
Abstract
Background Pause duration analysis is a common feature in the study of discourse in Alzheimer’s disease (AD) and may also be helpful for its early detection. However, studies involving patients with amnestic mild cognitive impairment (aMCI) have yielded varying results.
Objectives To characterize the probability density distribution of speech pause durations in AD, two multi-domain amnestic MCI patients (with memory encoding deficits, a-mdMCI-E, and with retrieval impairment only, a-mdMCI-R) and healthy controls (HC) in order check whether there are significant differences between them.
Method 112 picture-based oral narratives were manually transcribed and annotated for the automatic extraction and analysis of pause durations. Different probability distributions were tested for the fitting of pause durations while truncating shorter ranges. Recent findings in the field of Statistics were considered in order to avoid the inherent methodological uncertainty that this type of analysis entails.
Results A lognormal distribution (LND) explained the distribution of pause duration for all groups. Its fitted parameters (µ,σ) followed a gradation from the group with shorter durations and a higher tendency to produce short pauses (HC) to the group with longer pause durations and a considerably higher tendency to produce long pauses with greater variance (AD). Importantly, a-mdMCI-E produced significantly longer pauses and with greater variability than their a-mdMCI-R counterparts (α = 0.05).
Conclusion We report significant differences at the group level in pause distribution across all groups of study that could be used in future diagnostic tools and discuss the clinical implications of these findings, particularly regarding the characterization of aMCI.
Introduction
With nearly half of the individuals diagnosed with Mild Cognitive Impairment (MCI) due to Alzheimer’s Disease (AD) developing dementia within three years [1,2], it has been suggested that diagnosis at the prodromal stage represents the optimal time-window for onset delay and potential intervention [3]. Not only is it more cost-effective than diagnosis at the dementia stage [4], but it is also considered to be less distressful for patients in comparison to population screenings, allowing for care planning when concerns are raised and assistance is needed [5]. The assessment of the constellation of cognitive deficits found in the prodromal stage of AD has proven to provide considerable diagnostic power regarding dementia progression regardless of biomarker use [6] and seems to have clearer clinical utility [2,7]. Crucially, neuropsychological testing is accessible in every clinical context, which makes cognitive profiling the current focus of general clinical practice [9] and prevention efforts [10]. However, due to the heterogeneity in MCI’s clinical profile and outcome, risk factors for Alzheimer’s dementia and their association with MCI subtypes need yet to be ascertained [11].
While the prognostic relevance of the number of cognitive domains affected is still under debate [11,1,12], the presence of memory deficits –with or without accompanying impairment in other domains– was initially considered a definitory feature of the clinical syndrome [13,14,15] and is a consistent factor in the clinical profile of a great proportion of MCI patients with a later progression to dementia [16,17,18,19,20,21]. More specifically, impairment in episodic memory encoding reflected in unsuccessful cued recall and susceptibility to intrusion effects has been associated with higher probability of underlying [22,23,24] even at the prodromal phase of MCI [25]. More recent studies have demonstrated that this particular cognitive profile in MCI is compatible with positive AD biomarkers [26,27,28,29,30], as well as abnormal neural connectivity [31,32,33] and cerebral perfusion patterns [34] during memory encoding tasks. Moreover, declines in memory encoding have been predicted in amyloid-positive cognitively-normal individuals [35,36,37] alongside downstream tau increases [38,39,40,41], as well as in patients with subjective cognitive complaint with positive AD biomarkers [42]. Abnormal cortical activity has also been observed in genetic carriers during memory encoding tasks [43,44], supporting the thesis of a preference of AD pathology for cortical areas devoted to memory processing and, more precisely, those involved in encoding and retrieval of newly learned information.
