
Abstract
Background Predicting lung adenocarcinoma (LUAD) and Lung Squamous Cell Carcinoma (LUSC) risk cohorts is a crucial step in precision oncology. Currently, clinicians and patients are informed about the patient’s risk group via staging. Recently, several machine learning approaches are reported for the stratification of LUAD and LUSC patients, but there is no study comparatively assessing the integrated modeling of the clinicopathological and genetic data of these two lung cancer types so far.
Methods In our study based on 1026 patients’ clinicopathological and somatically mutated gene features, a prognostic prediction model is implemented to rank the importance of features according to their impact on risk classification.
Findings By integrating the clinicopathological features and somatically mutated genes of patients, we achieved the highest accuracy; %93 for LUAD and %89 for LUSC, respectively. Our second finding is that new prognostic genes such as KEAP1 for LUAD and CSMD3 for LUSC and new clinicopathological factors such as site of resection are significantly associated with the risk stratification and can be integrated into clinical decision making.
Conclusions In current clinical practice, clinicians, and patients are informed about the patient’s risk group only with cancer staging. With the feature set we propose, clinicians and patients can assess the risk group of their patients according to the patient-specific clinical and molecular parameters. Using this machine learning model we are implementing a user-friendly web interface for clinicians and lung cancer patients to predict the risk stratification of individuals and to understand the underlying clinical and molecular mechanisms.
1 INTRODUCTION
Lung cancer is the most common type of cancer and the leading cause of death worldwide. The World Health Organization (WHO) reported that lung cancer is the second most frequently diagnosed cancer type, constituted 11.4% of all cancers, and the leading cause of cancer-related deaths (18%) in 2020[1]. In the United States, only 14% of patients who develop lung cancer survive for five years. These mortality rates (>150,000/year) far exceed those of the acquired immunodeficiency syndrome epidemic. However, this survival rate has only slightly increased in the last two decades, and it appears unlikely that marked improvements will occur in the near future[2].
Lung cancer can be divided into two classes: Small Cell Lung Cancer (SCLC) and Non-Small Cell Lung Cancer (NSCLC). Lung Adenocarcinoma (LUAD) and Lung Squamous Cell Carcinoma (LUSC) are two of the three subtypes of Non-Small Cell Lung Cancer (NSCLC) occurring in 85% of lung cancer patients. When the health conditions of LUAD and LUSC cancer patients, which make up most of the lung cancer cases, are detected at an earlier stage, patient risk group based treatment can be applied according to the course of cancer.
Presently, Machine Learning methods are getting integrated into decision making processes at the clinic due to their success in classification and prediction helping medical practitioners[3]. Machine learning provides the solution for decreasing the increasing price of health care and creating improved patient-clinician communication.
In this study, we comparatively evaluated the prediction power of five different machine learning algorithms to identify the risk groups of NSCLC : Support Vector Machine, Logistic Regression, Naive Bayes, Random Forest, and K Neighbors Classifiers using Python sci-kit-learn library.
2 BACKGROUND
Among the recent studies in the field of machine learning based lung cancer prediction, several of them used Computed Tomography (CT)[4] whereas other techniques are more specific, and used genomic or phenotypic information for building classification models[5].
In [4] authors used Support Vector Machine on Computed Tomography Images to detect lung malignant tumor cells. Sherafatian and Arjmand instead proposed a Decision Tree-based classifier for lung cancer diagnosis[5]. The proposed learning algorithm applied to miRNA sequencing data and clinical data on 1,068 samples from two lung cancer projects (LUAD and LUSC) in TCGA. The class imbalance issue in training and testing datasets was addressed separately using the Synthetic Minority Oversampling Technique (SMOTE) and the Decision Trees algorithms were performed using the RPART package. In our study we analyzed the prediction power of several machine learning algorithms using the previously unexplored combined features of the clinicopathological properties and somatically mutated driver genes.
3 MATERIALS AND METHODS
3.1 Data Collection
The genetic data and the corresponding clinical information for LUAD and LUSC were downloaded from the publicly available The Cancer Genome Atlas (TCGA) database. TCGA contains the largest known publicly available cancer patient data, including data from 11,000 patients from 33 different cancer types (https://www.cancer.gov/tcga). In our project, we downloaded the 522 LUAD cancer patients and 504 LUSC cancer patients with corresponding clinical and genetic information. After filtering out the missing values a total of 504 LUAD cancer patients with 51 of them live more than five years and 494 LUSC cancer patients with 83 of them live more than five years.
3.2 Preprocessing
A common problem encountered while training machine learning with biological data is its imbalanced and complicated nature due to missing values among data quality limitations. Most of the data in the biomedical domain is not smooth. Therefore, to recoup and preserve valuable biomedical data we applied several pre-processing strategies.
