
Abstract
Purpose Comparison of performance and explainability of a multi-task convolutional deep neuronal network to single-task networks for activity detection in neovascular age-dependent macular degeneration.
Methods From n = 70 patients (46 female, 24 male) who attended the University Eye Hospital Tübingen 3762 optical coherence tomography B-scans (right eye: 2011, left eye: 1751) were acquired with Heidelberg Spectralis, Heidelberg, Germany. B-scans were graded by a retina specialist and an ophthalmology resident, and then used to develop a multi-task deep learning model to predict disease activity in neovascular age-related macular degeneration along with the presence of sub- and intraretinal fluid. We used performance metrics for comparison to single-task networks and visualized the DNN-based decision with t-distributed stochastic neighbor embedding and clinically validated saliency mapping techniques.
Results The multi-task model surpassed single-task networks in accuracy for activity detection and visualizations via t-distributed stochastic neighbor embedding and saliency maps highlighted that multi-task networks’ decisions for activity detection in neovascular age-related macular degeneration are indeed based on the presence of sub- and intraretinal fluids, the optical coherence tomography characteristics used for treatment decision in clinical routine.
Conclusions Multi-task learning increases the performance of neuronal networks for predicting disease activity, while providing clinicians with an easily accessible decision control, which resembles human reasoning.
Section Code RE
1 Introduction
Neovascular age-related macular degeneration (nAMD) is a sight-threatening disease affecting the elderly and among the most common causes of vision loss worldwide [38, 62, 17]. Among the basic features of nAMD are subretinal (SRF) and intraretinal fluid (IRF), which serve as surrogate markers of nAMD activity and can be monitored using optical coherence tomography (OCT) [52, 42] (Fig. 1).

Exemplary retinal images (B-scans) with neovascular age-related macular degeneration (nAMD). Solid and dotted arrows indicate subretinal and intraretinal fluid, respectively. (a): no nAMD activity. (b): nAMD activity due to subretinal fluid (SRF) (arrow). (c): nAMD activity due to intraretinal fluid (IRF) (dotted arrow). (d): nAMD activity due to both SRF (arrow) and IRF (dotted arrow).
In nAMD, increased levels of vascular endothelial growth factor (VEGF) lead to formation of new vessels from the choroidal and/or retinal vasculature. If leakage from these vessels exceeds local clearance rates, liquid builds up, leading to IRF and SRF [52]. IRF is assumed to originate from vascular leakage from intraretinal neovasculaturisation and/or retinal vasculature or from diffusion through the outer retina due to changes within the external limiting membrane [52]. In contrast, SRF formation likely results from mal-function of the retinal pigment epithelium with reduced removal rates [52]. Due to the partially different pathophysiology, IRF and SRF can occur simultaneously as well as independently from each other [52, 41]. Furthermore, different lesion characteristics based on presence of IRF and SRF have been observed to indicate the potential functional outcome [59]. For both fluid compartments, automatic detection and quantification have been shown to be possible [47].
Treatment with intravitreal anti-VEGF agents can efficiently restore the balance between liquid formation and retinal removal and are standard of care for nAMD, when IRF or SRF is detected via OCT [42]. Since delay of treatment is associated with vision loss [25, 56, 3], treatment has to be initiated promptly. Also, therapy monitoring using OCT has to take place on up to four-weekly basis in some cases until the end of life. Due to this high frequency of visits, the therapy has put a considerable burden on patients, their families and ophthalmological care since its initial approval in 2006 [14, 2, 43, 51]. Additionally, a future increased need for AMD care has to be expected, since the number of patients suffering from AMD are thought to rise from 196 million in 2020 to 288 million in 2040 [62]. Hence, automated solutions making the diagnostic processes more efficient have considerable appeal. For example, deep neural networks (DNNs) have been used for automatic referral decisions [15] and predicting disease conversion to nAMD [64]. Automated algorithms have been shown to detect both SRF and IRF more reliably than retinal specialists especially in less conspicuous cases [26]. DNNs have been shown to be able to accurately detect retinal fluids caused by various diseases with OCT scans acquired from different devices [47, 26]. Ideally, such automated tools serve to support retinal specialists in their decision making. To this end, computational tools need to explain their decisions and communicate their uncertainty to the treating ophthalmologist [20, 21]. In collaboration, a retina specialist assisted by an artificial intelligence (AI) tool can outperform the model alone, e.g. for the task of diabetic retinopathy grading [46].
Here, we develop a convolutional deep learning model based on the concept of multi-task learning [10, 60], that simultaneously detects IRF, SRF and disease activity in nAMD. The localization of the fluid plays a decisive role in the treatment outcome [48, 31, 45] with the simultaneous presence of IRF and SRF being associated with the worst prognosis [56]. To this end, we visualize the representation driving the DNN-based decisions using t-distributed stochastic neighbor embedding (t-SNE) [58, 28] and investigate the model’s decisions using clinically validated saliency mapping techniques [6]. Thus, our work provides an interpretable tool for the ophthalmologist to rapidly access the neural network’s decision process both on a population-based as well as an individual-patient level as a prerequisite for clinical application.