Language impairment has also been consistently observed in MCI patients who end up with a dementia diagnosis [45,46]. AD progressors perform significantly worse than non-progressors at naming [47,48,50,49] and semantic fluency [50,51,52,53] with prediction models combining biomarkers and composite cognitive scores benefitting significantly from the inclusion of language-related scores[16,54,55]. Spontaneous speech is a highly complex process recruiting various levels of linguistic processing that has revealed substancial differences between patients with MCI due to Alzheimer’s Disease (AD) and their healthy counterparts, predominantly in the form semantic impoverishment and reduced fluency (see [56,57] for recent reviews).
The great advances in fields such as natural language processing and automatic speech recognition in the last decades have contributed to a surge in studies reporting in most cases on a large number of linguistic and paralinguistic variables [58,59,60,61,62,63,64,65,66,67,68,69], ranging from voice features [70,71,72] to discourse analysis [73,74,19,75,76] in the characterization of patients with MCI due to AD. The measurement of voiced and unvoiced segments in connected speech has been a particularly prolific research avenue thanks to its relative methodological simplicity and the great technical precision that current technologies grant. In this regard, it has been found that AD patients produce more silent pauses than healthy controls (HC) [77], more frequently [78,79] – although not in [80]- and with longer mean duration [79,80] (but not in [77]), thus representing a larger proportion of discourse time in comparison to voiced segments [78,79,62,81].
These speech fluency features are already present in MCI, with patients producing more pauses [69] at a higher rate than HC [59,68], although pause rate did not differ in other studies [69,82] and neither did the number of pauses [83]. Mean pause duration is another recurring feature of study since patients with MCI are expected to produce pauses with longer mean duration than those of healthy controls [62,59,82], although in other studies no significant difference was found [68,83] or this was finding was task-dependent [69]. Voice-to-silence ratio seems to be a more reliable feature, consistently differentiating the narratives of patients with MCI from their healthy counterparts with a lower proportion of voiced time in relation to total discourse time [50,69,59,68,83].
Differences in task choice, criteria for pause labelling, temporal thresholding, or methodology applied-manual versus automatic transcription and segmentation-may have contributed to some extent to discrepancies in the results, as seem to point out studies assessing different task types as [69,59] in MCI and [79] in AD or comparing manual and automatic annotation [68].
In previous studies it has been pointed out that speech segments are not normally distributed and that, therefore, moments of the distribution –e.g. mean and variance– may be inadequate for the characterization of linguistic elements including words and speech pauses [84,85,86,87,88,89]. Further studies, have shown that lognormal distribution is a more accurate approximation for the description of speech pause duration distribution in human voice, showing consistency across studies and good sensitivity for identifying particular constraints such as distribution across discursive and syntactic boundaries or task type [90,91,92]. Its application to language-impaired groups in other neurological disorders such as vascular aphasia or ataxic dysarthria has confirmed these findings, revealing differences in duration and distribution between those and healthy controls [86,93,94].
In this work we firstly endeavour the characterization of the distribution of speech pauses in AD, amnestic MCI and HC considering some limitations inherent to the segmentation of speech pauses such as higher relative errors on shorter ranges. For this purpose, we address the fitting of truncated distribution considering recent discussions on cut-off point selection on long-tail distributed data. In particular, we show that patients with confirmed Alzheimer’s dementia and amnestic multi-domain MCI patients with memory encoding deficits (a-mdMCI-E) at high risk of dementia progression produce significantly longer pauses and with more dispersion than healthy controls, as well as to determine the relative weight of long pauses in relation to their general pattern of pause production. Crucially, we expect to also find significant differences in pause duration and distribution between the group with a-mdMCI-E and their a-mdMCI counterparts with retrieval impairment only (a-mdMCI-R), since the former are more prone to AD progression that the latter. We discuss the validity of pause analysis in the prediction of MCI outcome in the AD spectrum, contributing to the refinement of the current clinical profile of MCI due to AD and to the race for non-invasive, low-cost diagnostic tools for dementia diagnosis.
