
Abstract
Background There is a need for high yield HIV testing strategies to reach epidemic control. We aimed to predict the HIV status of individuals based on socio-behavioural characteristics.
Methods We analysed over 3,200 variables from the most recent Demographic Health Survey from 10 countries in East and Southern Africa. We trained four machine-learning algorithms and selected the best based on the f1 score. Training and validation were done on 80% of the data. The model was tested on the remaining 20% and on a left-out country which was rotated around. The best algorithm was retrained on the variables which were most predictive. We studied two scenarios: one aiming to identify 95% of people living with HIV (PLHIV) and one aiming to identify individuals with 95% or higher probability of being HIV positive.
Findings Overall 55,151 males and 69,626 females were included. XGBoost performed best in predicting HIV with a mean f1 of 76·8% [95% confidence interval 76·0%-77·6%] for males and 78·8% [78·2%-79·4%] for females. Among the ten most predictive variables, nine were identical for both sexes: longitude, latitude and, altitude of place of residence, current age, age of most recent partner, total lifetime number of sexual partners, years lived in current place of residence, condom use during last intercourse and, wealth index. Model performance based on these variables decreased minimally. For the first scenario, 7 males and 5 females would need to be tested to identify one HIV positive person. For the second scenario, 4·2% of males and 6·2% of females would have been identified as high-risk population.
Interpretation We were able to identify PLHIV and those at high risk of infection who may be offered pre-exposure prophylaxis and/or voluntary medical male circumcision. These findings can inform the implementation of HIV prevention and testing strategies.
Funding Swiss National Science Foundation.
Introduction
In order to reach epidemic control by 2030, the Joint United Nations Programme (UNAIDS) have set fast track targets to rapidly scale up effective HIV services.1 One of the aims is to ensure that 95% of the approximately 38 million people living with HIV (PLHIV) are aware of their HIV status and that 95% of those with HIV positive diagnoses are on treatment.2
People in East and Southern Africa are disproportionately burdened by HIV, constituting more than half of the global PLHIV with 20·6 million people currently estimated to be HIV positive.2 As of 2018, 85% of PLHIV in this region were aware of their HIV status, of whom 79% were accessing treatment.3 In addition, 25% of new HIV infections in East and Southern Africa were concentrated among key populations such as female sex workers, men having sex with men, prisoners and, people who inject drugs.3
HIV is transmitted within a complex network that is influenced by biological, behavioural and, social factors. In East and Southern Africa, there is large geographical variation in the distribution of the HIV epidemic.4 In order to identify populations at a high risk of infection, global HIV prevention efforts have shifted toward optimizing resource allocation by considering geographical data as a way of increasing program impact and efficiency.5
Machine learning algorithms have the power to substantially enhance HIV prevention and detection, increasing the prediction capability by processing large amounts of data of a different nature. This methodology has been implemented to establish patterns of HIV risk behaviour, to optimise HIV treatment modalities and, to identify high-risk individuals for targeted interventions from a number of novel data sources.6–15
As more PLHIV are diagnosed, finding persons with undiagnosed HIV becomes progressively more difficult and expensive. Hence, resource constraints and potential funding shortages have resulted in demands for differentiated high yield testing strategies in parallel to provider- initiated HIV testing and counselling (PITC).14,16,17 We therefore aimed to compare different machine learning algorithms to identify new key populations based on a variety of socio- behavioural characteristics. These insights intend to both inform targeted case-finding strategies as well as identify high risk HIV negative individuals eligible for prevention services such as voluntary medical male circumcision (VMMC) and/or pre-exposure prophylaxis (PrEP).
Methods
Data
Since 1984, the Demographic and Health Surveys (DHS) program has provided technical assistance for over 400 surveys in more than 90 countries, advancing global understanding of health and population trends in developing countries.18 DHS are nationally-representative household surveys that provide data for a wide range of monitoring and impact evaluation indicators on health and nutrition. Standard DHS surveys have large sample sizes (usually between 5,000 and 30,000 households) and are typically conducted every five years.19 We used the most recent DHS surveys at or after 2013 of ten East and Southern African countries (Table A1) with a generalised HIV epidemic: Angola, Burundi, Ethiopia, Lesotho, Malawi, Mozambique, Namibia, Rwanda, Zambia and, Zimbabwe. Male and female’s datasets were combined separately with geographic position of groups of households where the individuals live and HIV test results. We then merged the ten countries and obtained two datasets containing 68,979 males and 83,910 females with 527 and 3,213 variables, respectively.