2 Methods
2.1 Data Collection
70 consecutive patients (46 females, 24 males) with nAMD at least in one eye, seen by GA in the Macula clinic at the University Eye Hospital Tübingen were included in this study. Exclusion criteria were any other cause of neovascularisation, any coexisting retinal pathology (e.g. epiretinal membrane, macular hole, diabetic retinopathy), glaucoma and media opacity that did not allow to take images of sufficient quality.
3762 B-scans (2011 right eye, 1751 left eye) of 440 × 512 pixels with Heidelberg Spectralis OCT (Heidelberg Engineering, Heidelberg,Germany) were included in the study. A retina specialist (WI) assessed the presence of IRF and SRF as well as disease activity on each individual image (Fig. 1). Disease activity was also graded by an ophthalmologist resident (GA). The degree of inter-annotator agreement according to Cohen’s kappa statistic was 0.86. B-scans were assigned to a training, validation or test set (Table 1), where care was taken to assign all images from one patient to one of the sets to avoid information leakage. The relationship between the nAMD activity and SRF or IRF were captured by Cohen’s kappa statistic (Table 2), which indicated the independence of the two retinal fluid types. Ethical approval was granted by the local institutional ethics committee of the University of Tübingen. Due to the retrospective character of the study, the requirement for patient consent was waived by the ethics committee. The study was conducted in accordance with the tenets of the Declaration of Helsinki.
OCT Data distribution of subretinal fluid (SRF), intraretinal fluid (IRF) and active nAMD in B-Scans in training, validation and test sets, respectively. Absolute and relative numbers are shown.
Agreement of task-specific labels across training, validation and test sets, measured via Cohen’s kappa statistic, which is essentially a number between -1 and 1. While 1 indicates a full agreement, lower scores mean less agreement. Negative scores indicate disagreement.
2.2 Diagnostic Tasks, Network Architecture and Model Development
We developed a multi-task DNN to detect the presence of SRF and IRF as well as the nAMD activity from OCT B-scans. While these tasks could have been performed by different networks trained for each particular task, we adopted a multi-task learning approach and trained a single network to perform these tasks simultaneously (Fig. 2). As backbone, we used the InceptionV3 architecture [54] via Keras [13]. The back-bone was pretrained on ImageNet [44] for 1000-way classification via a softmax function. We used the InceptionV3 DNN’s convolutional stack as is but adapted the deeper layers to our multi-task scenario as follows. First, we linked max pooling and average pooling to the end of convolutional stack. They were followed by a dense layer, which yielded a shared representation with 1024 features. Following the shared representation we added task-specific heads with 256 units. These specialized into their respective tasks and extracted their own 256-dimensional feature representations. Then, task-specific binary decisions were achieved by single units equipped with sigmoid functions.

A deep neural network for simultaneous detection of subretinal and intraretinal fluid as well as the nAMD activity from OCT B-scans. Given a B-scan, convolutional stack of the InceptionV3 architecture extracts 2048 feature maps. These are average and max pooled, and fed into a fully connected (dense) layer with 1024 units for shared representation. Then, task-specific heads specialize into individual tasks and single units with sigmoid function achieve binary classification based on 256 task-specific features.
We trained our networks with equally weighted cross-entropy losses for all tasks on the training images:  , where yn was a vector of binary labels indicating nAMD activity and the presence of IRF or SRF in an image xn. Parameterized by θ, a DNN fθ(·) was optimized with respect to the total cross-entropy on the training data:
, where yn was a vector of binary labels indicating nAMD activity and the presence of IRF or SRF in an image xn. Parameterized by θ, a DNN fθ(·) was optimized with respect to the total cross-entropy on the training data:  , where
, where  was a list of probabilities estimated via the sigmoid functions for different tasks and t was an index into T tasks. For T = 1, multi-task learning reduced to single-task learning. To address the class imbalance in data (Table 1), we used random oversampling (see Section 2.2.2 for details). We also used Stochastic Gradient Descent (SGD) with Nesterov’s Accelerated Gradients (NAG) [35, 53], minibatch size of eight, a momentum coefficient of 0.9, an initial learning rate of 5 · 10-4, a decay rate of 10-6 and a regularization constant of 10-5 for 120 or 150 epochs (see Section 2.2.1 for longer training). During the first five epochs, the convolutional stack was frozen and only dense layers were trained. Then, all layers were fine-tuned to all tasks. The best models were selected based on total validation loss after each epoch and used for inference on the test set.
was a list of probabilities estimated via the sigmoid functions for different tasks and t was an index into T tasks. For T = 1, multi-task learning reduced to single-task learning. To address the class imbalance in data (Table 1), we used random oversampling (see Section 2.2.2 for details). We also used Stochastic Gradient Descent (SGD) with Nesterov’s Accelerated Gradients (NAG) [35, 53], minibatch size of eight, a momentum coefficient of 0.9, an initial learning rate of 5 · 10-4, a decay rate of 10-6 and a regularization constant of 10-5 for 120 or 150 epochs (see Section 2.2.1 for longer training). During the first five epochs, the convolutional stack was frozen and only dense layers were trained. Then, all layers were fine-tuned to all tasks. The best models were selected based on total validation loss after each epoch and used for inference on the test set.
