
Abstract
Purpose We constructed a CYP2D6 copy-number imputation panel by combining copy-number information to GWAS chip data. In addition, we report frequencies of key pharmacogenetic variants in individuals with a psychotic disorder from the genetically bottle-necked population of Finland.
Methods We combined GWAS chip and CYP2D6 copy-number variation (CNV) data from the Breast Cancer Pain Genetics study (BrePainGen) to construct an imputation panel (N=902) for CYP2D6 CNV. The resulting data set was used as a CYP2D6 CNV imputation panel in 9,262 non-related individuals passing genotype data quality control procedures. The panel performance was evaluated by genotyping the CNV from a subset (N=297) of SUPER-Finland participants.
Results CYP2D6 CNV was imputed correctly in 272 (92%) individuals. Sensitivity and specificity for detecting a duplication were 0.986 and 0.946, respectively. Sensitivity and specificity for detecting a deletion using imputation were 0.886 and 0.966, respectively. Based on imputation, the frequency of a CYP2D6 duplication and deletion in the whole SUPER-Finland sample with 9,262 non-related individuals passing quality control were 8.5% and 2.7%, respectively. We confirm the higher frequency of CYP2D6 ultrarapid metabolizers in Finland compared with non-Finnish Europeans. Additionally, we confirm a 21-fold enrichment of the UGT1A1 decreased function variant rs4148323 (also known as 211G>A, G71R or UGT1A1*6) in Finland compared with non-Finnish Europeans. Similarly, the NUDT15 variant rs116855232 was highly enriched in Finland.
Conclusion Our results demonstrate that imputation of CYP2D6 CNV is possible. The methodology is not accurate enough to be used in clinical decision making, but it enables studying CYP2D6 in large biobanks with genome-wide data. In addition, it allows for researchers to recontact patients with certain pharmacogenetic variations through biobanks. We show that bottle-necked populations may have pharmacogenetically important variants with allele frequencies very different from the main ancestral group. Future studies should assess whether these differences are large enough to cause clinically significant changes in trial results across different ancestral groups.
Introduction
Pharmacogenetics is a research field studying how interindividual genetic differences contribute to drug efficacy and safety, aiding physicians in drug selection and dose adjustment1,2. Variants in CYP2D6 and CYP2C19 genes have been shown to affect the metabolism of antidepressants, antipsychotics, analgesics such as codeine and tramadol, the antiplatelet agent clopidogrel and antiarrhythmic drugs, for example3,4,5,6,7,8. Although involved in the metabolism of 25% of all available drugs, research of the CYP2D6 locus at 22q13.2 has been limited by its complexity9,10. In addition to single nucleotide polymorphisms (SNPs), CYP2D6 copy-number variations (CNVs), such as duplications and deletions, also contribute to the metabolic activity of the CYP2D6 enzyme. The effects of SNPs and CNVs on the metabolic activity of CYP2D6 can be summarized by calculating an activity score11. The frequency of the CYP2D6 gene duplication is highly dependent on the population12,13,14,15,16. The effects of genetic variants on drug metabolism are large enough to cause the Food and Drug Administration (FDA) and the European Medicines Agency (EMA) to add pharmacogenetic information on drug labels17,18,19 and the American Psychiatric Association to inform clinicians on pharmacogenetics in recently updated schizophrenia guidelines20. Whether the difference in allele frequency explains why different ethnicities respond to certain drugs differently is difficult to estimate, as there are other cultural and socio-economic factors at play as well21.
