
Abstract
Multiple clinical phenotypes have been proposed for COVID-19, but few have stemmed from data-driven methods. We aimed to identify distinct phenotypes in patients admitted with COVID-19 using cluster analysis, and compare their respective characteristics and clinical outcomes.
We analyzed the data from 547 patients hospitalized with COVID-19 in a Canadian academic hospital from January 1, 2020, to January 30, 2021. We compared four clustering algorithms: K-means, PAM (partition around medoids), divisive and agglomerative hierarchical clustering. We used imaging data and 34 clinical variables collected within the first 24 hours of admission to train our algorithm. We then conducted survival analysis to compare clinical outcomes across phenotypes and trained a classification and regression tree (CART) to facilitate phenotype interpretation and phenotype assignment.
We identified three clinical phenotypes, with 61 patients (17%) in Cluster 1, 221 patients (40%) in Cluster 2 and 235 (43%) in Cluster 3. Cluster 2 and Cluster 3 were both characterized by a low-risk respiratory and inflammatory profile, but differed in terms of demographics. Compared with Cluster 3, Cluster 2 comprised older patients with more comorbidities. Cluster 1 represented the group with the most severe clinical presentation, as inferred by the highest rate of hypoxemia and the highest radiological burden. Mortality, mechanical ventilation and ICU admission risk were all significantly different across phenotypes.
We conducted a phenotypic analysis of adult inpatients with COVID-19 and identified three distinct phenotypes associated with different clinical outcomes. Further research is needed to determine how to properly incorporate those phenotypes in the management of patients with COVID-19.
Introduction
Patients affected with coronavirus disease 2019 (COVID-19) have shown significant clinical heterogeneity and variability in disease trajectory (1). Clinical phenotypes are homogeneous subgroups of a disease presenting distinct clinical features (2). Well-established phenotypes are potentially useful at the bedside for appropriately classifying patients into meaningful categories, predicting disease course, and personalizing treatments.
Since the first case description of COVID-19, various phenotypes have emerged, each using various layers of clinical information. Two phenotypes have been described based on lung mechanics and radiological findings (3,4), others have focused on disease complications—as such, a hypercoagulable phenotype has been observed, prompting recommendations for intensified antithrombotic therapy (5–7).
The majority of those phenotypes failed to fully describe the complexity of the disease as they focused on characterizing one dimension of the clinical presentation. Being mostly derived from clinical observation, or based on outcomes that can only occur in the future is however potentially less relevant in a prospective and real-world context. Thus, the reliability and the methodology of those first phenotyping efforts have been put into question (8,9). Increasing amounts of medical data allow conducting phenotypic analyses using data-driven techniques. Those methods are hypothesis-agnostic and solely rely on the assumption that clinical patterns lie within the data (10). Clustering is an unsupervised machine learning method used to identify homogeneous groups within a heterogeneous dataset. This method has been used to describe clinical phenotypes in other diseases such as asthma (11,12), COPD (13) and sepsis (14).
The primary objective of this study was to identify COVID-19 cluster of phenotypes at patient presentation using multimodal real-world clinical data and medical imaging data (15). Our secondary objectives were to assess the association of those phenotypes with three clinical outcomes: mechanical ventilation (MV), intensive care unit (ICU) admission and hospital mortality. Finally, we created a simple decision tree classifier allowing the interpretation and assignment of patients to one of the identified phenotypes.
Methods
Data sources
We used real-world data extracted from clinical source system comprising relevant clinical information from all COVID-19-related hospitalizations at the Centre for the Integration and Analysis of Medical Data (CITADEL) of the Centre Hospitalier de l’Université de Montréal (CHUM), a Canadian academic quaternary center. The analytical dataset contains de-identified data for over 1,100 patients hospitalized with COVID-19, including demographics, comorbidities, laboratory results, vital signs, drugs, medical procedures, frontal chest radiographs (CXR) and clinical outcomes. The raw data was managed using SQLite 3, and further data processing was conducted using Python version 3.7 and R version 4.0.3. We provided additional details regarding initial data processing. (see S1 text, supplementary methods).