1. Materials and methods
1.1. Participants
Patients were recruited prospectively and retrospectively through the Neurology units of the Hospital General de Hospitalet de Llobregat (Hospitalet de Llobregat), Hospital Moisés Broggi (Sant Joan Despí) and Hospital Clínico San Carlos (Madrid) during the period 2015 to 2019. Healthy controls included patients’ relatives and volunteers. A total of 112 participants aged 58 to 91 were recruited for the purpose of this study.
Probable AD diagnosis was based on the criteria of the National Institute of Neurological and Communicative Disorders and Stroke/Alzheimer’s Disease and Related Disorders Association (NINCDS-ADRDA) [95] and the National Institute on Aging and Alzheimer’s Association (NIA-AA) [96] for the retrospective and prospective cohort, respectively. All patients included in this group (n = 26) had a Clinical Dementia Rating (CDR) [97] score of 1.
56 subjects with MCI were diagnosed according to Petersen criteria [98] in the initial cohort and NIA-AA criteria [99] for prospective participants. More specifically, patients were of the amnestic-multidomain MCI subtype (a-mdMCI) with a CDR score of 0.5. Patients in this group were further classified into two groups according to their memory impairment profile at the Rey Auditory Learning Test (RAVLT) [100]. One subgroup displayed impaired delayed recall but normal recognition memory (deficit in retrieval processes, a-mdMCI-R, 28 participants), and the other one showed both impaired delayed recall and recognition memory (deficit in encoding processes, a-mdMCI-E, 29 participants) [22]. As explained in the introductory section, the latter pattern of impairment has been observed to be more prone to AD progression [23,101]. Follow-up of 16 of the 29 a-mdMCI-E patients and of 18 of the 28 a-mdMCI-R participants revealed that 10 (55%) of the former progressed to AD diagnosis within three years, whereas only one a-mdMCI-R patient (6%) followed the same course.
Additionally, 29 age-matched cognitively unimpaired participants, with no history of neurological disease and a minimum Mini Mental State Examination (MMSE) [101] score of 25 were also recruited as healthy controls (HC). Confirmation of any other neurological condition, history of psychiatric disorder, alcohol abuse or the use of any medication or systemic disease that might justify the observed cognitive impairment was considered a motive for exclusion. None of the participants suffered any visual or hearing impairment that could affect their performance.
1.2. Standard protocol approval and patient consent
The study was approved by the Bioethics Committee of Universitat de Barcelona (IRB00003099), by the clinical research ethics committees of Hospital Clínico San Carlos (ref. 19/046-E) and by the Consorci Sanitari Integral-Hospital Universitari de Bellvitge in the case of Hospital General de l’Hospitalet de Llobregat (ref. 19/43-PR222/19). All participants signed a written informed consent form prior to enrollment in the study.
1.3. Neuropsychological protocol
Patient assessment included, in addition to MMSE [101] and the Rey Auditory Verbal Learning Test [100], the 60-item version of the Boston Naming Test (BNT) [102], direct and reverse WAIS digits and Block Design test [103], category (animals) and letter fluency (letter p), the clock-Drawing test [104] and Poppelreuter’s Overlapping Figures Test [105]. Biographic memory was evaluated by means of a five-item questionnaire requesting two important dates-usually a wedding and a relative’s birthdayand the names of three famous people. During the same testing session participants were asked to complete the picture description task of the Bilingual Aphasia Test [106], based on a simple six-picture story depicted on a single sheet of paper – see Figure 1–.