Genotype imputation has been successfully used in genome-wide association studies (GWAS) to acquire data on ungenotyped markers, facilitate fine-mapping, and boost power in association studies22. The method relies on the haplotype structure of the human genome. Haplotypes are block-like regions of DNA. Within these blocks certain variants tend to co-occur allowing for separation of maternally and paternally inherited variants. Information of which variants are located on the same chromosome is needed to accurately impute missing variants. This information also has an important role in pharmacogenetics since it allows to infer whether, for example, two loss-of-function variants in the same gene are located on the same chromosome or not. If they resided on different homologous chromosomes, the individual would be a complete knock-out for the pertinent gene. On the other hand, if these two variants resided on the same chromosome, the individual would still carry one functional copy of this gene resulting in a pharmacogenetically different situation. The process of computationally separating the variants to different chromosomes is called phasing23. Usually, only SNPs or short indels are imputed, but since CYP2D6 duplications and deletions tend to co-occur with certain SNPs, we hypothesized that existing imputation algorithms could be exploited to impute CYP2D6 CNVs to a large set of GWAS chip-genotyped individuals. Usually, CNVs are genotyped with real-time PCR as CYP2D6 CNVs are too small (4 kilobases) to be detected from GWAS chip signal intensity data. Successful imputation would allow for genotyping only a subset of the sample (a few hundred individuals), after which the CNV carrier status could be predicted in silico for hundreds of thousands of individuals. This would result in cost-effective pharmacogenetic analyses in biobanks and other large GWAS chip-genotyped samples, such as FinnGen (www.finngen.fi).
Next generation sequencing has become increasingly popular during the recent years. Several algorithms already exist to predict CYP2D6 carrier status from sequencing depth, which is a measure of overlapping reads in a given region of the genome. Duplicated genome regions tend to have a higher sequencing depth compared with the regions of the reference genotype as more reads are generated from the duplicated region. However, sequencing data are available from smaller sample sets compared with GWAS chip data. Furthermore, CYP2D6 CNV algorithms relying on sequencing depth tend to provide discordant CNV calls24.