Study population
We included all unique adult hospitalizations (≥ 18 years of age) for COVID-19 from January 1, 2020, to January 30, 2021, for which a chest X-ray was available within 24 hours of admission. A COVID-19 hospitalization episode was defined as a hospitalization within seven days of a positive SARS-CoV-2 PCR result. The Institutional Review Board of the CHUM (Centre Hospitalier de l’Université de Montréal) approved the study and informed consent was waived because of its low risk and retrospective nature.
Imaging Data Processing
Imaging data were obtained in the DICOM format, and frontal CXR (posteroanterior and anteroposterior) were processed, discarding lateral CXR. Lung opacities observed on CXR were manually annotated with bounding boxes by a board-certified radiologist using a bounding box annotation software (16). This annotation method is recognized by the Radiological Society of North America (RSNA) and is the annotation methodology of choice for all deep learning challenges involving image detection (17,18). Bounding boxes are rectangular or squared delimitations of the opacities found on a given chest radiograph reported with a scaled width and a scaled length. Hence, from the manual annotation, we derived the number of opacities and the total size of opacities as a relative percentage of the total surface of the image.
Variables Selection and Feature Engineering
From the analytical dataset, we extracted 160 candidate variables. We provided the list of those variables in the supplementary material (see S1 Table). For each of those variables, we exclusively used the first recorded value within the first 24 hours of admission. We then excluded 56 variables for which more than 25% of observations were missing. The remaining missing variables were imputed using all available features except clinical outcomes (ICU admission, mechanical ventilation and death). We used classification and regression tree (CART) single mean imputation, a robust method against outliers, multicollinearity and skewed distributions that has the benefit of being simple to implement in a real-world setting (19). We acknowledge that other imputation algorithms such as Expectation Maximization (EM) and Multiple Imputation (MI) have shown superior performance but the additional computational cost makes those approaches difficult to implement in a real-world setting (20).
We then computed three more variables that have recently been associated with COVID-19 mortality: neutrophil-to-lymphocyte ratio (NLR) (21), the ratio of peripheral arterial oxygen saturation to the inspired fraction of oxygen (SpO2/FiO2) (22), and the shock index (heart rate/systolic blood pressure) (23). We also computed the Medicines Comorbidity Index (MCI), a metric to assess multimorbidity that has shown similar epidemiological value to the Charlson Comorbidity Index (CCI) (24). We relied on the MCI instead of the CCI because comorbidities were not systematically recorded in our database, but home medications were (see S1 Table). MCI was computed at the time of study enrollment only using data that was available on presentation to mimic real-world setting. We summarized the final set of variables included for analysis with their respective subdomains of interest in Table 1.
Despite receiving little attention, feature engineering in clustering efforts has shown to increase learning performance through dimensionality reduction (25). In the healthcare setting, aggregated variables such as the one included in our algorithm also enhances the stability of a learning model’s performance over time (26). In addition to the statistical advantages mentioned, feature engineering also allows for better interpretability, as aggregated variables are often clearer and more intuitive. Pre-processed variables do not impede the hypothesis-agnostic premise of unsupervised machine learning, as all these variables are directly derived from the features of the original dataset and no preferential weighting was conducted.
Data Preparation and Cluster Analysis
Before applying clustering algorithms, we adequately processed our dataset, log-transforming skewed continuous variables (skewness > 0.5) and excluding highly correlated variables (correlation > 0.8). The then obtained principal components via factor analysis of mixed data (FAMD) (27) for all our observations. The excluded variables based on high correlation were the total white blood cell count (WBC), the Fraction of Inspired Oxygen (FiO2) and the heart rate (HR). Those three variables were respectively highly correlated with neutrophils, the SpO2/FiO2 ratio and the shock index. We provided additional details regarding the data preparation in the supplementary material (see S1 text).
We compared four clustering algorithms: K-means, PAM (partition around medoids), divisive and agglomerative hierarchical clustering. We used three internal validation metrics (connectivity, Dunn index, the average silhouette width) and four stability measures (average proportion of non-overlap (APN), the average distance (AD), the average distance between means (ADM), and the figure of merit (FOM)) to compare the algorithms. The optimal algorithm and the optimal number of clusters were then determined by rank aggregation of the ranked lists of each validation metric. We used the optCluster package, an R package facilitating the execution of the aforementioned analyses (28).