Data pre-processing, model validation and, algorithm selection
We compared four machine learning algorithms for the prediction of the HIV status of an individual; a penalized logistic regression (Elastic Net),20 a generalized additive model (GAM), 21 a support vector machine (SVM) and,22 a gradient boosting tree (XGBoost).23 The Elastic Net and the GAM are among the most widely used classification methods in biology and medicine, SVM is a very common machine learning algorithm and XGBoost is a decision-tree based ensemble which has gained a lot of attraction since its development few years ago.
The first part of the analyses was done in several steps for each of the four algorithms, and separately for males and females (Figure 1). In the data pre-processing step (Figure 1, step 1), we first cleaned and transformed data from the ten countries into numerical values (Table A2). Only persons for whom the HIV status was either positive or negative were included in the analysis. The cleaned datasets included 55,151 males and 69,626 females with 84 and 122 variables, respectively; 73 variables were common for both sexes (Table A3). Since we wanted to test the generalizability of our model, one country was left out for later testing, and the left- out country was rotated around. We then split each of the data from nine countries combined in an 80% training sample and a 20% test sample. Missing values were imputed using multiple imputation by chained equations (MICE) (as detailed in appendix) and data were further harmonized and scaled.24

All steps are detailed in the method section.
Training and validation were done using five-fold cross-validation on 50 sets of hyperparameters randomly chosen from a grid (Figure 1, step 2). For each of these 50 sets, we calculated the mean f1 scores across the five validation sub-samples and selected the set of hyperparameters that gave the highest value. The f1 score combines the sensitivity and the PPV in a harmonic mean.25 Our primary interest was to find a large number of HIV positive persons (sensitivity or recall) with a high yield (precision or positive predictive value (PPV)). The probability threshold to classify if someone is considered HIV positive was set at 50%.