Due to the small founder population, bottleneck effects and genetic drift, the Finnish population is enriched for certain low frequency (0.5-5%) variants, including coding and loss-of-function variants25,26. Thus, our secondary aim in this work was to assess whether the unique population history has caused alterations in the frequency of pharmacogenetic variants compared with other European populations.
Material and methods
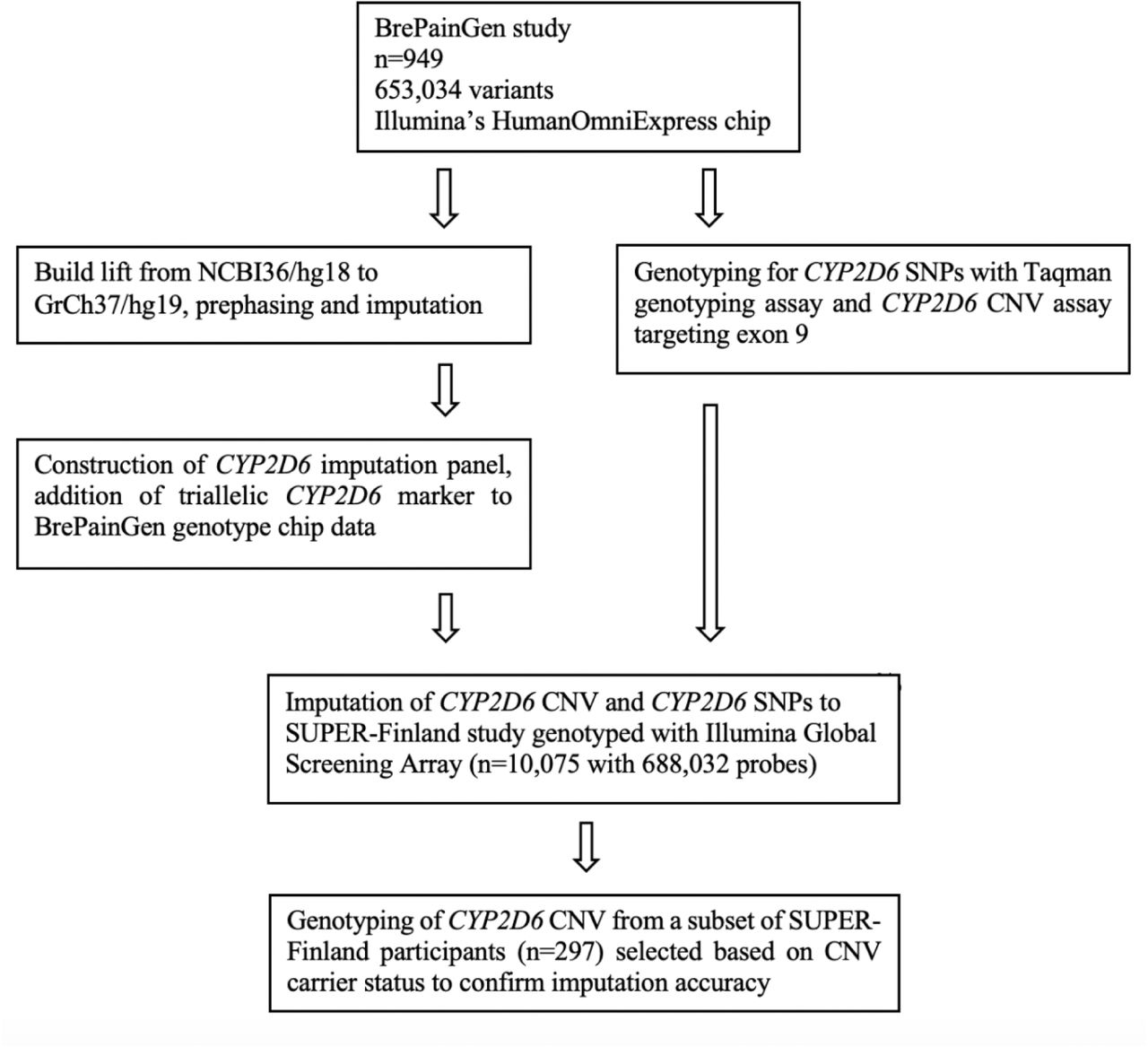
A flow chart of the study protocol is provided in Figure 1.

{kind=link}
SUPER-Finland study
The SUPER-Finland study recruited 10,474 participants aged >18 with a severe mental disorder between the years 2016-2018 from Finland. Subjects were recruited from in- and outpatient psychiatric, general care, and housing units with a diagnosis of a schizophrenia spectrum psychotic disorder (ICD-10 codes F20, F22-29), bipolar disorder (F30, F31) or major depressive disorder with psychotic features (F32.3 and F33.3). As Finland contains internal genetic subisolates27,28, special care was taken to ensure wide coverage of known isolate areas.
Blood samples were drawn from participants for DNA extraction (2x Vacutainer EDTA K2 5/4 ml, BD). When venipuncture was not possible, saliva sample (DNA OG-500, Oragene) was collected for DNA extraction. All samples were frozen (−20°C) on site within 60 min of sampling and sent to the THL (Finnish Institute for Health and Welfare) Biobank within 3 months for long term storage in −185°C. DNA was extracted from EDTA-blood tubes using PerkinElmer Janus chemagic 360i Pro Workstation with the CMG-1074 kit. After incubation in +50 °C, o/n DNA was extracted from saliva samples with Chemagen Chemagic MSM I robot with CMG-1035-1 kit. DNA samples were shipped on dry ice to the Broad Institute of MIT and Harvard, Boston Cambridge, Massachusetts, USA for genotyping and sequencing.
ICD-code diagnosis and disease duration (as years from receiving the diagnosis until recruitment) of the SUPER-Finland participants were extracted from The Care Register for Health Care29.