Phenotypes Robustness: sensitivity analyses
We conducted a sensitivity analysis to assess whether the removal of imaging data altered the performance of the clustering algorithm. We first compared the clustering results given these two scenarios using the average silhouette width and the adjusted rand index (29), a measure of the similarity between two data clustering. We then assessed the number of patients that underwent phenotypic reclassification before and after the removal of imaging data in the clustering algorithm. In other words, we analyzed the characteristics of patients for which the cluster assignment differed after the removal of imaging data.
Statistical Analysis
Clusters Interpretation
We assessed the difference in the distribution of features across identified clusters using the Chi-Square test for categorical variables, analysis of variance (ANOVA) and Kruskal–Wallis test for normally distributed and non-normally distributed continuous variables respectively.
To facilitate the interpretation and clinical usability of the obtained clusters, we trained a simple decision tree using the CART with the clusters as predicted outcomes (30). We also determined the most critical variables to distinguish the clusters by conducting a variable importance analysis (VIA) (31). Details regarding VIA were provided in the supplementary material (see S1 text, S1 Figure).
Clinical Outcomes Evaluation
We conducted survival analysis using Kaplan-Meier method to compare clinical outcomes according to clusters. We assessed three clinical outcomes: 7-day ICU admission, 7-day mechanical ventilation and 30-day mortality. To reduce confounding bias, we specifically restricted clinical outcomes analysis to patients eligible for MV and ICU admission according to their Physician Orders for Life-Sustaining Treatment (POLST) form.