1.4. Participant characteristics
Participant mean age was 76 ± 7 years of age and mean years of education was 6 ± 3 years. Patients in the AD group were significantly older (81 ± 6) than HC (76 ± 8) and both the a-mdMCI-R (75 ± 7) and the a-mdMCI-E (76 ± 5) groups, F(3, 111) = 4.58, p < 0.05. There were significant differences in years of education across groups (H(3) = 16.11, p < 0.05) since AD patients (5.6±2.5) and participants in the a-mdMCI-E group (6.1 ± 2.9) had significantly less years of education than HC (8 ± 2). MMSE scores differed significantly (H(3) = 64.23, p < 10−3), with individuals with AD obtaining the lowest mean score (21.8 ± 2.5), which was significantly lower than that of HC (29 ± 1.2), a-mdMCI-R patients (27.4 ± 2.3) and individuals with a-mdMCI-E (25.5 ± 2.6). a-mdMCI-E patients scored significantly lower than HC at MMSE (Bonferroni correction and Dunn post hoc test, p < 10−3). More detailed information on the demographic characteristics of the sample are provided in Table 1.
1.5. Neuropsychological profile
Regarding the two a-MCI groups, patients with a-mdMCI-E performed significantly worse than subjects with a-mdMCI-R at MMSE. The only other significant differences between the two groups were observed in their RAVLT performance, with a-mdMCI-E obtaining significantly lower total and delayed recall scores than patients with a-mdMCI-R. No significant differences were found between the two groups in any other cognitive domain as per their scores at BNT, WAIS digit span (direct and reverse), semantic and phonological fluency, WAIS III blocks, Clock Drawing Test, Poppelreuter’s Overlapping Figures Test and remote memory. Patients with AD performed significantly worse than patients in the two a-MCI groups at every test except the two WAIS digits tasks, where no differences were observed amongst the groups of study. Full details and pairwise comparison results are provided in Table 2.
1.6. Data acquisition and segmentation
Oral narratives were recorded in a quiet room in hospital by means of a SONY IICD-SX78 recorder at a sampling frequency of 44.1 kHz and subsequently processed in Praat [107] at the same sampling frequency. Audios were transcribed and annotated manually by the first author to allow pause tally and duration extraction by means of a script designed ad hoc.
Pauses were defined as any filled or silent interruption of the speech flow that could not be identified as a linguistic item (such as a disfluency) or as a false start. Filled pauses were thus standardized place-holders that were not lexicalized such as “uhm” or “erm”, as opposing filler expressions such as “bueno” (“well”) or the strategic lengthening of conjuctions, which were labelled as fillers and included in the disfluency tally. While some authors consider these vocalized pauses disfluencies [108,109] or fillers [110,111,112], most studies in the speech and dementia literature count them as filled pauses when explicitly described [69,61,113]. The lower temporal threshold for pause segmentation was set at 50 milliseconds.
1.7. Interrater agreement
With the purpose of testing the coherence and replicability of the annotation system 10% of the original 112-narrative corpus (10 narratives) were transcribed and annotated by the fifth author. Comparison of word-by-word transcriptions reached an agreement level of 97.5%, whereas interrater agreement at pause identification was 99.04%. The mean absolute difference of duration measures between the two annotators was 17 ms with a Pearson correlation coefficient of 0.99.
1.8. Truncated distributions
Following previous work [89], we here consider three possible candidate families of long tail probability density distributions, being all of them defined with two parameters: Lognormal distribution (LND), Gamma distribution and Weibull distribution. LND is known to be generated by multiplicative processes but also additive processes when some conditions are met, as seems recently shown to happen in speech [89]. LNDs are present in many natural systems [114] and have as a property that, being X an independent continuous random variable generated by a LND, then the logarithm of X is normally distributed. LND, Gamma and Weibull distribution functions are defined as follows:
Lognormal distribution:

Gamma distribution:
being Γ the gamma function.Weibull distribution:
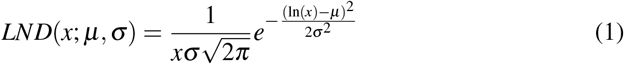
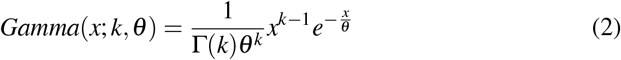
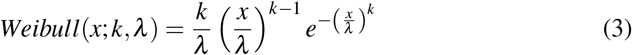
A truncated probability distribution is a distribution whose observations are reduced to some specific range. This technique is particularly useful when it is not possible to have reliable samples for the entire range but the underlying generating dynamic is expected to remain stable, so that the full distribution can be fitted into the truncated observed range. This may be the case for speech segmentation, where shorter samples are subject to higher uncertainty due to factors including Automatic Speech Alignment limitations [115], manual segmentation bias [89] and speaker-driven mixed statistical artifacts (see SI in [89]).