To deal with the high ratio of the missing values, features with less than %80 data content are removed from the training and test datasets. Submitter_id, diagnosis_id, exposure_id, demographic_id, treatment_id, and bcr_patient_barcode columns are random numbers thus do not contain information and are removed from the dataset. Columns that contain duplicate columns such as year_of_birth, state, up_dated_datetime, tissue_or_organ_of_origin are also removed. We also discarded the year_of_birth column as we can find the patient’s age from the days_to_birth(in days) column. In the state feature, all the values are the same as ’released’; therefore, we dropped it. For the columns that contain duplicate value such as (tissue_or_organ_of_origin / site_of_resection_or_biopsy) we dropped one of them.
Data were partitioned into training (80%) and testing (20%) datasets using the sci-kit-learn’s model_selection package and all subsequent exploratory data analysis and model training was performed only on the training dataset.
3.3 Missing Value Imputation
The most common two strategies to cope with the missing value problem are dropping the null values and filling out the missing values with the mean of the feature. Although the effectiveness of these approaches is questionable, we experimented with filling out the missing values in train and test data with the mean of the training data.
However, there is an exceptional condition in our dataset that should not be filled with imputation methods. Days to death can exceed the days to the last follow-up, and days to death is not available for patients still living. Therefore, we have experimented with three different methods to deal with that problem:
Drop the days_to_last_follow_up and assign 0 for all alive patients in days_to_death, then drop if there is a dead patient with a days_to_death value is 0. As we can see, we have found a 0.63 correlation with vital status, but we could not find any correlation with the patient’s risk.
Assume that all the patients will live until 90 years old and fill the NaN values for alive patients assuming that they will live until their 90s. As we can see, we have found a 0.83 correlation with vital status, but we could not find any correlation with the patient’s risk.
We transferred the alive patient information into the days_to_death column and dropped the days_to_last_follow_up column. As we can see, we could not find any correlation for days to death neither between vital status nor risk of the patient.
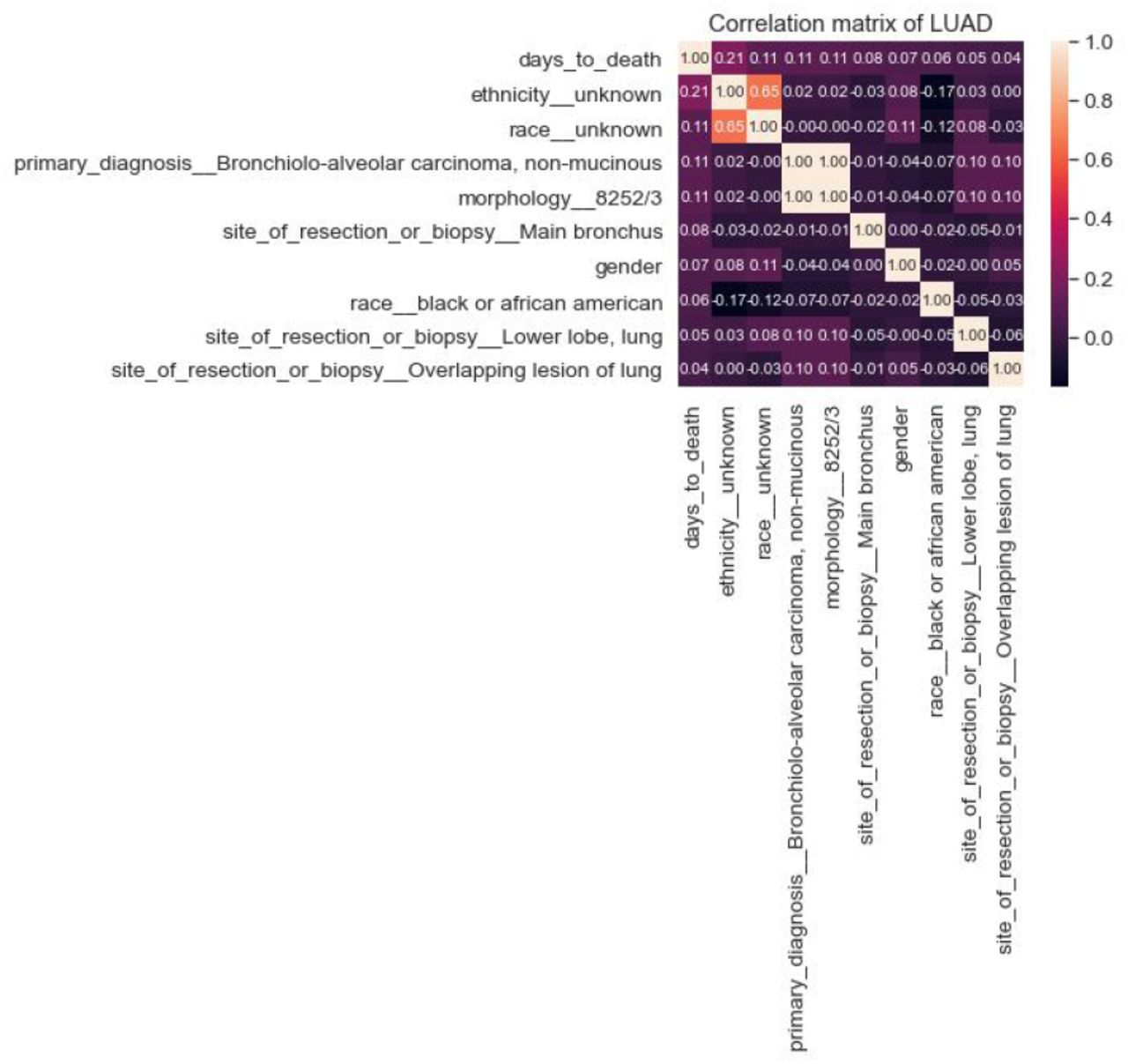
After computing the correlation coefficients of the features for these three strategies (Figure 1), alive patients’ days_to_death values are filled with the days_to_last_follow_up feature.