2.2.1 Data augmentation and preprocessing
First, we used mixup [66] for data augmentation during training. Mixup generates artificial examples through the convex combinations of randomly sampled data points. We adapted mixup to our multi-task learning scenario as follows:
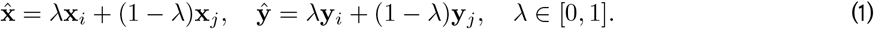 Mixing was controlled by λ ∼ Beta(α, α), where α ∈ (0, ∞). For α = 0, λ is either 0 or 1, and there is no mixing. Typical values to enable mixing are in [0.1, 0.4]. While large values may lead to underfitting, longer training aids in mixing for large α [66]. We used 0, 0.05 0.1, and 0.2 for α and trained networks for 120 epochs when not mixing and 150 epochs when mixing. Also, to allow for a warm-up period when mixing [66], we set α = 0 for the first five epochs.
Mixing was controlled by λ ∼ Beta(α, α), where α ∈ (0, ∞). For α = 0, λ is either 0 or 1, and there is no mixing. Typical values to enable mixing are in [0.1, 0.4]. While large values may lead to underfitting, longer training aids in mixing for large α [66]. We used 0, 0.05 0.1, and 0.2 for α and trained networks for 120 epochs when not mixing and 150 epochs when mixing. Also, to allow for a warm-up period when mixing [66], we set α = 0 for the first five epochs.
As a second step in data augmentation, we applied common data augmentation operations such as adjustment of brightness within ±10%, horizontal and vertical flipping, up and down scaling within ±10%, translation of pixels horizontally and vertically within ±30 positions and random rotation within ±45 degrees. After all data augmentation operations, we used an appropriate preprocessing function1 from the Keras API [13].
2.2.2 Quantification of uncertainty via mixup and Deep Ensembles
Quantification of diagnostic uncertainty is crucial for treatment decisions. With a proper management of uncertainty, diagnostic errors, delays or excess healthcare utilization can be minimized [8]. However, DNNs are typically overconfident about their predictions and they do not generate well-calibrated and reliable uncertainty estimates for their decisions [22, 27, 29, 32, 16]. mixup [66] improves the calibration of DNN outputs by smoothing labels through their convex combinations (Eq. 1) [55]. On top of mixup, we used Deep Ensembles [29] consisting of multiple DNNs. These DNNs are randomly initialized and then allowed to follow different optimization trajectories to explore different modes in function space [29, 18]. The ensemble, then, exploits the diversity of multiple predictors in decision-making and improves upon the single network performance both in accuracy and calibration, even with small numbers of DNNs trained on standard datasets [29, 18, 39]. Also in a DR detection scenario [5], an ensemble of three DNNs already performed well in both aspects.
Using the network architecture, hyperparameters and training procedures described above, we constructed our ensembles with three DNNs. During their training, we also used oversampling with a twist. For each DNN, we oversampled training images with respect to a particular task’s labels. This enabled DNNs to train on a balanced dataset for their respective tasks while also learning about other tasks, even though the data was not balanced for the other tasks. Overall, this contributed to the diversity of DNNs, which is essential for ensemble models. DNNs were further diversified by the randomness in the initialization of dense layers, shuffling of training examples as well as mixing and data augmentation. In the end, we used the ensemble’s mean output for predictions and quantified uncertainty in terms of entropy, given the average predictive probabilities.
2.3 Low-dimensional embedding of images
We used t-SNE [58] to obtain further insights into the decision-making process of our ensemble model. t-SNE is a non-linear dimensionality reduction method, that embeds high-dimensional data points into a low-dimensional space. To evaluate ensemble-based representations, we concatenated features from ensemble members’ predetermined read-out layers and performed t-SNE based on them, embedding each B-scan into the two-dimensional plane. We used openTSNE [40] with PCA initialization to better preserve the global structure of the data and improve the reproducibility [28]. We used a perplexity of 200 for 1500 iterations with an early exaggeration coefficient of 12 for the first 500 iterations, according to best-practice strategies [28]. Similarities between data points were measured by Euclidean distance in the feature space.