1.9. Statistical analysis
Omnibus between-group differences were assessed using one-way ANOVA or Kruskal-Wallis tests as appropriate, followed by pairwise testing with Student T or Mann-Whitney U where applicable.
Lower cut-off point selection when fitting long tail distributions –as those that appears in speech pause duration– is a challenge that has been widely discussed over the last years [116]. In this regard, there has been some agreement on fitting the parameters of the distribution by maximum likelihood estimation (MLE) [117] and using Kolmogorov-Smirnov distance for cut-off point selection [118]. First, for model selection we pick several lower cut-off candidates and fit by MLE the three families of probability density function with the two parameters explained above (Lognormal, Weibull and Gamma). Then Akaike Information Criteria (AIC) and Bayesian Information Criteria (BIC) were used for model selection. Goodness of fit is checked by Kolmogorov Smirnov (KS) testing as to whether reject the distribution or not at the significance level of p = 0.05.
Then, we refine the search for the lower cut-off point for the Lognormal distribution by using the method proposed by [119], which is a modified version of [116]. The procedure is as follows. (i) First pick any lower cutoff threshold value, (ii) Fit, by MLE the truncated lognormal distribution to the range x >threshold. This lead to the fitted parameters µ and σ. (iii) Compute Kolmogorov-Smirnov distance D between the theoretical distribution with estimated parameters and the real data. (iv) Stochastically generate the same number of samples but from the fitted distribution. (v) Compute Kolmogorov-Smirnov distance Dr between stochastic data and the theoretical distribution. (vi) Repeat 1000 times steps iv and v counting the number of times where Dr < D. Repeat this process for different lower cut-off points and select the one where Dr < D happens fewer times. Note that [116] showed that there will be a minimum.
2. Results
2.1. Speech pause duration distribution analysis
We fit pause duration observations from each patient group into three possible theoretical truncated distributions using MLE: Lognormal (LND), Gamma, and Weibull. We use goodness of fit AIC and BIC for model selection (where the lowest the better, see table 3), confirming that, for all cases, pause duration distribution is better explained by a LND. These results are in line with previous reported analysis in speech [89,115].
Lower cut-off point has been calculated following the procedure explained in section 1. Inset panel of Figure 2 shows that there is a minimum on the times that Dr < D (ρ) at 160 ms which will be chosen as lower threshold. Moreover, main panel of Figure 2 shows the mean relative error between speech pause annotations (blue bars and line) is drastically reduced for speech pauses longer than approximately 150ms, while interrater disagreement (1− interrater agreement) is rapidly decreased for pauses longer than 100ms. Total number of pauses for each group after the truncation is reflected in table 3, being 736 for HC, 679 for a-mdMCI-R, 618 for a-mdMCI-E and 669 for AD.

Interrater disagreement (1-interrater agreement) quickly decreases after 100ms, while mean relative error of speech pauses that coincide between annotators is quickly reduced after 150ms. The inset panel shows cut-off point selection where ρ reach a minimum at 160ms [116,119].