Correlation coefficients of three strategies for assigning missing values of days_to_death column
3.4 Numeric Columns Imputation
The missing values in the columns (age_at_diagnosis, days_to_birth, years_smoked, cigarattes_per_day) of both LUAD and LUSC training and test datasets are filled with the mean values of the training data using the SimpleImputer library in scikit-learn. The column with the most missing value was the years_smoked for both LUAD and LUSC. The ratio of missing values in the years_smoked feature is 62.83% in LUAD and 55.55% in LUSC.
3.5 Categorical Columns Imputation
There are two critical categorical columns in the dataset; race and ethnicity. Nevertheless, 12.8% race and 24.1% ethnicity values are missing for LUAD, and on the other hand, 22.4% race and 35.1% ethnicity values are missing for the LUSC dataset. These two features may directly affect the remaining lifetime, and the authors did not want to impute these missing values. Therefore, missing values for both race and ethnicity are kept as unknown values.
Categorical variables contain label values rather than numeric values such as the “color” variable with the values: “red”, “green”, and “blue”. Each value represents a different category. The main problem with categorical data is that many machine learning algorithms cannot operate on label data directly. Most machine learning algorithms require all input variables and output variables to be numeric. Therefore, we should encode our categorical data into numeric data. To achieve that, we utilized the scikit-learn library’s preprocessing. For the first step, we applied LabelEncoder to categorize each unique value into an integer value. After that, OneHotEncoding is applied to the integer representation. The integer encoded variable is removed, and a new binary variable is added for each unique integer value. This strategy is applied to all our categorical values as depicted in Figure 2.

OneHotEncoding of categorical values
3.6 Balancing the Imbalanced Classes
For the LUAD and LUSC datasets, the number of patients surviving more than 5 years is approximately 9 times smaller than the opposite. Oversampling and Undersampling lead to similar performances provided that the sampling is correctly implemented on the training and testing folds separately [6]. For the TCGA dataset specifically, several previous studies applied. SMOTE for the TCGA training set [5,8]. Therefore, to cope with the class imbalance problem between the number of positives (i.e. patient survives longer than 5 years) and negatives we over-sampled both of the TCGA LUAD and TCGA LUSC training and testing patient set via Synthetic Minority Oversampling Technique (SMOTE). The class distributions before and after applying the SMOTE algorithm are presented in Figure 3.


The Class distribution before and after applying the SMOTE algorithm