Genotyping and sequencing
10,075 SUPER-Finland individuals were genotyped with Illumina Global Screening Array containing 688,032 probes. Genotyping was performed at Broad Institute in Cambridge, Massachusetts, USA. Subjects with a genotyping success rate < 90% and discordance between reported gender and genotyped sex were excluded. After this, variants with over 90% of missing genotype calls and related samples using pi-hat cut-off of 0.15 were excluded. Variants deviating from Hardy-Weinberg equilibrium were excluded (P < 1×10−8). Samples with low or excess heterozygocity (±3SD from sample mean) were excluded. Imputation was performed using the FinnGen-style imputation protocol as described in protocols.io (https://www.protocols.io/view/genotype-imputation-workflow-v3-0-nmndc5e?version_warning=no). Sequencing Initiative Suomi (SISu) v2 panel was used as the imputation reference30.
Construction and validation of CYP2D6 CNV imputation panel
A CYP2D6 CNV imputation panel was constructed using data from the Breast Cancer Pain Genetics Study (BrePainGen31,32). The Finnish BrePainGen consisted of 1000 patients recruited between 2006-2010, who underwent surgery for breast cancer at the Helsinki University Hospital. The BrePainGen subjects were genotyped with HumanOmniExpress-12v1_H chip manufactured by Illumina. Before quality control, we had data consisting of 949 samples and 733,202 probes. Probes with more than 3 % missing data were excluded (222 probes failed). After this, samples with over 3% missingness rate (0 excluded) were filtered. Variants with minor allele frequency below 0.5% were excluded (63918 variants excluded). Subsequently, variants with Hardy-Weinberg p-value < 1×10E-6 were excluded (10,857 fails). Sex check was not performed as all samples were from female study participants. In the heterozygosity check, 14 samples failed. Five samples were excluded due to relatedness. Based on MDS plots, 4 individuals were excluded. The final data set consisted of 653,034 variants and 926 samples. The genotyping rate was 0.9968. The initial dataset was lifted from NCBI36/hg18 to GrCh37/hg19 using Will Rayner’s method (https://www.well.ox.ac.uk/~wrayner/strand/). CYP2D6 CNV was genotyped separately with real-time PCR32. Data on CNV were converted with R to Plink ped- and map-file format. This was then joined to the quality controlled GWAS chip data with Plink’s (version 1.9) --merge option. Next, the data were pre-phased with Eagle33,34 version 2.4 and imputed with Beagle35 version 4.1 software. The software code for CNV imputation pipeline is available upon reasonable request.
Genotyping of CYP2D6 CNV in a subset of SUPER-Finland participants
To confirm the copy-number imputation results, 297 SUPER-Finland subjects were selected for CYP2D6 CNV genotyping based on CNV and SNP imputation results to guarantee a sufficient number of deletion and duplication carriers in addition to *41, and *10 carriers in the validation set. Samples with possible fusion gene were excluded (n=9). Real-time PCR genotyping was performed on QuantStudio™ 12K Flex system (Thermo Fisher Scientific, Waltham, MA) with three TaqMan® Copy Number Assays: Hs00010001_cn targeting exon 9, hs04502391_cn targeting intron 6, and hs04083572_cn targeting intron 2 of CYP2D6 gene. Four replicates of each sample were genotyped. The reaction volume was 10 μl and RNase P was used as a reference assay. The copy-number for each sample was calculated with the CopyCaller™ Software (Applied Biosystems®) according to the manufacturer’s instructions.
Haplotype construction according to CPIC guidelines
To predict pharmacogenetic phenotypes from genotype, functional annotations described in The Clinical Pharmacogenetics Implementation Consortium (CPIC) guidelines were followed for variants in the CYP2C936, CYP2C1937, CYP2D638, DPYD39, NUDT1540, SLCO1B141, TPMT40 and UGT1A142 genes. Variants included in the phenotype prediction from the SUPER-Finland data are described in Supplement Table 1. If an individual did not carry any of these variants, but had been genotyped, the predicted phenotype was defaulted to normal.
Statistical analyses
To provide estimates for the accuracy of the imputation method, we calculated sensitivity, specificity, negative predictive value (NPV) and positive predictive value (PPV), as described earlier43.