Once the best models of each algorithm were obtained, we calculated the f1 scores on the ten 20% test and left-out country samples which were not used to train and validate the model (Figure 1, step 3). We averaged these f1 scores in order to compare the different algorithms and the maximum mean f1 on the 20% test samples allowed us to select the best one.
Variables selection, direction of association and, calibration of two scenarios
For the second part of the analysis, where no country was left out, only the selected algorithm was trained and validated again using a random search over 250 sets of parameters (instead of 50) with the same five-fold cross-validation scheme than previously. The first estimation was performed using all variables. We compared the f1 score, the sensitivity and, the PPV using MICE imputation (models M1 and F1 for males and females, respectively) with a different imputation method within the algorithm,23 that considerably simplified the engineering process (models M2 and F2).
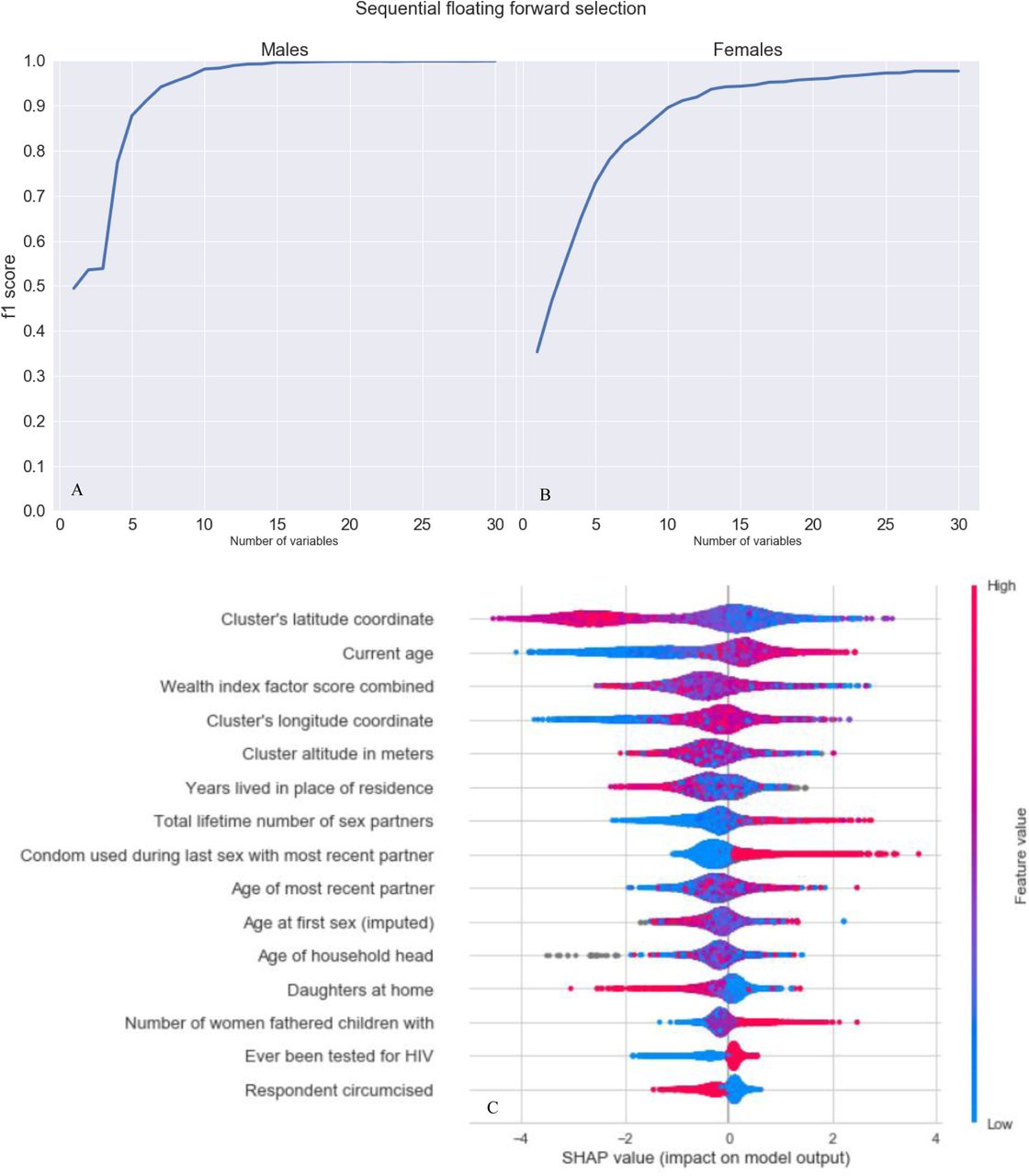
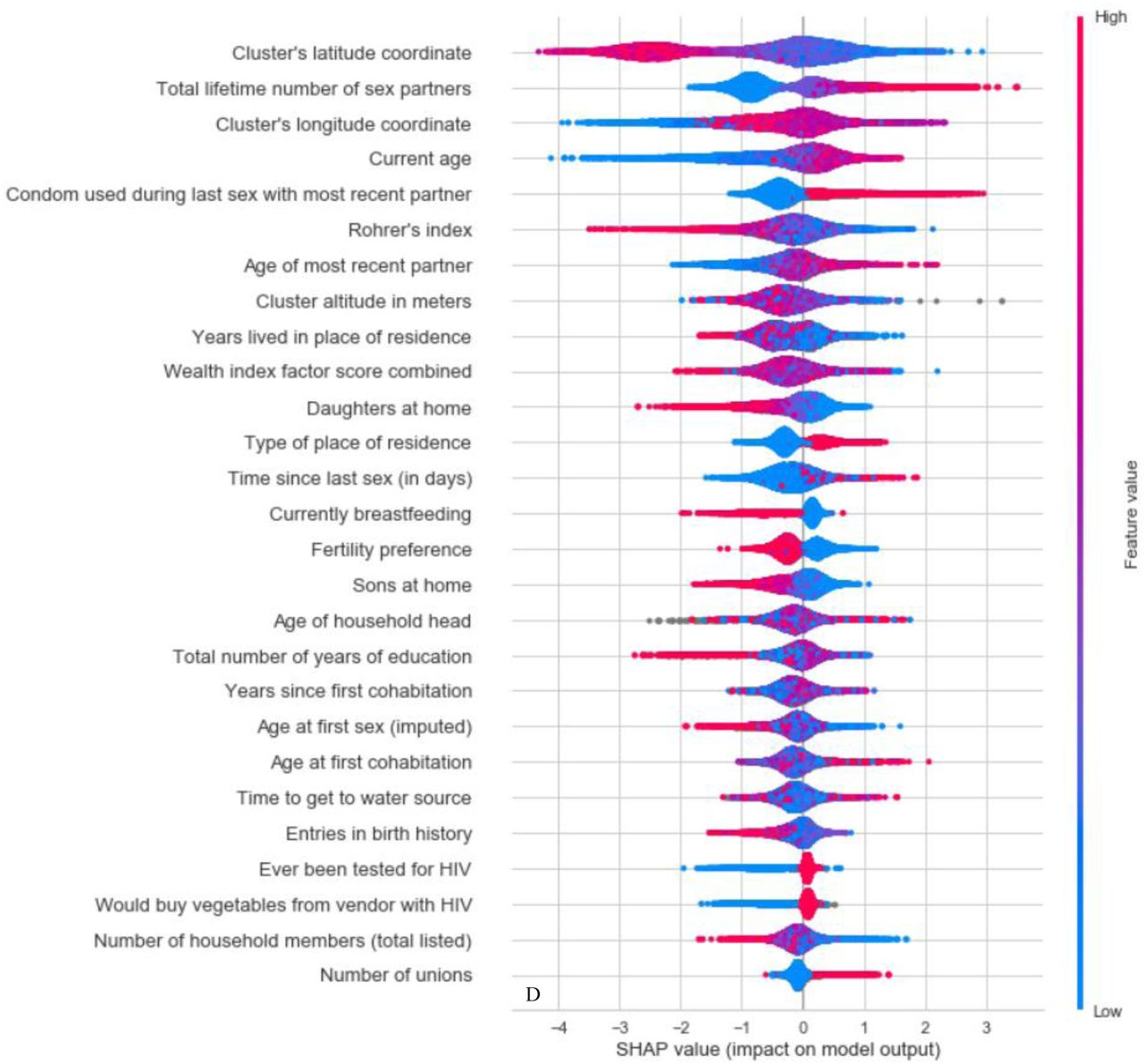
We then performed a sequential forward floating selection (SFFS) using the best imputation method on the 80% training samples and calculated the f1 scores for different number of variables. We selected the subset of variables for which the f1 scores plateaued and assessed the direction of the association between these variables and the probability of being HIV- positive using Shapley values.26
We retrained the best algorithm with the above defined subsets of variables (models M3 and F3) and also on a minimal subset common for both sexes (models M4 and F4). The f1 scores, the sensitivity and, the PPV were compared to the ones obtained for M1, M2, F1 and, F2. We computed the Precision-Recall (PR) and the Threshold-Scores curves (TS) for our preferred model per sex. The PR curve displays the PPV for different sensitivities. This curve is not influenced by imbalanced datasets and is therefore preferred over ROC curve.27 The TS curve, highlights the PPV, the sensitivity and, the f1 score for varying thresholds of classifying if someone is HIV positive.