3.7 Creation of the Machine Learning Models
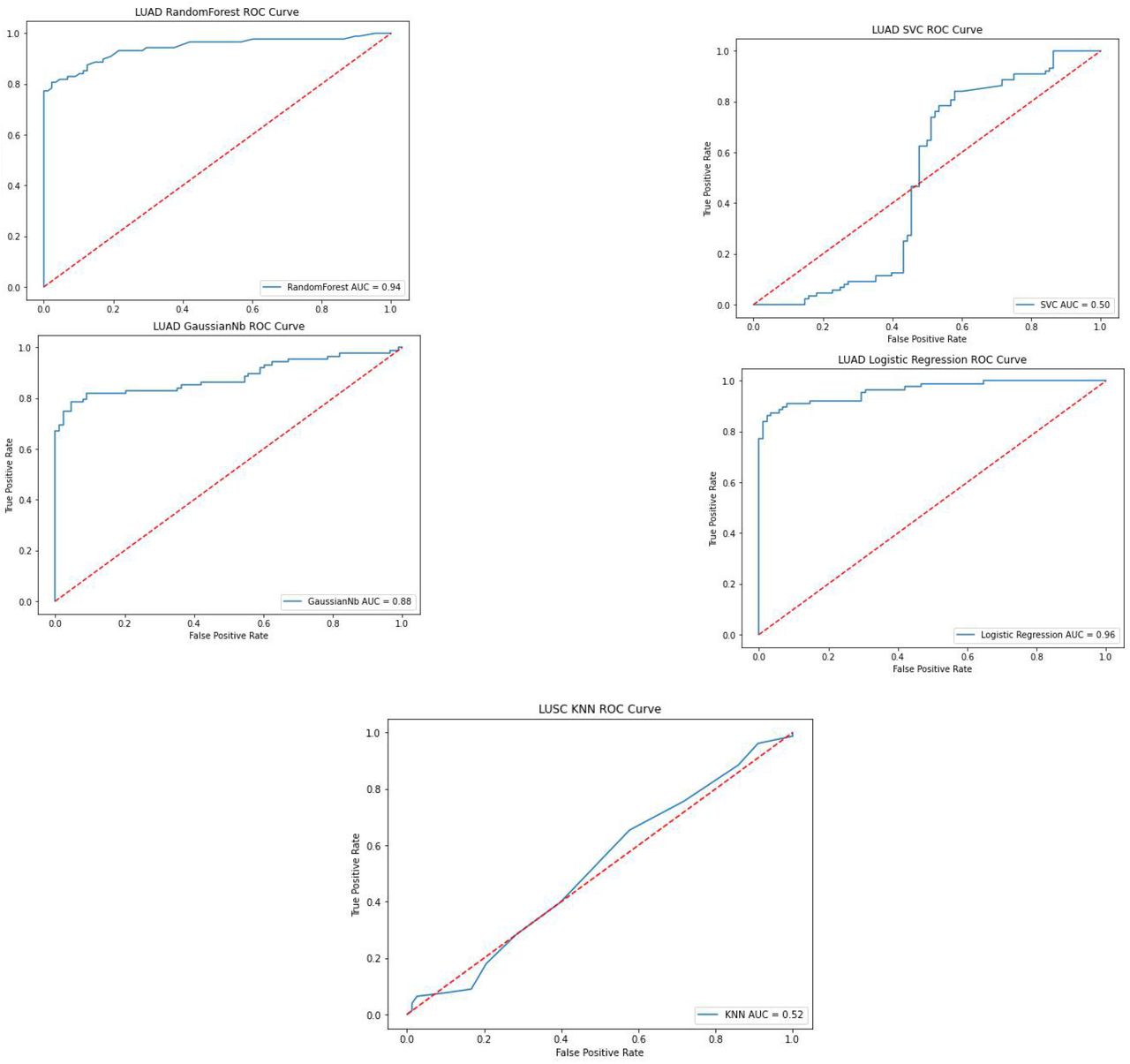
After the data preparation, five different classification algorithms (Logistic Regression, Random Forest Classifier, Naïve Bayes, SVC, and K-Neighbors Classifier) were applied to the LUAD and LUSC datasets. Subsequently, to evaluate the performance of the learning algorithms, the area under the receiver operating characteristics (ROC) curves (AUC) were plotted and calculated (Figure 4,5).

AUC of 5 Algorithms for LUAD

AUC of 5 Algorithms for LUSC
The AUC has been used for decades in the medical area for model selection. It is also commonly used in machine learning algorithms to evaluate the performance of the algorithms [11,12]. It is defined as a plot of a model’s true positive rate as the y-coordinate versus its false-positive rate as the x coordinate, under all possible score thresholds. In order to support the AUC metrics, the F1-score, precision, and recall are calculated and shown in Table 1 and Table 2.
Comparison of the Precision, Recall, F1-score of 5 algorithms for LUAD
Comparison of the Precision, Recall, F1-score of 5 algorithms for LUSC
3.8 Hyperparameter Tuning
Among the five different classification algorithms, the top two best scoring algorithms were found as Random Forest and Logistic Regression, thus hyperparameter tuning is applied to Random Forest and Logistic Regression based models. For hyperparameter tuning of these two algorithms, we implemented a 5-fold cross-validation where we first split the training set into 5 folds and then applied random oversampling on 4 folds which were used for training the classification model and then documented the model performance metrics on the remaining 1-fold using the GridSearchCV in scikit-learn.
4 RESULTS
The overall statistics of LUAD and LUSC datasets were summarized separately in Table 4. There are 522 (242 male, 280 female) patients for LUAD, 504 (373 male, 131 female) patients for LUSC. In LUAD, 188 patients and in LUSC 220 patients died during the TCGA project. These patients are divided into four different tumor stages, and they have different smoking habits for different ages. We applied GridSearchCV in scikit-learn to find the best parameters for the models. GridSearchCV is preferably used to tune hyperparameters compared to other tuning algorithms [13].
After applying the scikit-learn’s GridSearchCV (scoring=’f1’, cv=5) algorithm to Random Forest the best parameters found as max_depth=8, max_features=log2, min_samples_leaf=3, n_estimators=50 in LUAD with 0.93 f1-score, and max_depth=8, max_features=’auto’, min_samples_leaf=3, n_estimators=200 in LUSC with 0.87 f1-score. On the other hand, for the Logistic Regression; GridSearchCV tuned the parameters such as C=16.77, penalty=l2, solver=newton-cg in LUAD with 0.92 f1-score and C=109.85, penalty=l1, solver=liblinear with 0.85 f1-score in LUSC (Table 3).