To calculate the differences in the geographical distribution of the predicted pharmacogenetic phenotypes, we used Fisher’s test. All statistical analyses were performed in R version 3.5.144.
Ethics statement
The SUPER-Finland study was given a favorable ethics statement (202/13/03/00/15) by the Coordinating Ethics Committee of the The Hospital District of Helsinki and Uusimaa (HUS). The BrePainGen study was approved by the Coordinating Ethics Committee (136/E0/2006) and the Ethics Committee of the Department of Surgery (Dnro 148/E6/05) of the Hospital District of Helsinki and Uusimaa (HUS). Written informed consent was obtained from each participant prior to inclusion in both of the studies.
Results
9,262 non-related individuals participating in the SUPER-Finland study passed genotype quality control steps and thus had imputed genotype data available, 49.6% of these samples were female. The descriptive statistics of the sample are shown in Table 1.
CYP2D6 CNV imputation panel
The performance of the CYP2D6 CNV imputation panel was evaluated by genotyping CNVs with real-time PCR from 297 SUPER-Finland subjects. Sensitivity, specificity, PPV and NPV are reported in Supplemental Table 2. The contingency table of imputed and PCR-genotyped CYP2D6 CNVs in SUPER-Finland is presented in Table 2. Because subjects were selected based on expected copy-number for validation, NPV and PPV do not represent the situation in the general population or in the patients with psychosis as PPV and NPV are dependent on CNV frequency. The imputation method was able to identify all except one true duplication carrier as having CYP2D6 duplication but it misclassified additional 12 subjects as having CN=3 although these 12 subjects did not carry duplications. This results in high sensitivity (0.986) for detecting duplications. CYP2D6 deletions were imputed correctly for 31 individuals. The method misidentified 4 individuals carrying a deletion as either having a normal copy-number or carrying a duplication (false negatives). Overall, the method showed good accuracy as CYP2D6 CNV was imputed correctly for 272 (92%) individuals.
Frequencies of key pharmacogenetic variants in SUPER-Finland
Predicted phenotypes and prevalence of CYP2C9, CYP2C19, CYP2D6, DPYD, NUDT15, SLCO1B1, TPMT, UGT1A1 phenotypes in SUPER-Finland (total n=9,262) are described in Table 3. Observed minor allele frequencies of the variants used in the phenotype prediction are included in Supplemental Table 1. Based on CYP2D6 imputation, CYP2D6 gene duplication occurred in 8.5% (n=791) and deletion in 2.7% (n=247) of the SUPER-Finland participants. A total of 26 individuals carried the duplication in both homologous chromosomes and two individuals had both gene copies deleted. When these structural re-arrangements were combined with SNPs and translated to predicted CYP2D6 phenotypes, we observed that 6.6% (n=607) of the participants were ultrarapid metabolizers (UMs), 62.7% (n=5811) were normal metabolizers (NMs), 27.5% (n=2545) were intermediate metabolizers (IMs) and 3.2% (n=299) were poor metabolizers (PMs).
The prevalence of CYP2C19 UMs was 3.8% (n=355). 24.3% (n=2254) were classified as RMs and 3.5% (n=321) as PMs, 39.7% (n=3676) were NMs and the remaining 28.7% (n=2656) were IMs. The predicted phenotypes for CYP2C9 were as follows: NM 67.3% (n=6230), IMs with 1.5 activity score 19.7% (n=1823), IMs with 1 activity score 11.0% (n=1022) and PMs 2.0% (n=187).
As the population history of Finland has created genetic subisolates within the country, we compared whether the prevalence of the pharmacogenetic phenotypes of CYP2D6 and CYP2C19 differ by recruitment center (Supplemental Tables 3 and 4). For CYP2D6 UMs, the largest absolute difference was observed between Kuopio and Oulu (5.0% vs 7.7%; OR 0.63; 95% CI 0.47-0.83; P < 8×10−4).