We then tested two scenarios: for the first scenario, the sensitivity was set to 95%, equivalent to 95% of PLHIV knowing their status. We selected the threshold that corresponds to this sensitivity and reported the corresponding precision and number of individuals to be tested. For the second scenario, we identified a population for which the predicted probability of being HIV positive was 95% or higher. We considered that these individuals are either HIV positive targets for high yield testing strategies or HIV negative individuals who would be ideal candidates for prevention services.
All analyses were performed in Python version 3.7.4. The code is available on https://gitlab.com/Triphon/predicting_hiv_status.
Results
Overall, 55,151 males and 69,626 females were analysed with an HIV positivity ranging from 0·8% among males in Ethiopia to 33·3% among females in Lesotho. The overall HIV positivity was 8·0% (4,417 individuals) for males and 11·5% (8,011 individuals) for females. Persons aged 25 to 34 years represented the largest age group representing 35·9% of females and 31·9% of males. About two-thirds of people lived in rural areas (Table A4).
Algorithms’ performance on the test samples
Figure 2 shows the performance of the four algorithms. XGBoost had the highest f1 scores on all 20 test samples (ten per sex) with a mean f1 score of 76·8% [95% confidence interval (CI) 76·0%-77·6%] for males and 78.8% [78·2%-79·4%] for females. For SVM, the mean f1 score for males was 69·2% [68·2%-70·2%] and 74·6% [73·7%-75·5%] for females and for Elastic Net, the mean f1 score was 32·6% [31·8%-33·4%] for males and 41·5% [40·3%-42·7%] for females. GAM performed worst with a mean f1 score of 26·2% [25·0%-27·4%] for males and 39·8% [38·1%-41·5%] for females (see Table A5i to Table A5iv).