Comparison of performance metrics for Random Forest and Logistic Regression with and without hyperparameter tuning
4.1 K-Fold Cross Validation
K-fold cross-validation is an approach that splits the dataset into k-fold and shuffles the training and test sets k times to assess how the results of the analysis will generalize to an independent data set[14,15]. We applied 5-fold cross-validation with Logistic Regression and Random Forest models to improve the reliability of these algorithms. During this process, we constructed the Logistic Regression and Random Forest models with hyperparameters obtained from GridSearchCV. Random Forest and Logistic Regression models’ results for each five-folds can be observed in Table 5 and Table 6 with a mean and standard deviation of folds.
Clinical properties of the LUAD and LUSC patients
Accuracies of each fold for LUSC
Accuracies of each fold for LUAD
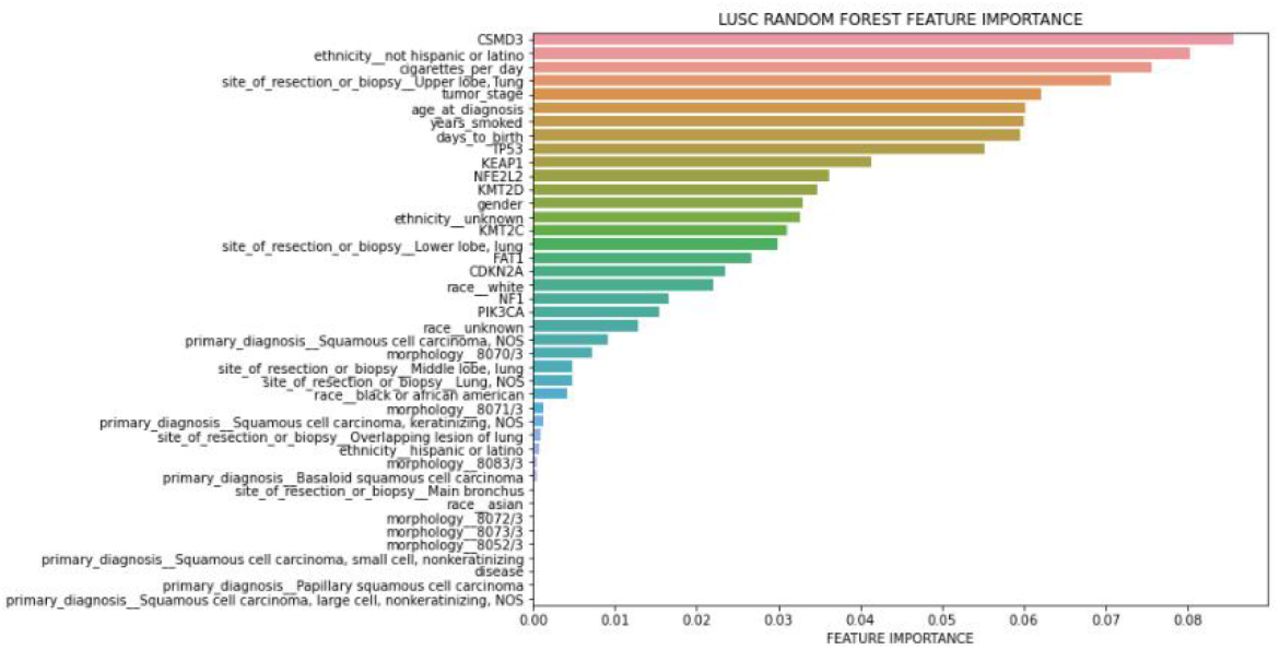
4.2 Random Forest Feature Importance
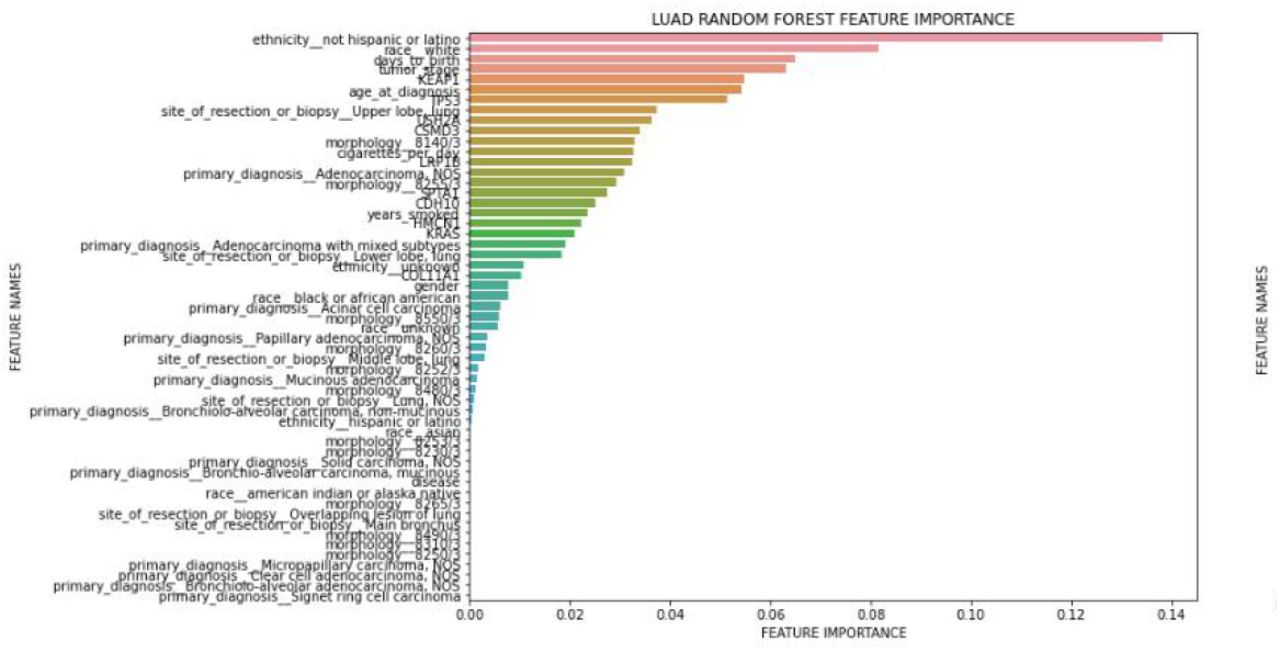
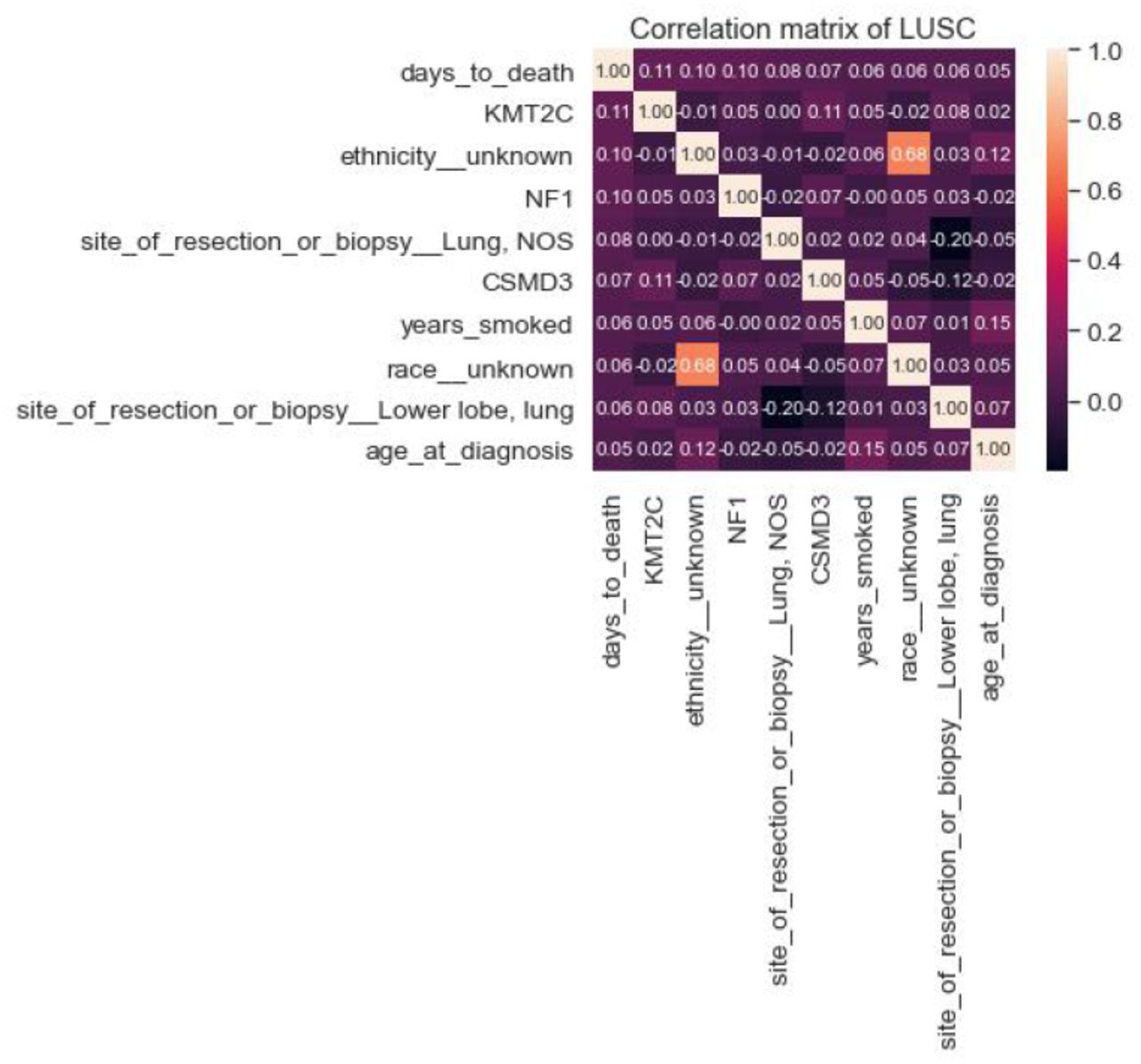
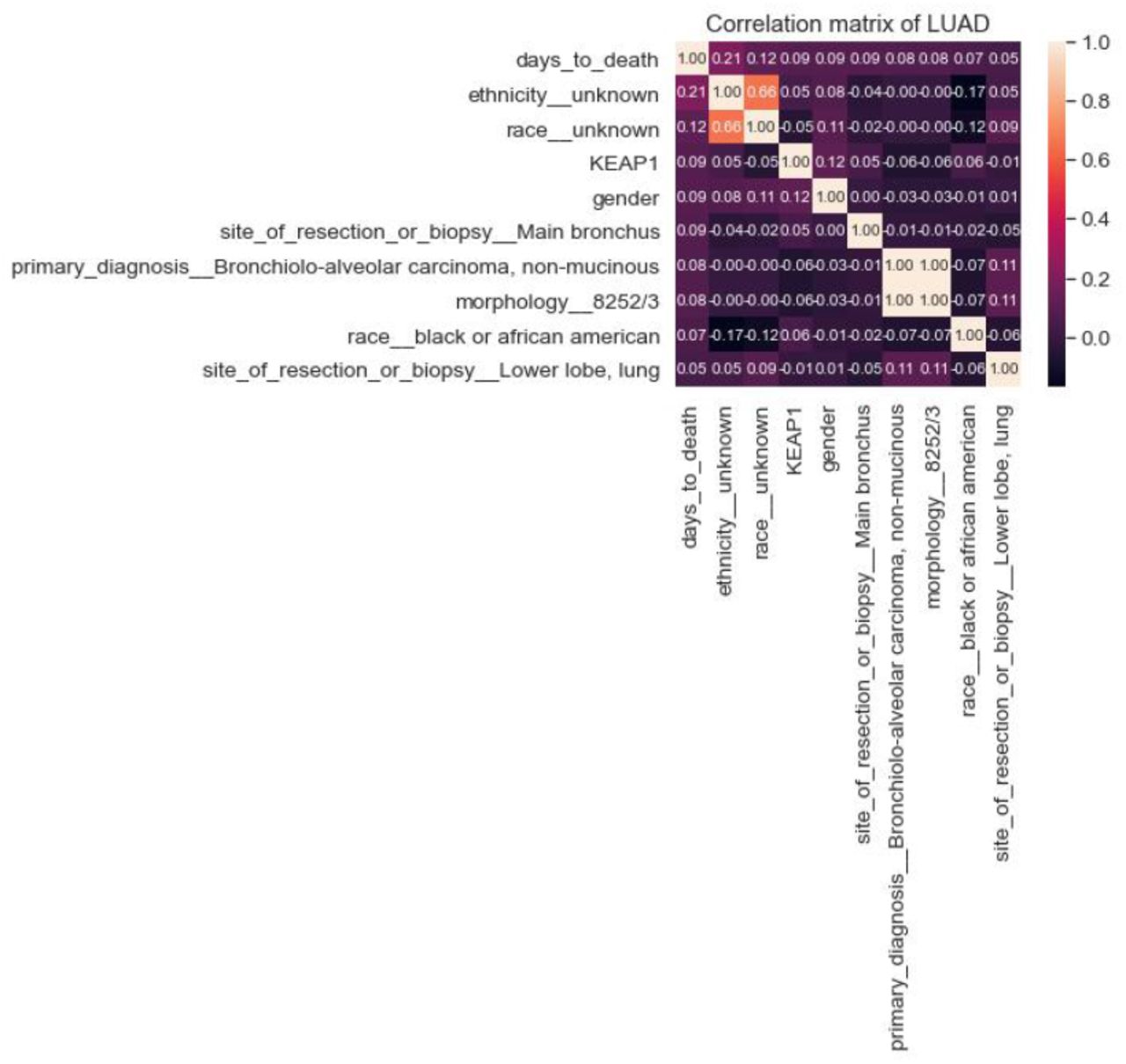
The feature selection techniques select a subset of the most relevant features according to the target feature. The main goal of choosing the most relevant features is running the algorithms more efficiently to space and time complexity problems. Irrelevant input features can mislead the machine learning algorithms resulting in worse performance. In this work, we plotted the feature importances on two sets of features; 1) Full set of clinical features and 2) top 10 somatically mutated driver genes. Importance ranking of the features are provided by the fitted attribute feature_importances_of the scikit-learn Python machine learning library. The feature importances are computed as the mean and standard deviation of accumulation of the impurity decrease within each tree (Figure 6 and Figure 8). We also plotted the top 9 most correlated features to days_to_death (Figure 7 and Figure 9).