Results
Study Population
In total, 1,125 unique COVID-19 hospitalizations were screened. A total of 559 patients were excluded after removing readmissions (n = 36), patients without a CXR within 24 hours of admission (n = 523), and patients for which clinical data was missing (n = 19), leaving 547 patients for the cluster analysis (see Fig 1). We provided details regarding the characteristics of our study cohort (see Table 2). Our population was similar to other cohorts of patients hospitalized with COVID-19 in North America during the first two waves, with a mean age of 69 years old, a relatively similar proportion of men and women, and an in-hospital mortality rate of 20% (32).
Baseline characteristics of the study population.

Study Inclusion and Exclusion Criteria
Clinical Characteristics of Phenotypes
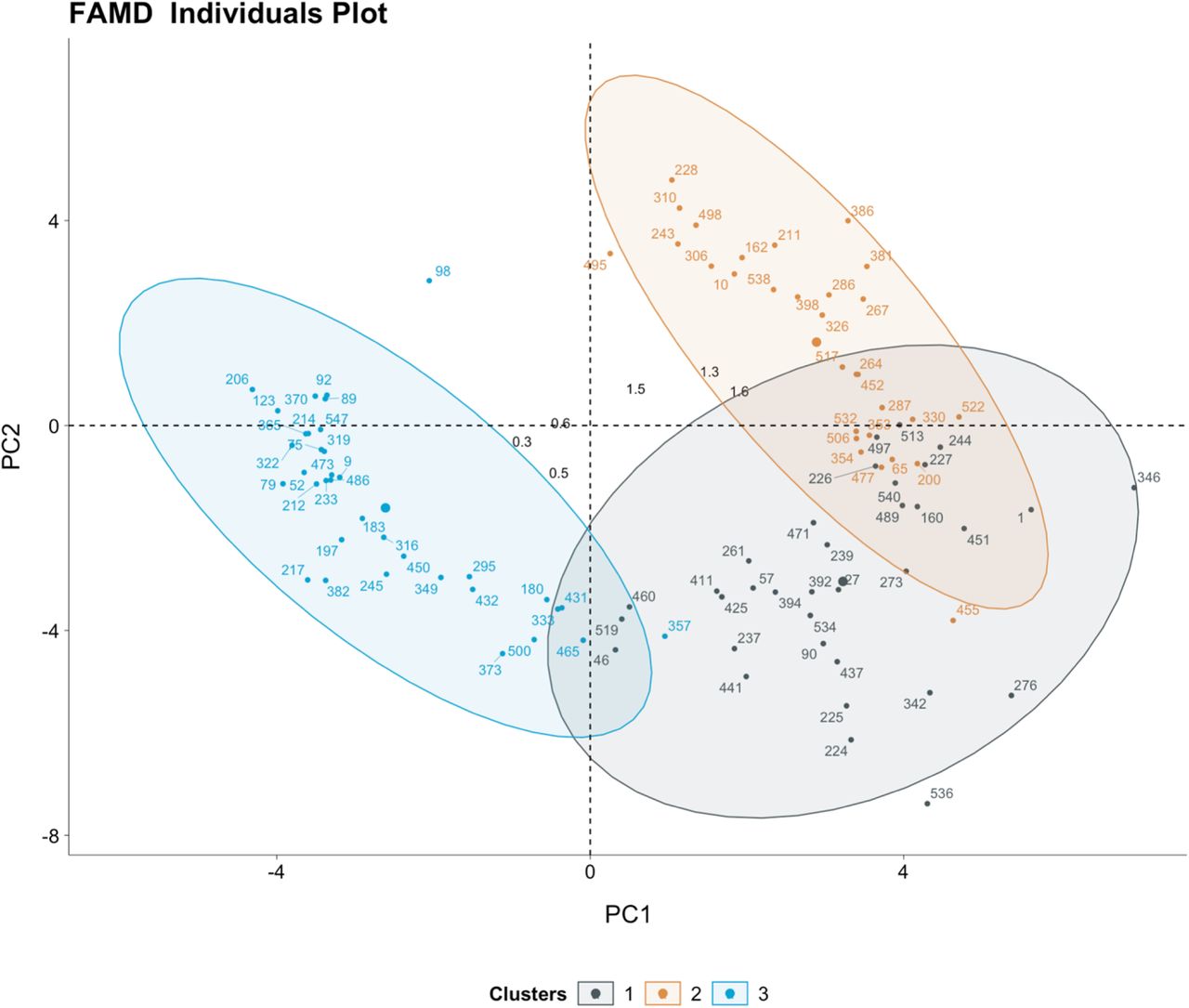
Agglomerative hierarchical clustering was deemed the most robust clustering algorithm for our dataset. The optimal number of K clusters was K = 3 (see Fig 2), yielding the highest clustering performance as exhibited by the rank aggregation of seven internal validation measures (see S2 Figure, S2 Table).

Clusters visualization on factor analysis of mixed data principal components plot
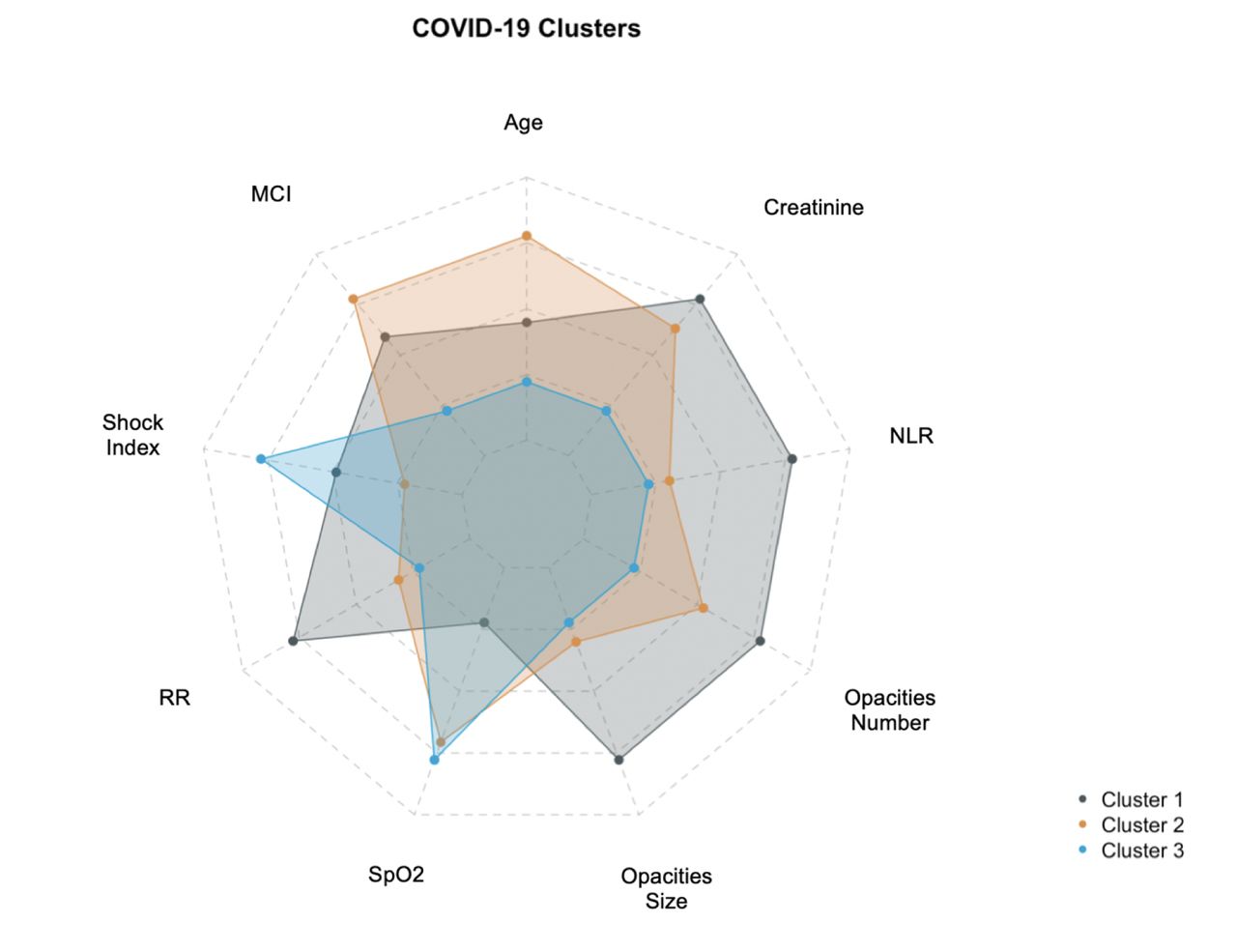
We summarized the characteristics regarding those clusters in Table 3. As determined through the VIA, the most important variables for discriminating clusters were age, the MCI, the SpO2/FiO2 ratio, opacities size, the neutrocyte-lymphocyte ratio, creatinine and the shock index (see Figures 3A-3B).