In addition to this, Kolmogorov Smirnov testing confirms the goodness of fit of the LND at a 95% confidence interval. This can be observed in Figure 3 with the empirical probability of pause duration distribution represented in bars for each group and their fitted truncated LND with solid lines. For the sake of clarity we also provide log-linear representations in the inset panels, where the shape of the LND turns to Gaussian. Estimated LND parameters are listed in table 3, showing that:
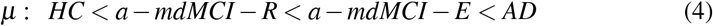
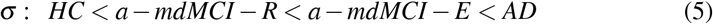 where µ represents in LND the multiplicative mean and σ is related to more sparse samples, clearly showing that the HC group has a higher probability of making short pauses with a lesser deviation than AD patients (table 3), being mild cognitive impairment groups between them with a-mdMCI-E closer to AD.
where µ represents in LND the multiplicative mean and σ is related to more sparse samples, clearly showing that the HC group has a higher probability of making short pauses with a lesser deviation than AD patients (table 3), being mild cognitive impairment groups between them with a-mdMCI-E closer to AD.

For each patient group, the main panel shows in linear axes the probability time duration distribution of pauses –bar representation– and the ML fitted truncated LND. The inner panels are a visual representation of the same results with logarithmic binning and log-linear axis.
Finally, in Figure 4 we represent truncated LNDs with estimated parameters for each group revealing that HC shows higher likelihood of making pauses at range 200ms −700ms in relation to their total pause production than the AD group, with firstly a-mdMCI-E and subsequently a-mdMCI-R interestingly standing between AD and HCs in the probability gradation. This is just the opposite at longer ranges (t > 1.5s), where AD patients reveal higher probability than HCs to make long pauses, with the two a-mdMCI groups again performing mid-range and a-mdMCI-E participants displaying a more resembling performance to that of AD patients. Dotted lines represent the continuation of the LNDs out of the truncated range and inner panels express the same results through their log-linear representation.

The main panel displays the truncated LND-fitted time duration distribution for each group. The HC group shows a higher probability of making short pauses (200-600 ms) than the AD group, while AD patients show the opposite pattern with a higher probability of making long pauses (1.5s - 2.5 s) than HC (tail of the distribution). Interestingly, a-mdMCI-E and a-mdMCI-R always stand in the middle of the continuum for both pause types. Solid lines represent the range with reliable observations, while the dotted line represents the continuation of the LND to shorter timescales. The inner panel shows the same results on the log-linear axis.
Two sided Kolmogorv-Smirnov testing has been used under the null hypothesis that different group samples come from the same distribution and that differences are due to stochastic variations, confirming in all paired cases that differences are significant, therefore rejecting the null hypothesis (see table 5).
3. Discussion
We have characterized the probability density distribution of speech pauses in AD, healthy controls, and two aMCI groups with differential memory impairment profiles, being able to show significant differences across all groups. A gradation has been found in the parameters and shape of the LNDs from AD to HCs, with a-mdMCI-E and a-mdMCI-R standing in the middle of the continuum between those groups (inequations 4 and 5). Moreover, this issue has been addressed in a censoring context affecting shorter pauses which, as it has been shown, lack the reliability of shorter pauses in terms of interrater agreement. For this purpose, we have considered the latest discussions on the fitting of long-tailed distributions [116,119], successfully recovering LNDs for pauses longer than 160ms.
Previous discussions addressing the use of these distribution type have proposed temporal thresholds differentiating short pauses from long speech pauses setting this barrier at 268ms [94], 323ms [120] or more recently at 338ms [93]. However, other authors have suggested up to three pause types: short (< 200ms), intermediate (200 − 1000ms) and long pauses (> 1000ms) [90]. The classification of “short” and “long” pauses was long reduced to a conceptual discussion about articulatory and/or respiratory (short) pauses on the one hand, and (long) cognitive pauses on the other [121,122]. This theoretical positioning has long gone undisputed-save for some exceptions, see [123,124]-but is currently under question as technical improvements allow for more precise location and measurement of pauses [93,120], and other topics of research has been recently open [125]. We have shown that shorter ranges are affected by higher mean relative errors and lower interrater agreement, which in turn may affect the conclusions drawn from the data (Figure 2). This led us to apply a quantitative method that determines a minimal threshold for pause duration (160ms) so that only occurrences beyond that point are considered, a method that can be applied beyond the study of the verbal production in AD. In any case, studying only pauses beyond that threshold may have sense in the context of Alzheimer’s disease as it has been discussed to be related with cognitive generation processes.