2.4 Saliency Maps
We used Layer-wise Relevance Propagation (LRP) [7] to compute saliency maps, to highlight the regions in the OCT images which contributed to the DNN decisions. We have recently shown that a propagation rule known as LRP-PresetBFlat performs best in obtaining clinically relevant saliency maps from InceptionV3 networks trained to detect active nAMD from OCT B-scans [6]. Using this rule, we created three saliency maps for each OCT slice, namely, one for each task: subretinal (cyan), intraretinal (magenta) and diesease activity in nAMD (yellow) (Fig. 6). To improve the visualization of the salient regions, saliency maps were postprocessed and the maps of each task were combined into one [6]. Saliency maps were only shown for predictions with an estimated probability greater than 0.5 since previous work has shown, that especially in absence of disease, saliency maps can lead physicans to overdiagnosis [46].
3 Results
We developed an ensemble of three multi-task DNNs to simultaneously detect SRF, IRF and activity of nAMD on OCT B-scans (Fig. 1). Each DNN consisted of a shared convolutional core combined with pooling operations which yielded a shared representation (Fig. 2). This representation served as the basis for the decision of the three task heads. The idea behind this approach is that the DNN can benefit from the shared general purpose representation induced by combining information from different tasks. We first investigated the performance of the multi-task model in the three tasks. To this end, we compared the multi-task model with more specialized single task models, where we constructed three DNNs, one for each task, which did not share any representation but were trained independently. All DNNs were trained on a training set acquired during clinical routine at the University Eye Hospital in Tübingen (see Table 1 and Methods). We selected the multi-task model with the best accuracy for the activity detection task on the validation set and report accuracy values computed on an independent test set (Table 3). Overall, we found the multi-task model to be well calibrated on the test set (Adaptive expected calibration error [16] of 0.0147 for SRF, 0.0104 for IRF and 0.0263 for active nAMD), suggesting that uncertainty reported for the decisions of the DNN-based ensemble reflect the true model uncertainty.
Accuracy of ensembles for various degrees of mixing (indicated by α). Gray row indicates the ensemble of choice for further analysis based on the validation performance for the activity detection task.
We found that the performance of the multi-task model surpassed the single-task model performance in disease activity detection, reaching an accuracy of 94.2 % for the multi-task model vs. 91.4% for the single task model (Table 3, Fig. 3). Interestingly, this multi-task model optimized for AMD activity detection performed slightly worse than the single-task models for the two tasks of detecting SRF and IRF (SRF: accuracy of 0.917 vs. 0.924 for multi-task vs. single-task; IRF: 0.937 vs. 0.950). This suggests that the representations learned by the multi-task DNNs are indeed a trade-off between achieving high performance on all three tasks, and as a result on activity detection, but somewhat sacrifice single-task detection performance.

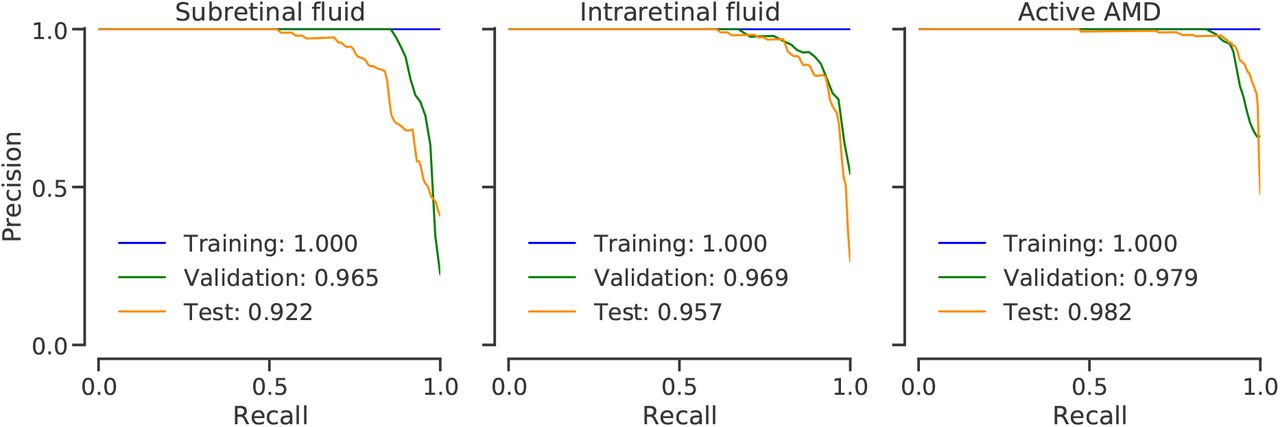
Precision-recall curves for the selected ensemble model. Area under the curve (AUC) values given for partitions also summarize the overall performance into one number (higher is better).