A NUDT15 variant classified as having no function (rs116855232-T) was enriched in Finland for 6.5-fold (P = 2.09× 10−181) when comparing Finns and non-Finnish Europeans from GnomAD v2.1.1 (https://gnomad.broadinstitute.org)45. The minor allele frequency was 0.02 in GnomAD Finns as well as in SUPER-Finland (Supplemental Table 1) whereas it is 0.004 for Europeans in general.
A variant in UGT1A1 gene encoding *6 haplotype (rs4148323-A) was enriched in Finland 22-fold (Supplemental Table 1). The minor allele frequency in Finns was 5% compared to 0.2% in non-Finnish Europeans.
Discussion
We have shown that the CYP2D6 copy-number can be reliably imputed for research purposes. The presented imputation method allows for imputation of the CYP2D6 copy-number in large samples such as the UK Biobank and FinnGen. This in turn allows detailed cost-effective pharmacogenetic analyses, as these data sets have longitudinal drug prescription history available. Studying pharmacogenetics in psychiatric patients is important as many drugs used in psychiatry are metabolized through polymorphic CYP-enzymes and some of these drugs, such as antidepressants, exert their effects slowly compared with diabetes medication, for example46,47. Thus, a 4-8 weeks follow-up is recommended before switching for example an antidepressant to another48. Therefore, a lack of efficacy from the initial treatment may only be discovered weeks or months after the initiation of the treatment and may lead to a major slow-down in the patient’s recovery process. Evidence is already emerging that polymorphisms in genes encoding CYP enzymes are associated with clinically significant outcomes49. Interestingly, the drug concentrations and adverse drug reactions seem to be under strong monogenic or oligogenic control with only one or few loci associated with them (at least with current sample sizes) whereas many psychiatric disorders are extremely polygenic50,51,52,53. As accurate inference of metabolic activity of CYP2D6 cannot currently be done from GWAS chip data alone, the copy-number imputation method creates new opportunities for development towards and research of individualized medicine. When more data emerge, the pharmacogenetic decision algorithms can be then fine-tuned to reflect newest findings54. Hence, it is important that pharmacogenetic reports can be updated to maintain best possible dosing guidelines available for the patients.
For research use, the correlation between imputed and true copy-number is not required to be perfect if we are studying large cohorts, as even modest correlations will add information. To achieve similar statistical power for detecting an association using an imputed marker as opposed to using a directly genotyped one, the sample size must be increased by 5-13% for each 1% increase in imputation error55. Given that many pharmacogenetic studies conducted so far have a sample size below 2,000 individuals, statistical power gained through increasing sample size to biobank scale (500k samples) would overcome the power loss due to inaccuracy in imputation. The imputation inaccuracy can be passed to statistical models for examples as allelic dosages, which range between 0 and 2. The closer the dosage is to a round number (0, 1, or 2), the more accurate the imputation result is. Other measures, such as posterior probability, have also been used22. As some pharmacogenetic variants are rare, imputation might be even more accurate than direct genotyping of the variant of interest with a GWAS chip, as calling algorithms perform poorly on rare variants and thus they are usually excluded before imputation56,57.
Genetic variation in CYP2D6 has been described and compared between Finns and other European populations by earlier smaller studies. The Finns have been shown to have a high frequency of CYP2D6 duplications and UM phenotypes compared with the ancestral European population15,58. Here, we show a high frequency of CYP2D6 UMs among subjects with a psychotic disorder throughout the country. CYP2D6 genotype has an effect on metabolism of antipsychotics, such as risperidone and aripiprazole. This effect is further reflected on the therapeutic failure rate during risperidone therapy, suggesting that genotyping could be used to guide dosing decisions4.