Pause duration distribution in speech is adequately explained with a LND that can be inferred with the help of truncated distributions, even when information on shorter ranges is incomplete or censored. To the best of our knowledge, this is the first study where the shape of the lognormally-fitted pause duration distribution is used in the classification of different groups with cognitive impairment in the context of AD. More concretely, the shape and parameters of the LND allow the detection of significant differences in the probability distribution of pauses according to duration across all groups of study (HC, a-mdMCI and AD patients). This pause duration distribution reveals the existence of a continuum from the group with the highest probability of producing short pauses (HC) to the group with the highest probability of making long pauses (AD patients), with a-mdMCI-R performing in the range between HCs and a-mdMCI-E and the latter showing a production pattern more resemblant to that of AD (Figure 4). The confirmation of a higher likelihood to produce more long pauses and less short pauses for those in the group with higher probability of AD progression (a-mdMCI-E) in comparison to the a-mdMCI-R group suggest a new promising tool for dementia prognosis that should be addressed in further studies.
The finding that patients with a-mdMCI-E produce significantly longer pauses with more variance than HC confirms our initial hypothesis and is in line with previous findings [69,59,82]. The gradation found along the AD spectrum and more specifically within the a-mdMCI subtype initially suggests a central role of memory degradation as reflected in the impaired delayed recall and recognition observed in the a-mdMCI-E group in comparison to a-mdMCI-R. Previous studies including correlation analyses of neuropsychological scores and pause duration suggest that longer pause durations arise from difficulties in the retrieval of relevant information from episodic memory both in AD [79] and in MCI due to AD [82], a cognitive domain particularly affected in AD that is compatible with the impaired encoding and consolidation processes observed in our a-mdMCI-E participants.
The fact that other studies using memory-taxing speech tasks failed to find significant differences in mean pause duration [59,68] invites for further enquiry as to criteria for pause labelling and analysis. Our picture description task [106] does not exert the same level of demand on recent anterograde memory while still managing to capture fluency impairments in a-mdMCI patients, in line with previous studies also implementing picture description tasks [59,83,60,64]. In light of this evidence and considering the well documented constellation of semantic and lexical processing deficits in AD [126,127,128,129,130], our results suggest a generalised, more profound deterioration of the memory system from the preclinical stages of Alzheimer’s disease. Our elicitation task successfully taps onto these emerging deficits by imposing a controlled lexicosemantic setting that is also demanding on working memory for discourse building and task maintenance, testing other dimensions of memory in addition to episodic anterograde memory and verbal learning, –which are clearly impaired in these patients– avoiding thus circularity in their diagnosis, which is already based on verbal memory assessment. In MCI the fluency factor is highly correlated with memory measures [60] but to an even greater degree with BNT score (a picture-based test of lexical and semantic memory integrity). However, [64] failed to find such correlations between fluency parameters and psycholinguistic measures in very early MCI. These differences may be the reflection of different stages of the progressive degradation of memory and language that takes place in AD, that in the case of our a-mdMCI-E sample would be at a more advanced phase given their neuropsychological profile and the fact that a considerable number of these individuals progressed to Alzheimer’s dementia within three years (see 1.1. Section). Our two a-mdMCI groups only differed significantly in their memory and pause profile while there were no significant differences in number of months since MCI diagnosis, which suggests that they represent two distinct subtypes with not only differential progression rates, but also eventual outcome and, therefore, prognosis.