We thus further studied the representations learned by the multi-task model to gain insight into its decision making-process. To this end, we extracted the representation of individual OCT scans at various levels of processing throughout DNNs (Fig. 7) and created two-dimensional embeddings of these via t-SNE (Fig. 4 and 5). In these visualizations, each point in two-dimensions corresponds to an individual OCT scan. OCT scans, which are similar to each other according to the learned representation, are mapped to nearby points. While t-SNE representations are generally useful for exploratory analysis if some guidelines are followed, one should be careful interpreting distances in the embedded space — e.g. the size of the white space between clusters is rather an effect of the algorithm not the data [28, 9].

Visualization of data via t-SNE of ensemble-based representations. (a) Low dimensional embedding of images based on the penultimate layer features from single-task networks. Training, validation and test data aligned together and colored with respect to the task-specific labels. (b) Same as in (a) but w.r.t. features from the shared representation layer of multi-task networks. (c) Same map as in (b) but colored w.r.t. correct and wrong predictions. (d) Same map as (b) but colored w.r.t. uncertainty min-max normalized to [0, 1].

Layer-wise visualization of data via t-SNE. Starting just before the first Inception module (a) and reading out feature representations yielded by every other module (b-f) along with the last Inception module (g), the shared representation layer (h) and the nAMD activity detection head’s penultimate layer (i), we performed t-SNE with the aforementioned settings. Useful representations emerged towards the end of convolutional stack and the task-specific representation allowed the best separation of nAMD active cases from those inactive. Exact read-out locations can be found in Appendix (Fig. 7).
We first investigated the final representation based on which the single task DNNs and the individual task heads of the multi-task DNNs make their decision (Fig. 4). We colored the individual points according to whether the OCT scan was labeled as containing evidence for SRF or IRF, as well as overall AMD activity. Reflecting the high task accuracy, most inconspicuous OCT scans were placed in a clearly separated island, clearly distinct from the OCT scans with any of the disease labels (Fig. 4a, b). For the single-task DNNs, additional well-separated clusters were found, indicating the learned task-label (Fig. 4a). For example, OCT scans with SRF present formed a single cluster, clearly distinct from the OCT scans without this label. Interestingly, this was also the case for the active AMD task, for which no clearly distinct subclusters could be seen.
In contrast, for the embedding extracted from the shared representation of the multi-task model, OCT scans labeled with SRF formed a well-separated cluster at the bottom right, as did scans with IRF labels at the top right (Fig. 4b). Interestingly, there was a small cluster in between these two which contained scans labeled with both. Consequently, OCT scans labeled with active AMD encompassed all three of these major disease related clusters, suggesting the multi-task DNNs indeed learned separate representations of the two fluid types which were then used by the individual task heads. The few incorrectly classified OCT scans could be found within their clusters to be placed close towards other clusters (Fig. 4c) in areas where we also found examples with high classifier uncertainty. Thus, decisions were more uncertain e.g. for inactive OCT scans that were more similar to OCT scans with signs of sub- or intraretinal fluid, sometimes leading the DNN to incorrect decisions (Fig. 4d). In clinical application of such an algorithm, high uncertainty could thus be used to select individual B-scans warranting further scrutiny through experienced clinicians.
We next studied how the multi-task representation emerged through processing in the network (Fig. 5). While in the initial layers data points representing active nAMD were still uniformly distributed (Fig. 5, a-c), a clear separation of active nAMD cases developed gradually in later layers of the DNN (Fig. 5, d-g), leading to best separation in the shared representation (Fig. 5, h). The decision head for active AMD refined this representation only very little (Fig. 5, i). This analysis is in agreement with previous work showing that lower layers in DNNs typically extract very general task-independent image features that are gradually refined to disentangle the representation of the task-relevant image classes [65, 19].