Importance ranks of LUAD clinical features only

Top 9 most correlated LUAD clinical features to days_to_death

Importance ranks of LUSC clinical features only

Top 9 most correlated LUSC clinical features to days_to_death
5. SOMATICALLY MUTATED GENES
In this section, we researched which somatically mutated genes effect the risk classification by feature engineering. For this, we combined the top 10 most highly mutated somatic driver genes as genomic features as well as the clinicopathological features. For this purpose, we selected the top 10 most highly mutated somatic driver genes for LUAD, and LUSC identified in our previous publication [16] using SominaClust[17].
The top 10 most somatically mutated driver gene features for LUAD patients were CDH10, COL11A1, CSMD3, HMCN1, KEAP1, KRAS, LRP1B, SPTA1 TP53, USH2A. When we tried to find a correlation between the risk of the patient (high-low) and these ten genes, KEAP1, TP53, USH2a and CSMD3 popped up in the top 10 feature list. We also observed that there is a coefficient correlation between ’KEAP1’ and risk of the patient. Nevertheless, there was no significant improvement in the performance of the LUAD Logistic Regression and Random Forest model after the addition of the mutated genes. (Figure 10 and Figure 11). Performance of each five-folds can be observed in Table 7 with a mean and standard deviation of folds. Moreover, KEAP1 mutation has higher feature importance followed by TP53, USH2A, CSMD3, LRP1B, SPTA1, CDH10, HMCN1, KRAS and COL11A1. Mutated genes have higher importance than many clinical features, however, ethnicity and race have highest feature importance, interestingly. Mostly used clinical variables such as age and tumor stage have higher importance than gene mutations. Site of resection, morphology, primary diagnosis, smoking amount have importance along with the gene mutations. Although adding gene mutations did not improve the performance, they have high importance with clinical variables, therefore they can be used together. For example, loss of function mutations in KEAP1 gene, promote KRAS-driven lung tumorigenesis [18] that may be reason of correlation of KEAP1 with risk of patients, therefore using KEAP1 and KRAS together with clinical variables can be considered.
Accuracies of each fold for LUAD model with clinical features and top 10 somatically mutated genes

Importance ranking of LUAD top 10 somatically mutated genes and clinical features

Top 9 most correlated LUAD clinical features and top10 somatically mutated genes to days_to_death
Although addition of the top 10 most highly mutated somatic driver genes to the classification model did not improve the performance of LUAD patients, they vastly improved the classification model of LUSC patients (Table 8). Top 10 somatically mutated genes of LUSC patients reported in our previous publication were CDKN2A, CSMD3, FAT1, KEAP1, KMT2C, KMT2D, NF1 NFE2L2, PIK3CA, TP53 [16]. The correlation between the risk of the patient (high vs low) and the given ten genes, the CSMD3 gene, impacted the model most by improving both the Logistic Regression and Random Forest performance in LUSC (Figure 12 and Figure 13). CSMD3 is one of the most frequently mutated genes in lung cancer and it is a potential tumor-suppressor [19]. Ethnicity is the second most important feature and smoking amount has high importance with age and tumor stage followed by TP53, KEAP1, NFE2L2, KMT2D, KMT2C, FAT1, CDKN2A, NF1 and PIK3CA gene mutations.
Accuracies of each fold for LUSC model with clinical features and top 10 somatically mutated genes

Importance ranking of LUSC top 10 somatically mutated genes and clinical features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Top 9 most correlated LUSC clinical features and top10 somatically mutated genes to days_to_death
6 DISCUSSION
Main goal of our study was to investigate the clinical features or biomarker genes that are most helpful in prediction of risk stratification of lung adenocarcinoma and lung squamous carcinoma patients. For this purpose, we employed several machine learning studies investigating the vast clinical feature set and top 10 most somatically mutated gene set of TCGA lung adenocarcinoma and lung squamous carcinoma patients and ranked the features that contributed to the risk stratification most. Overall, clinic features still have importance even when gene mutations are added to analysis and can be considered to use with gene mutations. As a result of this analysis, new genes such as KEAP1 for LUAD and CSMD3 for LUSC with new clinicopathological features such as site of resection can be added to clinical decision processes. Future work of our model involves incorporating these developed machine learning models to a user-friendly web interface enabling both clinicians and lung cancer patients to assess the patients’ risk stratification.
Data Availability
All data produced are available online at TCGA
References