Radar Plot showing the distribution of clinical variables across clusters

Bar Plot showing the distribution of clinical variables across clusters
In both figures, the variables were scaled using normalization. Non-continuous variables underwent log-transformation if the skewness was > 0.5 and the respective mean of each scaled variable was plotted.
Cluster 1 (n = 61, 11%) represented the group of patients with the most severe presentation having the highest NLR (median 13.5), the highest rate of hypoxemia (median SpO2/FiO2 118) and the highest radiographic burden, with 91% of patients with at least two pulmonary opacities and a median total opacities size of 20% (ratio of opacities area/total CXR area).
Cluster 2 (n = 211, 39%) and Cluster 3 (n = 275, 50%) were similar regarding the respiratory, hematologic and hemodynamic subdomains. They both presented milder clinical manifestations than Cluster 1, but both phenotypes differed in terms of demographics. Cluster 2 represented the oldest cohort (mean 75.4 years) and Cluster 3 represented the youngest cohort (mean 59.8 years). They also differed by MCI, as Cluster 2 represented the group with the highest proportion of comorbidities, with a mean MCI of 4.30, compared to 1.47 for Cluster 3. Accordingly, Cluster 2 included patients with high proportions of concurrent medication on admission: 68% took anti-hypertensive agents, 63% hypolipemiant agents, 56.9% hypoglycemic agents, 53.6% antiplatelets agents and 37.4% bronchodilator agents.
Phenotypes and clinical outcomes
Among the 547 patients in our study cohort, 436 patients were eligible for ICU admission and MV as deemed by their POLST form, and were thus analyzed for clinical outcomes (see Fig 1).