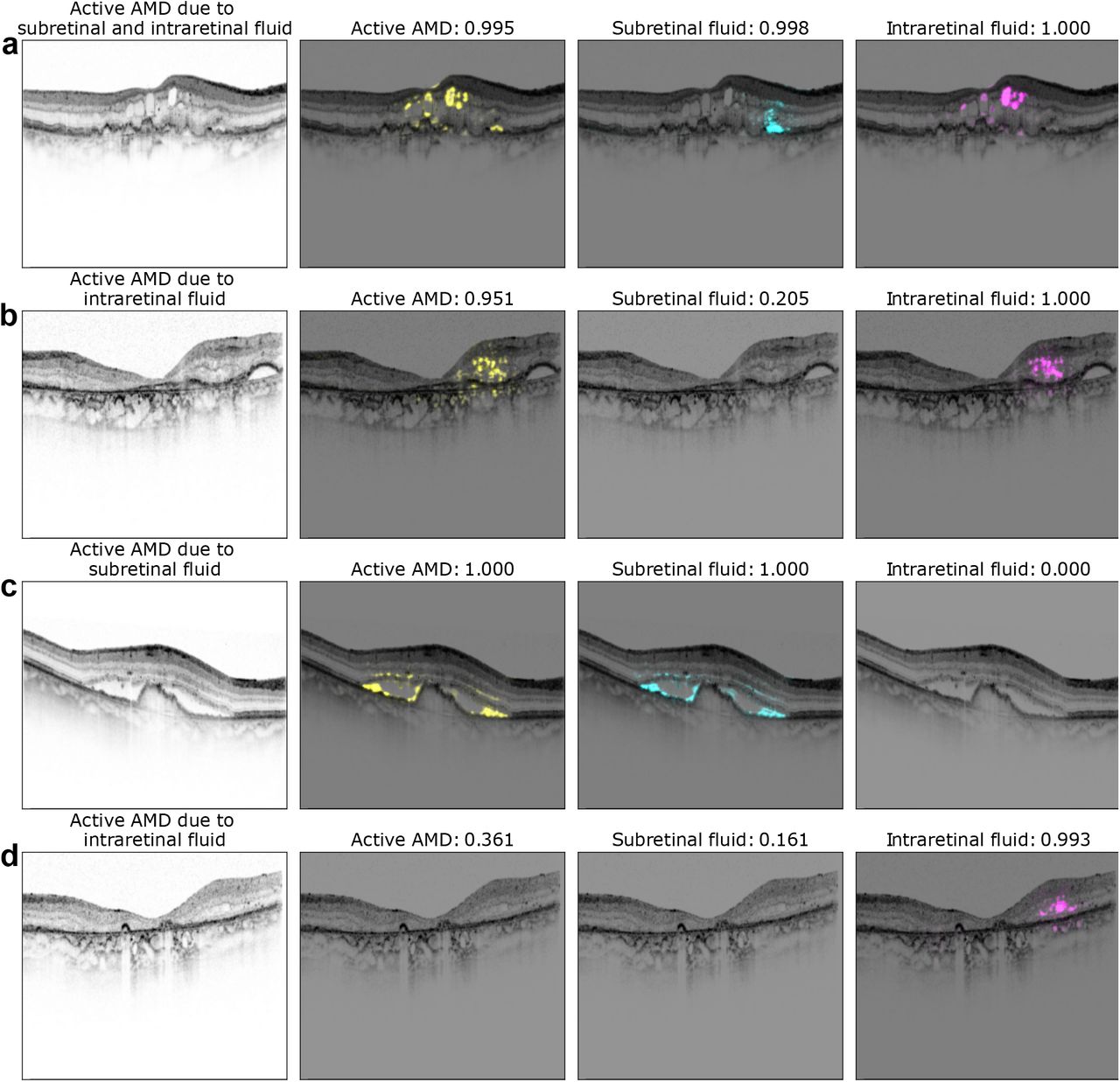
We next analyzed if well-known saliency maps can also be used in case of the multi-task DNNs to identify which image regions in individual OCT scans were relevant for the decision. Specifically, we were interested in whether the saliency maps for the subtasks of SRF and IRF detection obtained from the multi-task model allowed reasoning about evidence specific to these tasks. To this end, we generated saliency maps on four exemplary OCT scans using LRP [7] (Figure 6). For each OCT scan, we generated three maps, one for each of the three tasks, propagating the task-information back from the task head.

Exemplary saliency maps for four optical coherence tomography (OCT) images. The first column displays the OCT B-scan with the corresponding labeling of a retinal specialist. Second to fourth column show saliency maps and the network’s confidence for active nAMD (yellow), subretinal fluid (SRF) (cyan) and intraretinal fluid (IRF) (magenta). Note, that saliency maps are only shown in case of confidence > 0.5. Supplementary saliency maps obtained from single-task models can also be found in Fig.8.
We first analyzed an OCT scan with clearly active AMD and both SRF and IRF present (Figure 6a). The active AMD saliency map focused on intraretinal fluids, which were also clearly visible in the task-specific saliency map, and faintly highlighted regions with SRF. The SRF saliency map, however, clearly highlighted SRF. In two further example scans with either IRF or SRF, respectively, active AMD saliency maps clearly corresponded to the individual task maps (Figure 6b,c), indicating that the saliency maps obtained from the multi-task DNN can support clinical decision making about active AMD, but also allow clinicians to identify evidence in the relevant sub-tasks of finding SRF and IRF. We also identified rare failure cases of the obtained saliency maps (Fig. 6d): In one example, an OCT scan was falsely classified positive for SRF with a confidence of 0.614, because IRF was falsely classified as SRF. We hypothesize that the DNN misclassified the superior border of the intraretinal fluid as photoreceptor layer detached from the retinal pigment epithelium. The assumption, that the DNN primarily recognizes contrast-rich interfaces such as SRF and IRF is further supported by the false labeling of cystoid spaces within choroid in Fig. 6b and d, while in a smoother, lower-contrast choroid saliency maps do not highlight any structures (Fig. 6. This suggests that beyond such proof of principle studies, larger and more variable datasets will be needed to train multi-task DNNs to more completely rule out such artefacts.