Generalized Additive Model (GAM), Support Vector Machine (SVM).
Algorithms’ performance on the left-out country samples
The performance of the algorithms on the ten left-out samples was substantially lower than on the test samples and the f1 scores varied more widely (Figure 2). The mean f1 score was best for Elastic Net with 21·4% [12·3%-30·5%] for males and 32·6% [21·2%-44·0%] for females followed by XGBoost with 20·9% [14·3%-27·5%] and 29·8% [19·0%-40·6%], respectively. For SVM, the mean f1 score was 15·4% [10·9%-19·9%] for males and 22·3% [14·1%-30·5%] for females. Again, GAM performed worst with a mean f1 scores of 6·6% [0·9%-12·1%] and 17·1% [4·4%-29·8%] (see Table A5i to Table A5iv). The algorithms performed better in countries with higher HIV positivity.
Best algorithm’s performance on the complete datasets
We selected the best performing algorithm, XGBoost, for the second part of the analysis, where no country was left out. The results on all variables using the two different imputation methods are shown in Table 1. For both sexes, the XGBoost imputation (M2 and F2) resulted in slightly higher f1 scores compared to the MICE imputation (M1 and F1). The f1 scores on the validation samples were 75·5% [73·7%-77·3%] vs 74·9% [73·3%-76·5%] for males and 76·1% [74·9%- 77·3%] vs 75·5% [74·6%-76·4%] for females. Given the above results and the simplicity of the XGBoost imputation, we used this imputation for further analyses (i.e. models M3, F3, M4 and, F4).
True positive (TP), False negative (FN), False positive (FP), True negative (TN), Positive Predictive Value (PPV).
Variables selection and direction of associations
Figure 3A and 3B show the result of the SFFS procedure which was used to select a subset of most relevant variables. The f1 scores plateaued above 99·6% with 15 variables for males and above 97·6% with 27 variables for females. Figure 3C and 3D show the 15 and 27 key variables of individual HIV status for males and females. Among these top ten most predictive variables, nine were identical: geographic position (longitude, latitude and, altitude), current age, age of most recent partner, total lifetime number of sexual partners, years lived in current place of residence, condom used during last sexual intercourse with most recent partner, and, a wealth index from the DHS which combines numerous wealth-related variables such as household assets and utility services.28 The age at first sexual intercourse ranked tenth for males and twentieth for females. The Rohrer’s index (an estimate of obesity) ranked sixth for females, but was not available for males. Among the fifteen most predictive variables, four were specific for either males or females (‘number of women fathered children with’ and ‘respondent circumcised’ for males and ‘currently breastfeeding’ and ‘fertility preference’ for females). Other females-specific characteristics included ‘time to get to water source’ and ‘entries in birth history’.


The (SFFS) procedure was implemented (A + B) to determine the saturation point for variable selection base on the f1 score. This resulted in the selection of the 15 and 27 most important variables for males and females, respectively. The variables are displayed below (C + D) sorted by importance from top to bottom (from the highest Shapley value to the lowest). The blue and red colours represent the value range of the variable (e.g. blue represents low value range of the variable). For example, the older the age the more likely the persons will be HIV positive.
Figure 3A and 3B highlight the direction of the association between each variable and the probability of HIV positivity. Among the nine common predictive variables for both sexes, older age, older age of most recent partner, a higher number of total lifetime number of sexual partners, condom used during last sexual intercourse with most recent partner and, longitude were positively associated with the probability of HIV positivity for most individuals. A higher wealth index, a larger latitude coordinate of the residence, altitude and, more years lived in place of residence were mainly negatively associated with HIV positivity.
Performance on subsets of variables
Table 1 shows the results of the XGBoost algorithm on the 15 most important variables for males (M3) and 27 most important variables for females (F3). As expected from the SFFS procedure, the f1 scores for M3 and F3 were similar to M2 and F2. The f1 scores decreased by 1·8 percentage points for males and by 0·5 percentage points for females. Finally, we checked the performance of the algorithm on the nine most predictive common variables for both sexes (M4 and F4). The f1 scores were 72·9% for males and 72·4% for females, decreasing respectively by 2·6 and 3·7 percentage points compared to M2 and F2, and by 0·8 and 3·2 percentage points compared to M3 and F3. M4 and F4 were the models used for the calibration of the two scenarios.