The cumulative mortality risk was significantly different across clusters (log-rank test, p = 0.01). The 30-day mortality risks were respectively 39% (21-53%, 95 CI), 33% (22-43%, 95 CI) and 20% (10-28%, 95 CI) for clusters 1, 2 and 3. The difference in cumulative ICU admission risk and cumulative mechanical ventilation risk were also statistically significant across all clusters (log-rank test respectively, p< 0.0001 and p< 0.0001). More precisely, the 7-day ICU admission risk was 74% (60-83%, 95% CI) for Cluster 1, 28% for Cluster 2 (20-35%, 95% CI) and 21% (15-26%, 95% CI) for Cluster 3. The 7-day mechanical ventilation risk was 58% (43-70%, 95% CI) for Cluster 1, 14% (8-19%, 95% CI) for Cluster 2 and 11% (6-15%, 95% CI) for Cluster 3 (see Fig 4).



Kaplan-Meier curves for clinical outcomes (a) death, (b) ICU admission, and (c) mechanical ventilation stratified by phenotypes.
Phenotypes Interpretability and Assignment
We developed a simple decision tree that allows the assignment of patients to their respective clinical phenotypes using the rules shown in Fig 5. Using only four variables (age, MCI, SpO2/FiO2, opacities size) and by following between three and five steps, one can assign a patient to one of the three phenotypes with an accuracy varying between 63 and 100% according to the given path.

Clusters assignment through decision tree-based rules
This graphs represents the classification rules obtained after training a CART decision tree algorithm with the phenotypes as outcomes. The rules obtained could be used at the bedside to determine the phenotype of a given individual following simple steps.
The rules are located in the white squared boxes and each colored node box displays the probability of the predicted class.
Phenotypes Robustness: sensitivity analyses
When comparing the clustering results with and without the inclusion of imaging data, the adjusted rand index was 0.55 indicating that the similarity of the two clusterings was moderate. The average silhouette width remained unchanged (0.34 with imaging; 0.33 without imaging), indicating that both approaches yielded homogeneous clusters.
We then further characterized the individuals who underwent phenotypic reclassification. 16 percent of patients (n = 87) underwent reclassification (see Fig 6), meaning that their clusters assignment changed after the removal of imaging data. The highest proportion of reclassified observations came from Cluster 1 as 32 percent of observations (n = 20) were reclassified to Cluster 2 or 3 after the removal of imaging data. When analyzing the clinical outcomes of those patients, we noted that 11 out of 20 patients died (55%). Conversely, we noted that eight patients who were initially assigned to Cluster 2 or 3, were reassigned to Cluster 1 (the most severe phenotype) after the removal of imaging data from the algorithm. All of those eight patients survived.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sankey diagram assessing clustering stability with and without imaging data
This plot shows the distribution of the patients that underwent reclassification after the removal of imaging data in the clustering algorithm. 87 observations (16%) were reclassified when ignoring imaging data. Although the clusters are relatively stable, a disproportionate number of reclassified observations originate from Cluster 1, as 20 observations (32%) were reclassified after the removal of imaging. As Cluster 1 is the most severe phenotype, the potential impact of this reclassification is not without consequences.
Discussion
We identified three clinical phenotypes with distinct clinical characteristics and outcomes using multimodal clinical data in patients admitted with COVID-19. The three phenotypes can be summarized as follows: severely hypoxemic with high radiological burden irrespective of age (Cluster 1), mildly hypoxemic with either a high comorbidity index or old age (Cluster 2), and mildly hypoxemic with a low comorbidity index (Cluster 3).
The identified phenotypes were clinically relevant as they were associated with distinct clinical outcomes. Cluster 1 included patients with the most severe presentation and was thus unsurprisingly the phenotype with the highest mortality and morbidity risk. Cluster 2 and Cluster 3 represented patients with similar milder clinical presentations but with distinct comorbidities profiles. Patients in Cluster 2 had a higher comorbidity index (4.30 vs 1.47) and the 30-day mortality was higher when compared to Cluster 3 (32% vs. 21%). Being able to distinguish phenotypes with appearing similar features, but different outcomes, is clinically meaningful. Those represent patients currently treated identically, but who might benefit from a distinct and targeted treatment approach.