We additionally generated saliency maps from the single task DNNs (Fig.8). Compared to the saliency maps generated from the multi-task models, those saliency maps appear slightly more defined, but high-lighted similar regions, indicating that single task relevant information could be extracted from the multi-task DNN. Interestingly, Fig.8)d provides additional support for the multi-task DNNs, showing that independently trained single task DNNs can make serious mistakes in the lack of information shared between diagnostic tasks. Multi-task networks are more informed about their tasks (Fig. 6d).
4 Discussion
In this study, we developed a machine learning model based on the concept of multi-task learning to simultaneously detect SRF, IRF as well as disease activity in OCT B-scans of nAMD patients. We showed that a multi-task model, which takes the presence of IRF and SRF into account to detect disease activity in nAMD, surpassed a single task model regarding accuracy in this task. Furthermore, our visualization of the multi-task model’s decision-making process via t-SNE demonstrated that in later layers of the multi-task model, inactive and active nAMD B-scans increasingly formed different clusters. Additionally, within the active AMD B-scans, we observed a growing separation in three distinct clusters, each containing OCT B-scans with either subretinal, intraretinal or both fluid types. In contrast, this separation could not be seen in the single task models of the respective tasks. Saliency maps of exemplary individual B-scans of the three tasks further corroborate that task-relevant information can be extracted from the multi-task networks, suggesting that a multi-task DNN can serve as a basis for an explainable clinical decision support system for nAMD activity.
Overall treatment burden of nAMD measured in disability-adjusted life years as well as the economic burden have decreased since the approval of anti-VEGF [63, 33]. However, there is still a high number of patients who discontinue treatment [61]. Patients named the need for assistance, either in the form of a travel companion or a family member, as the main reason for dropping out of therapy [51], and quoted traveling illness as a major reason for therapy discontinuation [24]. Additionally, recurrence of quiescent disease requiring prompt treatment is common, making life-long monitoring necessary [4]. For these reasons, automated solutions allowing monitoring close home or even at home are promising technologies to increase treatment rates, even more in a patient population, that has difficulties seeing an ophthalmologist [50, 12]: They provide easier access and reduce the disease burden on the individual [34]. Automated solutions for fluid detection have further gained popularity during the Covid-19 pandemic, which showed the devastating effects of delay or interruption in VEGF treatment of nAMD on visual function [4, 56]. However, despite promising results in laboratory settings, real-world data revealed significantly lower performance rates of home-based OCT with in particular SRF being overlooked by the system [30]. This shows the necessity of further developments on the machine learning side to guarantee reliable use, with multi-task learning as suggested in this study being a viable option.
Beyond that, a recent meta-analysis provided evidence of varying influences of SRF and IRF on the visual outcome in nAMD patients [11]. Stable SRF might not affect visual outcome, while fluctuations in IRF during treatment seem to negatively influence visual acuity [11]. For this reason, treatment decisions in nAMD solely on a yes/no basis may not meet future treatment guidelines, which might rather require a sophisticated decision depending on the present fluid type for or against an anti-VEGF injection. Our analysis shows that this insight is not provided by single task DNNs for nAMD activity detection and thus argues for multi-task DNNs as backbone in clinician support system.
Ophthalmology has recently seen a development of various artificial intelligence systems, yet their use in clinical routine remains rare, despite a few systems now being available on the market [1, 37]. One big barrier is the concern of potential harm of the patient-physician relationship going hand in hand with the lack of trust in those systems [23]. Here, we combined multi-task DNNs with different visualization methods to give an insight into the DNNs’ reasoning and increase transparency. First, we used t-SNE as visualization method for high-dimensional data [58, 28] (Fig. 4) to present the decision-making process of the model. We showed that the two-dimensional embedding of the shared representation of the multi-task model nicely separated OCT B-scans in distinct clusters according to the presence of SRF or IRF or both fluid types (Fig. 5). In comparison, single task DNNs for active nAMD detection only separated two clusters of OCT-scans, indicating absence or presence of disease (Fig. 4). The visualization of the multi-task learning via t-SNE provides thus a rationale for why certain OCT B-scans were graded as active for nAMD, which cannot be seen in a visualization of the single task algorithm (Fig. 4). It suggests that in concurrently learning basic features of nAMD activity, namely IRF and SRF [52], multi-task learning increases prediction accuracy for the main task of active AMD. Multi-task learning therefore potentially increases ophthalmologist’s confidence in an algorithm since visualization via t-SNE shows, that reasoning resembles their own (Fig. 5). In the future, the multi-task system could also be extended for other signs indicative of active nAMD such as hard exsudates, pigment epithelial detachment or hyperreflective foci, which we did not study here due their comparably rare occurrence [52].