Scenarios
1) 95% PLHIV know their status
Figures 4A and 4B show the PR-curves calculated on the test samples. For males, a sensitivity of 95% would require that 5,450 individuals out of 11,031 (49·4%) would need to be tested to identify 840 HIV positives out of the 883 PLHIV. The corresponding PPV is 15·4%; 7 individuals would therefore need to be tested to find one HIV positive person (number needed to test NNT). For females, 6,696 individuals out of 13,926 (48·1%) would need to be tested to find 1,522 HIV positives out of the 1,602 PLHIV. The PPV is 22·7% and the NNT is 5.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In addition, f1 iso-curves are shown for a typical range of f1 scores that we achieved with the models. Along these lines the f1 scores remain constant.
Positive Predictive Value (PPV)
Figure 4C and 4D: 95% Confidence Interval has been obtained using a bootstrap with n=50
2) 95% or more probability of being HIV positive
Figures 4C and 4D show the TS-curves calculated on the test samples. Out of the 11,031 males and 13,926 females, 461 males (4·2%) and 862 females (6·2%) were identified as high-risk population. For males, 447 would have been correctly identified HIV positive out of the 883 PLHIV. For females, 833 would have been correctly identified HIV positive out of the 1,602 PLHIV.
Discussion
Using large representative datasets with over 120,000 persons from ten East and Southern African countries, we were able to accurately predict the HIV status of individuals using demographic and socio-behavioural characteristics. Using all variables, XGBoost performed better than the three other algorithms on the test samples with a mean f1 score of 76·8% [95% CI 76·0%-77·6%] for males and 78.8% [78·2%-79·4%] for females. Our approach allowed us to select the nine most important predictor variables common for both sexes: geographic position (longitude, latitude and, altitude), current age, age of most recent partner, total lifetime number of sexual partners, years lived in current place of residence, condom used during last sexual intercourse with most recent partner and, wealth index. The performance of the algorithm using only these nine variables to predict HIV positivity was similar to that of the total dataset.
We also determined the direction of the association between predictor variables and HIV status. We confirmed a number of established HIV risk factors such as older age or older age of the most recent partner,29 a large number of sexual partners and, living in an urban area.30 Additionally, circumcision and breastfeeding were associated with a lower risk of HIV positivity. Unlike previous findings,31 condom use during the last sexual intercourse increased the probability of HIV positivity in our study. This seemingly counterintuitive finding may be the result of increased condom use in individuals who are already aware of their positive HIV status. The cross-sectional nature of our study limits our ability to investigate this further. We also identified risk factors for HIV infection which have rarely been investigated before. For example, an increased distance to water was positively associated with HIV infection in some persons, and negatively associated in others. This is in line with a previous study which showed that the risk of sexual assault of women, and hence the risk of HIV infection, increased when the time to reach a water source increased.32 However, longer time to get to water sources are more common in rural areas where HIV prevalence is generally lower, hence a decrease in risk of HIV positivity.
When applying these machine learning algorithms in real world settings, the trade-off between sensitivity (% of HIV positives identified) and PPV (yield) needs to be considered. A model with a sensitivity of 95% would be required to ensure that 95% of PLHIV know their status. In this first scenario, using a model with only nine predictors, we showed that the NNT was 5 (PPV of 15·4%) for males and 7 (PPV of 22·7%) for females. This represents approximately twice the PPV that would be achieved by general population testing. A previous systematic review of different testing strategies showed that NNTs ranged between 3 and 86 for community-based testing strategies and between 4 and 154 for facility-based testing strategies.33
In contrast, if targeted HIV case-finding strategies are implemented to increase the cost- effectiveness of testing strategies, a high PPV is important to ensure that the yield is high, and many of those tested are HIV positive. It is currently unknown if additional behavioural-based testing strategies can enhance or complement current targeted case-finding strategies such as index testing. Acceptable cut-offs for both sensitivity and PPV would need to be adapted for specific settings and for the desired testing coverage. For example, we defined a second scenario to simultaneously identify both high-risk HIV positive individuals for testing and high-risk HIV negative individuals for preventative services such as pre-exposure prophylaxis (PrEP).