We confirm a high frequency of the UGT1A1 variant rs4148323, also known as UGT1A1*6, in Finland. This variant has been linked to irinotecan toxicity in Biobank Japan59. According to GnomAD v2.1.1, the frequency of rs4148323-A in Europeans is only 0.2% but here we report, as seen earlier in a small sample size study60, that the frequency in Finns is 4.2% which means an approximately 21-fold enrichment. The study concerning irinotecan-treated patients from Biobank Japan demonstrated that 51 out of the 330 subjects with normal UGT1A1 metabolism experienced adverse drug reactions (15%) whereas 8 out of 15 subjects (53%) with rs4148323-AA experienced an adverse drug reaction. As rs4148323-A is rare among European subjects, the drug trials involving irinotecan might not have captured the increased risk related to this genotype in Finns. Another UGT1A1 variant, linked to decreased irinotecan metabolism is UGT1A1*28 or rs817534761. The pertinent variant is also linked to Gilbert syndrome characterized by periods of intermittent icterus62. The variant inserts a seventh TA repeat sequence to already six TA repeats within UGT1A1 thus decreasing the enzyme activity by 70%63. Since rs8175347 was not present in the SISu imputation panel, we used a proxy variant (rs887829) to estimate the frequency of UGT1A1*28 in Finns. The proxy variant is in strong linkage with rs8175347 in Finns according to LDlink64 (r-squared 1.0) and also associated with Gilbert syndrome in FinnGen (https://www.finngen.fi/en/access_results). The proxy also shows an increased frequency among Finns compared with the rest of Europe, which leads to a high frequency of UGT1A1 poor metabolizers in Finland. This should be considered when planning to initiate irinotecan treatment for patients with Finnish ancestry. Finnish Biobank samples should be used to evaluate risks associated with irinotecan treatment as studies conducted elsewhere in Europe may not be generalizable to Finland.
CYP2C19 genotypes have been shown to contribute to the metabolism of several antidepressants, clopidogrel, and proton pump inhibitors3,37,65,66,67. Subjects with poor or intermediate CYP2C19-mediated metabolism are at increased risk for recurrent myocardial infarction after percutaneous coronary angioplasty when treated with clopidogrel as the activation of the drug is insufficient68,69. CYP2C19 genotype is also associated with a failure of escitalopram treatment. Jukic et al. reported that 30.7% of CYP2C19 PMs discontinued escitalopram compared to discontinuation rates of 11.8%, 17.8%, and 28.9% in normal, rapid, and ultrarapid metabolizers, respectively3. Thus, subjects with an increased discontinuation rate make up 31.6 % of SUPER-Finland subjects, which is a clinically significant proportion of the patient base.
Recently, a new compound called siponimod, was introduced to markets in Europe and the USA for the treatment of multiple sclerosis70. The therapeutic dose of siponimod is dependent on the CYP2C9 genotype. In addition to siponimod, the CYP2C9 gene has a well-established role in determining the warfarin dose71. According to the manufacturer of siponimod, the drug is contraindicated in patients with the CYP2C9 *3/*3 genotype (rs1057910-CC). In addition, dose adjustment is needed for *2/*3 and *1/*3 genotypes. Thus, genotyping is necessary before initiating the drug. According to our results, the drug is contraindicated in about 0.5% of Finns and 11.2% require dose adjustments.
DPYD variants have a large impact on the safety of the chemotherapeutic agents capecitabine and 5-fluorouracil. Based on the phenotype prevalence observed here, 7.1% (n=658) of individuals would require dose adjustment for these drugs according to the CPIC guidelines39.
Variations in NUDT15 were recently introduced in the CPIC guidelines to help estimate azathioprine dose for the treatment of Crohn’s disease, for example40. When determining proper azathioprine dose, NUDT15 variants are interpreted together with TPMT variants. According to CPIC’s decision algorithm, the dose is determined by the gene the function of which is most severely affected. Thus, if the TPMT genotype is normal and the NUDT15 phenotype is an intermediate metabolizer, the dosing follows the recommendation for the NUDT15 intermediate metabolizer. When genotyping only TPMT (combined minor allele frequency of 5.6%) almost half of the individuals requiring dose adjustment based on the most up-to-date information are missed, while treating patients of Finnish ancestry.