While LNDs are very common manifestation in natural sciences, the particular generative process involved in showing this manifestations in speech pause distributions are still not known. Further than being the reminiscence of an unknown multiplicative process, they could be the result of an additive process under some specific constrains [89] or a pattern result of specific neural activity [131]. However, further studies should be carried out to fully understand the production processes and how their deviations are related with healthy disorders. Future studies should also consider the inclusion and comparison of different speech-eliciting tasks in order to clarify the role of memory in the linguistic behaviour of patients in the AD spectrum and evaluate the relative weight of other deficits that might also be at play, in addition to confirming the applicability of this methodology in the design of tests that may serve as early low-cost markers in dementia detection.
Data Availability
The speech pauses duration corpus used in this study and scripts that ensure reproducibility of all results are public available in https://github.com/ivangtorre/Speech-pause-distribution-as-an-early-marker-for-Alzheimers-disease. The full complete corpus may be accessible under some considerations upon request to the main author. We have used Python 3.8.2 and R 3.6.3 for the analysis. MLE fit, Kolmogorov-Smirnov AIC and BIC make use of fitdistrplus 1.1.1 and truncdist 1.0.2. Numpy, Pandas and Matplotlib libraries are also used. Some other statistical analyses were performed on IBM SPSS 25.0. Replicability of the study is addressed through Section 1 (Material and Methods) of the present paper.
https://github.com/ivangtorre/Speech-pause-distribution-as-an-early-marker-for-Alzheimers-disease
https://github.com/PatriciaPast/Speech-pause-distribution-as-an-early-marker-for-Alzheimers-disease
5. Disclosure Statement
The authors have no conflict of interest to report.
6. Reproducibility and replicability
The speech pause duration corpus used in this study and scripts that ensure reproducibility of all results are public available in https://github.com/ivangtorre/Speech-pause-distribution-as-an-early-marker-for-Alzheimers-disease and https://github.com/PatriciaPast/Speech-pause-distribution-as-an-early-marker-for-Alzhei The full complete corpus may be accessible under some considerations upon request to the main author. We have used Python 3.8.2 and R 3.6.3 for the analysis. MLE fit, Kolmogorov-Smirnov AIC and BIC make use of fitdistrplus 1.1.1 and truncdist 1.0.2. Numpy, Pandas and Matplotlib libraries are also used. Some other statistical analyses were performed on IBM SPSS 25.0.
Replicability of the study is addressed through Section 1 (Material and Methods) of the present paper.
4. Acknowledgements
This work is supported through a PhD grant awarded to P.P-D. by the banking Foundation “La Caixa” (ID 100010434, code: LCF/BQ/ES15/10360020). F.D-V. was supported by a grant awarded to project no. PID2019-107042GB-I00 (Ministerio de Ciencia e Innovación). A.H-F. and I.G.T. were supported by the grant no. TIN2017-89244-R (MACDA) (Ministerio de Economia, Industria y Competitividad, Gobierno de Espanã) and the project PRO2020-S03 (RCO03080 Lingüística Quantitativa) of l’Institut d’Estudis Catalans.
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].↵
- [72].↵
- [73].↵
- [74].↵
- [75].↵
- [76].↵
- [77].↵
- [78].↵
- [79].↵
- [80].↵
- [81].↵
- [82].↵
- [83].↵
- [84].↵
- [85].↵
- [86].↵
- [87].↵
- [88].↵
- [89].↵
- [90].↵
- [91].↵
- [92].↵
- [93].↵
- [94].↵
- [95].↵
- [96].↵
- [97].↵
- [98].↵
- [99].↵
- [100].↵
- [101].↵
- [102].↵
- [103].↵
- [104].↵
- [105].↵
- [106].↵
- [107].↵
- [108].↵
- [109].↵
- [110].↵
- [111].↵
- [112].↵
- [113].↵
- [114].↵
- [115].↵
- [116].↵
- [117].↵
- [118].↵
- [119].↵
- [120].↵
- [121].↵
- [122].↵
- [123].↵
- [124].↵
- [125].↵
- [126].↵
- [127].↵
- [128].↵
- [129].↵
- [130].↵
- [131].↵




{kind=link}
{kind=link}
{kind=link}
{kind=link}