To our knowledge, this study is the first to use machine learning methods to predict HIV in generalised HIV epidemic East and Southern African countries using routinely collected survey data. One of the limitations of this study is the generalizability of our findings. The distribution of risk factors varies between countries, and the accuracy of the prediction decreased for countries not used to train the algorithm. It is therefore not surprising, that geographic location of the residence (longitude, latitude and, altitude) were among the strongest predictors, since they were proxies for country-level differences. We were also limited by the available variables in our dataset, and as a result we were unable to consider differences in viral load suppression, health-care expenditure, specific HIV-related interventions and conflicts and wars. Additionally, although HIV testing was laboratory-based and not self-reported, some results were inconclusive and were discarded. A number of variables were self-reported and therefore subject to social desirability and recall bias. Missing values were imputed using multiple imputation, or directly within the extreme gradient boosting algorithm. However, the proportion of missing values was relatively small for most variables and both imputation methods gave similar results.
In conclusion, we were able to identify strong predictors of HIV positivity. Our findings may explain the spatial variability of HIV prevalence and can inform HIV testing strategies in resource-limited settings. While the implementation of a machine learning based risk score for targeted interventions was feasible in rural East Africa,34 the acceptability and use of potentially sensitive behavioural risk factors to directly identify individuals for HIV testing needs to be evaluated. Our algorithm performed well with only a limited number of variables, which do not require extensive interviews or questionnaires. This approach may be implemented by clinicians and community health care workers or utilised through additional HIV case-finding modalities such as call centres, social media and, self-testing initiatives. The availability of individual-level data on the association of various diseases with socio- behavioural characteristics is rapidly increasing. Advanced methods to analyse these large sources of data can help to prevent, diagnose and treat HIV and other diseases more efficiently.
Data Availability
This is a study based on publicly available data from the Demographic and Health Surveys (DHS). The DHS Program is authorized to distribute, at no cost, unrestricted survey data files for legitimate academic research. Registration is required for access to data. https://dhsprogram.com/Data/
Author’s contribution
EO, AM and, OK designed the study with support from SMM. EO wrote the code and performed the analysis with support from AM. EO, AM and, OK interpreted the results with support from JE and SMM. EO and RE reviewed the literature. EO, RE and, OK wrote the manuscript, which was reviewed by JE, SMM, and, AM.
Conflict of interest
We declare no competing interests.
Supplementary material
Selection of variables
Datasets were resampled per country using sample weights from the HIV test results. We excluded individuals whose HIV status was “indeterminate” or “inconclusive” and individuals who reported that they never had sexual intercourse. We then removed variables with no variance and the ones containing more than 30% missing values. Finally, after additional encoding steps (e.g. creation of new aggregated variables or dummy coding of nominal variables), we manually removed an additional 77 non-informative variables for males and 122 for females (e.g. relating to metadata or information on how the survey was conducted), resulting in a final dataset of 55,151 males and 69,626 females with 84 and 122 variables, respectively. Overall 73 variables were common for both sexes (Table A2 and Table A3).
Stratification, MICE imputation and Standardization (Figure 1 - step 1)
The stratification was done based on each sample HIV prevalence to ensure that the percentage of HIV positive individuals in the training and validation samples remained similar to the originals. We imputed missing values of each 80% training sample by multiple imputations using chained equations (MICE), and then applied the same imputation model to the corresponding test and left-out country samples. The regressions on the chained equations have been iterated ten times using the entire set of variables. The imputations have been performed five times and the results were averaged. Finally, the variables were standardized to a variance of one, ensuring that the penalization scheme is fair to all regressors.
Variable names correspond to the name in the Demographic and Health Survey (DHS).
Python libraries
- Matplotlib 3.1.1
- Mlxtend 0.17.0
- Numpy 1.16.5
- Pandas 0.25.1
- Pathlib 1.0.1
- Pyshp 2.1.0
- Pygam 0.8.0
- Scikit-learn 0.21.3
- Scipy 1.3.1
- Seaborn 0.9.0
- Shap 0.30.1
- Xgboost 0.90
- Yellowbrick 1.0.1
Some of the computations were done on the Baobab cluster of the University of Geneva.
Acknowledgements
We acknowledge the support of the Swiss National Science Foundation (SNF professorship grant n° 163878 to O Keiser) which funded this study. We thank Antoine Flahault, Amaury Thiabaud, Danny Sheath and, Isotta Triulzi for helpful discussions and comments.
References