When comparing our results with previous work (33–40), the number of clusters obtained is consistent, as all have identified three phenotypes. However, all cited studies have reported phenotypes suggesting a linear relationship with age and disease severity. This drastically differs from our findings, in which the most severe phenotype (Cluster 1) does not represent the oldest group. In our opinion, our phenotypes reflect the complexity of the distribution of patients with COVID-19 in which age is not the sole determinant of severity. Further research is needed to understand the virological and immunological factors associated with severe infection in this phenotype.
Despite having considered more than 30 variables in our clustering algorithm, only four subdomains were central in establishing the phenotypes: demographics, hematologic features, respiratory features, and imaging data. Socio-demographics, comorbidities (41) and hypoxemia’s (42) impact on the clinical course of patients with COVID-19 have been well documented, and their relative importance in our clustering effort was thus expected. Furthermore, neutrophil-to-lymphocyte ratio (NLR), previously identified as an independent risk predictor for mortality in COVID-19 (43), was accordingly higher in Cluster 1. On the other hand, mean platelet volume (MPV) was not found to significantly impact clustering results despite being associated with severe forms of the disease (44).
Our study emphasizes the importance of imaging data in COVID-19 related clustering efforts. Through our sensitivity analysis, we have shown that the incorporation of CXR enhanced the phenotypes’ clinical value. Even in the absence of ground truth in unsupervised machine learning, we showed that dismissing imaging data reduced the clinical accuracy of our clustering algorithm. Eight patients initially assigned to Cluster 2 or 3 were reclassified to the more severe Cluster 1 after the removal of imaging data from the algorithm. We deemed the initial assignment to the less severe Cluster 2 or 3 as the accurate one, given all eight of those patients survived. Likewise, 20 patients initially assigned to Cluster 1 were reclassified to Cluster 2 or 3 after the removal of imaging data. We deemed the initial assignment to the severe Cluster 1 as appropriate, because the mortality rate of those 20 patients (55%) exceeded those of Cluster 2 and 3 (respectively 24% and 14%). The use of imaging helped properly classify outlier patients: those who had a lower or higher radiological burden than the majority of the patients in their respective phenotypic group (see S3 Figure, S4 Figure).
To our knowledge, opacity size has not previously been used in other COVID-19 phenotyping efforts. Instead, the number of opacities has been used as a proxy variable in only one other paper (33). The number of opacities is generally more accessible as it can directly be extracted from CXR reports, and does not demand manual annotation of medical images. However, studies have shown that even though those two variables provide overlapping information, they are not interchangeable and their respective value differs when it comes to predicting survival and the need for respiratory support in patients with COVID-19 (45). Furthermore, automation of chest X-ray opacities annotation is increasingly feasible with publicly available deep-learning models harmonizing the process (17). We opted for manual annotation in this paper, awaiting further validation of those tools in the COVID-19 population. Nonetheless, chest X-ray annotation should not be viewed as a rate-limiting process. On the contrary, it should be encouraged in healthcare machine learning as it allows uniformizing the inputs during training and upon model deployment (46).
Our study highlights the feasibility and the importance of agnostic approaches to disease phenotyping with no a priori information about patient outcome.
At the bedside, clinical phenotypes help unbiasedly categorize patients. Previous studies have shown that individual risk factors taken alone are insufficient to properly stratify patients with COVID-19 (45). Phenotypes thus offer a simple, and yet holistic means to describing patients with COVID-19 while incorporating both clinical presentation and morbidity risk.
In clinical trials, phenotypes could help harmonizing enrolled participants and facilitate the identification of patients’ subgroups benefiting from a given therapy. Recent clinical trials revealed that distinct clinical presentations mandate distinct treatments, with some therapies showing benefits only in patients with severe disease (47,48). The various inclusion criteria of these trials have made it difficult for clinicians to clearly identify patients who would benefit the most from those novel interventions. The controversy regarding the benefits of anticoagulation in critically and non-critically ill patients is a testimony of this observation (49). Using standardized phenotypes could remove the ambiguous nature of patients subgrouping in future trials and facilitate the comparison of results across trials.