Overall high accuracy and reliability of a DNN might not be sufficient for trust and use in clinical routine, since best medical advice has to be given to an individual patient. In a second step, we therefore analyzed the multi-task model’s decision on saliency maps of individual OCT-scans. Saliency maps highlight critical regions for the model’s decision and thus allow a quick visual control of its reasoning. However, it needs to be kept in mind, that first various methods of saliency map generation exist with different degrees of agreement with clinical validation [6, 49, 57] and secondly, saliency maps can lead to overdiagnosis [46], while some methods have also been shown to generate maps independent of the final decision of the algorithm [36]. Therefore we only displayed saliency maps in case of a confidence of the algorithm > 0,5. Compared to saliency maps of single task DNNs, multi-task saliency maps seem to draw slightly less sharp contours, however, there is good overlap between regions used for active AMD detection and those for SRF and IRF.
Future studies will need to assess how well these multi-task learning results transfer from the data sample acquired at a tertiary center in Germany. The generalization to other populations, different recording qualities as well as OCT devices from other devices and in particular recently developed mobile devices, needs to be assessed. However, we show as a proof-of-principle study that multi-task learning enhances performance in a complex main task, namely activity recognition in nAMD, while increasing the overall explainability of neural network decision-making and the interpretability of the DNN decision for individual patient outcomes. It thus helps overcome the barriers to clinical application by mimicking the human process of diagnosis considering multiple disease features.
Data Availability
The optical coherence tomography scans were obtained from the University Eye Clinic and their use was permitted by the Institutional Ethics Committee of the University of Tuebingen.
Author contribution statement
MSA, HF and PB designed the research. MSA performed the experiments. GA, WI, FZ, LK were involved in data acuqisition. FZ, HF, GA, LK and WI provided medical advice. MSA, HF and PB wrote the manuscript with input from all authors. All authors approved the final version of the manuscript and agreed on being accountable for the work.
5 Acknowledgments
We thank the German Ministry of Science and Education (BMBF) for funding through the Tübingen AI Center (FKZ 01IS18039A) and the German Science Foundation for funding through a Heisenberg Professorship (BE5601/4-2) and the Excellence Cluster “Machine Learning — New Perspectives for Science” (EXC 2064, project number 390727645). H. Faber thanks the Faculty of Medicine, Eberhard Karls University of Tuebingen, Germany (application number 463–0–0) for additionally funding her research through the Junior Clinician Scientist Program (application number 463–0–0). We further thank Novartis AG for funding part of the research. The funding bodies did not have any influence in the study planning and design.
Appendix

Read-out locations within the convolutional stack of the InceptionV3 architecture (indicated by big black arrows). In addition to these, we used the shared representation layer and task-specific layers of our multi-task networks (see Fig. 2). Base figure was obtained from https://cloud.google.com/tpu/docs/inception-v3-advanced.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Supplementary saliency maps for the OCT images shown in Fig.6. These were obtained from single-task models.
Footnotes
Meeting Presentation: The manuscript is accepted for presentation (ID PDo04-01) at the 120. Congress of the DOG (Deutsche Ophthalmologische Gesellschaft), 29.09.–02.10.2022, Berlin, Germany
Financial support: Financial support was provided by German Ministry of Science and Education (BMBF) through the Tübingen AI Center (FKZ 01IS18039A) and the German Science Foundation for funding through a Heisenberg Professorship (BE5601/4-2) and the Excellence Cluster “Machine Learning — New Perspectives for Science” (EXC 2064, project number 390727645), Junior Clinician Scientist Program of the Faculty of Medicine, Eberhard Karls University of Tübingen, Germany (application number 463–0–0) (HF) and the Novartis AG. The sponsor or funding organization had no role in the design or conduct of this research.
Conflict of Interest: PB holds shares of eye2you GmbH. FZ has received consulting fees from Allergan, Bayer HealthCare, Boehringer-Ingelheim, Novo Nordisk, MSD and Novartis and speaker fees from Alimera, Allergan, Bayer HealthCare and Novartis. FZ was involved in research funded by grants from Bayer Healthcare, Biogen, Clearside, Ionis, Kodiak, Novartis, Ophtea, Regeneron and Roche/Genentech. LK receives, via third-party accounts of the University Eye Hospital, research funding and honoraria from Novartis and research funding from the Tistou and Charlotte Kerstan Foundation. HF received medical training event costs from Novartis. MSA, WI and GA declare no competing interest.
Address for preprints: Prof. Dr. rer. nat. P. Berens, Werner Reichardt Centre for Integrative Neuroscience (CIN) Institute for Ophthalmic Research, University of Tübingen, Otfried-Müller-Str. 25, D-72076 Tübingen, Germany. Phone: +49 (0)7071 29-88833, philipp.berens{at}uni-tuebingen.de
Revised for a new submission. Minor changes in abstract and the title page.
↵1 keras.applications.inception_v3.preprocess_input
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵



