink, H. M. Use of available data to inform the covid-19 outbreak in south africa: A case study. DataSci. J.19, 1-7 (2020). https://github.com/CSSEGISandData/COVID-19 Dong, E., Du, H. & Gardner, L. An interactive web-based dashboard to track covid-19 in real time. The Lancet infectious diseases 20, 533-534 (2020). https://www.worldometers.info/coronavirus/ Worldometer covid-19 coronavirus pandemic (2020).
Supplementary Information
Model performance
Overall model performance
Model performance at different time points.
Model parameters
Model parameter values used in the model calibration for all the regions and calibration time points. Time-varying parameters have a corresponding start date. Delta column shows the range within which we allowed the parameters to vary. Fixed parameters have delta value equivalent to zero. Parameters that have blank values for some calibration time points indicate that those parameters were not part of the simulation model.For instance dd f and hd f were not parameters during model calibration for the first time point across all the regions.
Description of model parameters
Model equations
The model is formally represented by a system of differential equations:
 with
with
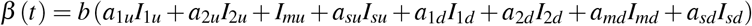 and V representing the number of confirmed cases.
and V representing the number of confirmed cases.
Hospital and critical care capacity limitations
The capacity for hospitals and critical care units to admit patients is not unlimited in South Africa - as in most countries. Defining v as the hospital capacity limit, the effective rate of hospitalisation is: ηH while H < v. When H starts to exceed v, it becomes 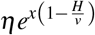 , which is ≈ 0 for large values of x. Similarly, the effective rate of critical care admission is: θC while C < w. When C starts to exceed w, it becomes
, which is ≈ 0 for large values of x. Similarly, the effective rate of critical care admission is: θC while C < w. When C starts to exceed w, it becomes  .
.
Basic reproductive number
The basic reproductive number R0 is given by
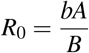 where
where
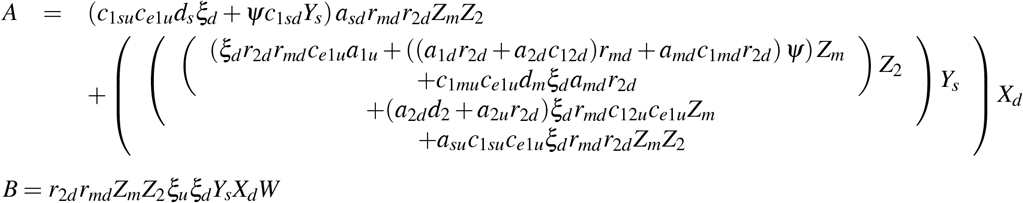 with
with
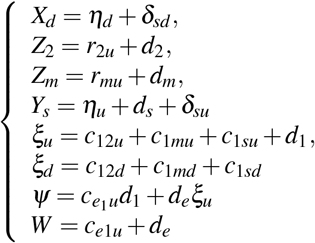
Effective reproductive number
The effective reproductive number Re (t) is given by
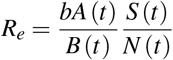 where
where
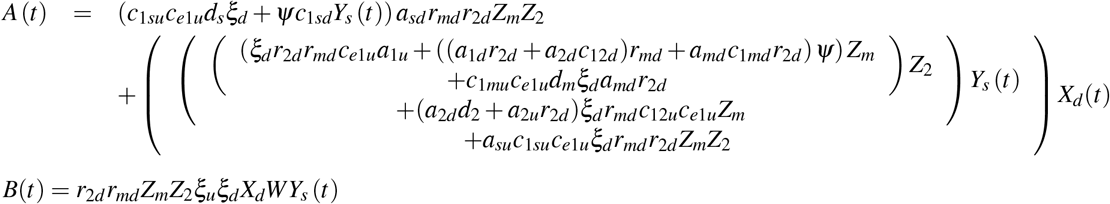 with
with
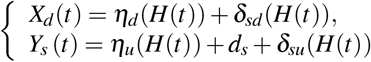
References