The strength of our study is the large sample size, genotyped with a GWAS chip, which enabled us to estimate the LD structure in more detail, as compared with pharmacogenetic studies which have relied on genotyping of only a few variants. A limitation is that the sample was ascertained based on a previous diagnosis of psychosis and many patients were recruited from long-term treatment facilities and housing-units, which may skew the results towards patients who have had a sub-optimal therapeutic response, and thus divert the pharmacogenetic variant frequencies from the population mean. The BrePainGen study, from which the imputation panel was derived, included only women. However, this is not a problem because the CYP2D6 gene is located in the autosome and the prediction of CYP2D6 phenotype from genotype does not differ between males and females72. The geographical difference in CYP2D6 and CYP2C19 phenotypes may also arise from trends in relocation instead of population history. Despite this, the geographical information can be used to inform local clinicians.
In conclusion, we demonstrate that despite complex structural variations in the CYP2D6 locus, the copy-number can be computationally imputed. As the locus has consistently been shown to associate with drug concentrations, researchers are now able to expand these studies to disease outcomes using biobank data, for example. This will boost the development of individualized dosing algorithms and might eventually translate to improved patient care, especially in psychiatry. Over 20% of drugs listed by FDA as having pharmacogenetic information on their labels are used to treat psychiatric diseases. From these drugs, 69 % are metabolized through CYP2D673. Additionally, we show that the bottle-neck effect contributes to the frequency of pharmacogenetic markers in Finland by demonstrating a high frequency of the decreased function variant UGT1A1*6. Further research should evaluate whether the observed phenomena affect the generalizability of the results of clinical trials across different ancestral groups.
Data Availability
The data is available from THL biobank when released from original study
Funding
The SUPER-Finland sample collection was funded by The Stanley Center for Psychiatric Research at the Broad Institute of MIT and Harvard, Boston, USA. Katja Häkkinen has received funding from the Ministry of Social Affairs and Health Finland, through the developmental fund for Niuvanniemi Hospital, Kuopio, Finland, The Finnish Cultural Foundation, Helsinki, Finland, The Finnish Foundation for Psychiatric Research, Helsinki, Finland, The Social Insurance Institution of Finland, Helsinki, Finland and The Emil Aaltonen Foundation, Tampere, Finland. Markku Lähteenvuo has received funding from The Finnish Medical Foundation, Helsinki, Finland and Emil Aaltonen Foundation, Tampere, Finland. Kimmo Suokas has received funding from The Jalmari and Rauha Ahokas Foundation, Helsinki, Finland and The Finnish Foundation for Psychiatric Research, Helsinki, Finland. Mikko Niemi has received funding from Sigrid Jusélius Foundation, Helsinki, Finland. Ari Ahola-Olli has received funding from The Orion Research Foundation, Espoo, Finland, The Juho Vainio Foundation, Helsinki, Finland and The Finnish Post Doc Pool.
Conflict of interests
Markku Lähteenvuo is a board member of Genomi Solutions ltd. and Nursie Health ltd., has received honoraria from Sunovion ltd., Orion Pharma ltd., Otsuka ltd. and Janssen-Cilag. Ari Ahola-Olli is a part-time employee at Abomics, a company offering pharmacogenetic consultation services and ICT solutions. Part of Mari Kaunisto’s and Risto Kajanne’s salaries is covered by a large Finnish biobank study FinnGen, funded by twelve international pharmaceutical companies (Abbvie, AstraZeneca, Biogen, Celgene, Genentech, GSK, Janssen, Maze Therapeutics, Merck/MSD, Novartis, Pfizer and Sanofi) and Business Finland. The other authors declare no competing interests.
Acknowledgements
We thank BrePainGen and SUPER-Finland study participants.
Footnotes
↵* years 2016-2018
References