Our study also highlights the clinical usability of clustering-based phenotypes (50). Variables needed to assign patients to phenotypes are readily available at the point-of-care, and cluster assignment can be done following three and five simple steps. Our decision-tree model for cluster assignment would need to be externally validated before being used in the clinical setting, but it nevertheless remains helpful to understand how the three phenotypes differ and how applicable such phenotypes would be in the clinical setting. Moreover, the probabilistic nature of the algorithm allows for direct quantification of the uncertainty, which is an important factor for clinical usability of machine learning algorithms (51). We restricted our clustering effort to the data available within the first 24 hours of admission to ease generalizability and to emulate the timing of triage decision that is often made early upon admission. To our knowledge, characterizing the evolution of phenotypes over time has not been studied and would mandate further investigation.
We recognize that clinical phenotypes do not offer a comprehensive explanation model for the observed disease heterogeneity (52). However, they lay the groundwork for understanding COVID-19 pathobiology. Studies linking biobank data to clinical phenotypes allow to capture the taxonomic complexity of the disease and describe how phenotypes differ in terms of pathogenic mechanisms (53).
Our study presents some limitations. Multiple variables could not be included because they were either not captured in our electronic health record (e.g., time from onset of symptoms, mechanical ventilation parameters, in-hospital complications) or excluded from our study because of missingness. However, missing values are common in clinical practice and investigating risk stratification while considering the inherent characteristics real-world data is of importance at the bedside (54). In addition, this enhances the applicability of our phenotypes, as they are only based on the most common variables available for patients admitted with COVID-19 (55). This differs from studies that have included flux cytometry and CD4+/CD8+ count in their algorithm (34). Besides, those omitted variables do not seem to have had significant impact on our results as the three clusters obtained were consistent in numbers with previous work (33–39).
Additionally, our study included patients admitted between January 1, 2020, and January 31, 2021, being before the approval of the majority of targeted therapies against COVID-19 or vaccination. We therefore did not assess the effect of vaccination, treatments and the type of variant on phenotypes. Accordingly, this put our algorithm at risk for temporal dataset shift (56) and calibrating our clustering algorithm will be necessary before exploiting it in the clinical setting. Finally, because race-based data is not recorded in the Quebec healthcare system (57), we could not proceed to sensitivity analysis according to race. For that very same reason, we acknowledge that our work could be subject to algorithmic bias as evidence has shown racial disparities in clinical outcomes of patients with COVID-19 (58).
Conclusion
We developed a multidimensional phenotypic analysis of patients with COVID-19 and identified three distinct phenotypes, with one specifically associated with worse clinical outcomes. Our study supports the feasibility of using real-world clinical data to conduct unsupervised phenotypic clustering. External validation and further research are needed to determine how phenotypes could impact clinical trials design and phenotypic-guided treatment in clinical practice.
Data Availability
The entire code excluding the dataset is publicly available on GitHub (https://github.com/CODA-19/models/tree/master/phenotyper) The data that support the findings of this study are available on request from the corresponding author, MC.
Reproducibility
The entire code excluding the dataset is publicly available on GitHub (https://github.com/CODA-19/models/tree/master/phenotyper).
The data that support the findings of this study are available on request from the corresponding author, MC.
Disclosures
None
Supporting information
S1 text (Supplementary Methods)
S1-S3 Tables
S1-S4 Figures
Acknowledgments
M.C. is supported by a Fonds de Recherche Québec Santé (FRQS) Clinical Research scholarship. M.D. is supported by a FRQS Clinical Research scholarship. A.T. is supported by a FRQS Clinical Research Scholarship and a Fondation de l’Association des Radiologistes du Québec (FARQ) Clinical Research Scholarship. This work was possible with the contribution of the CHUM Center for Integration and Analysis of Medical Data (CITADEL).
This work was partly funded by a Quebec Bio-Imaging Network research grant. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Abbreviations
- APN
- average proportion of non-overlap
- AD
- average distance
- ADM
- average distance between means
- CART
- classification and regression tree
- CCI
- Charlson Comorbidity Index
- CXR
- chest radiographs
- FAMD
- factor analysis of mixed data
- FOM
- figure of merit
- ICU
- intensive care unit
- MCI
- Medicines Comorbidity Index
- MV
- mechanical ventilation
- NLR
- neutrophil-to-lymphocyte ratio
- PAM
- partition around medoids
- PCR
- polymerase chain reaction
- POLST
- Physician Orders for Life-Sustaining Treatment
- VIA
- variable importance analysis
References



