
Abstract
Background Administrative healthcare claims databases are used in drug safety research but are limited for investigating the impacts of prenatal exposures on neonatal and pediatric outcomes without mother-infant pair identification.
Objective We developed a mother-infant linkage algorithm and evaluated it in two, large US commercially insured populations.
Study Design We used two US commercial health insurance claims databases during the years 2000 to 2021. Mother-infant links were constructed where persons of female sex 12-55 years of age with a pregnancy episode ending in live birth were associated with a person who was 0 years of age at database entry, who shared a common insurance plan ID, had overlapping insurance coverage time, and whose date of birth was within ±60-days of the mother’s pregnancy episode live birth date. We compared the characteristics of linked vs non-linked mothers and infants to assess similarity.
Results The algorithm linked 3,477,960 mothers to 4,160,284 infants in the two databases. Linked mothers and linked infants comprised 73.6% of all mothers and 49.1% of all-infants, respectively. 94.9% of linked infants’ dates of birth were within ±30-days of the associated mother’s pregnancy episode end dates. Linked mothers were older, had longer pregnancy episodes, and had greater post-pregnancy observation time than mothers with live births who did not meet linkage algorithm criteria. Linked infants had less observation time and greater healthcare utilization than non-linked infants. Other characteristics were similar in linked vs non-linked mothers and infants.
Conclusion We developed a mother-infant linkage algorithm and applied it to two US commercial healthcare claims databases that achieved a high linkage proportion and demonstrated that linked and non-linked mother and infant cohorts were similar. Transparent, reusable algorithms applied to large databases enables large-scale research on exposures during pregnancy and pediatric outcomes with relevance to drug safety. These features suggest that prenatal exposure causal risk assessment that uses this algorithm can produce valid and generalizable evidence to inform clinical, policy, and regulatory decisions.
Key points A. Why was this study conducted?
-This study establishes reliable mother-infant links in two US commercial healthcare databases to facilitate research on prenatal exposures and infant health outcomes
B. What are the key findings?
-Linked mothers with live births comprise 73.6% of all mothers with live births and linked infants comprise 49.1% of all infants
-Linked vs. non-linked mother and infant cohorts have similar demographic and clinical profiles
-Substantial linked coverage and linked vs non-linked characteristic similarity suggests that prenatal exposure causal risk assessment using the linked cohorts will produce valid and generalizable evidence
C. What does this study add to what is already known?
-This study created large mother-infant linked cohorts to enable research on rare exposures and outcomes available in healthcare claims databases
-Linked mother and infant coverage is similar to that reported in previous linkage studies
-Descriptive comparisons between linked vs. non-linked mother and infant cohorts increases confidence that results from research on linked cohorts also apply to mother and infant populations that do not meet linkage algorithm criteria
-This mother-infant linkage algorithm is publicly available and easily implemented in databases converted to a common data model
Introduction
Pregnancy is characterized by distinct periods of embryonic development representing critical exposure windows for children’s health [1]. Exposures before or during pregnancy, including pharmaceuticals, can affect conception, fetal development, pregnancy outcomes, and children’s health. While up to 90% of women take medication during pregnancy[2, 3], drug safety evidence is scarce because clinical trials often exclude pregnant people[4–6]. Mechanisms for generating pregnancy drug safety evidence are available, such as teratology information services[7], pregnancy and birth registries [8–12], case control studies[13], prospective cohort studies[14], and linked registry and prescription data resources[15]. However, these approaches often lack power to adequately assess rare exposures or outcomes, suffer from information biases, are slow to deliver results, may reflect selected populations, and are resource intensive. This research landscape produces an incomplete understanding of the benefits and risks of prenatal medication use and resultant birth outcomes. Further, the COVID-19 pandemic highlighted the need for timely, robust evidence on the benefit and risks of prenatal vaccine use.
Calls have been made to use real-world data (RWD) to study medication effects in pregnancy and are increasingly accepted by health authorities as part of post-authorization safety commitments[16, 17]. Large, administrative healthcare databases for pregnancy research are advantageous because they include large samples, multi-therapeutic area drug dispensing and diagnosis reimbursement claims, longitudinal patient observation, and reflect routine-care clinical practice.
To assess prenatal exposures on infant outcomes in RWD requires implementing algorithms to define pregnancy episodes and to link live births to infant records, which is challenging in the United States where national health record identifiers are absent. Mother-infant linkage has been conducted US administrative healthcare databases, including among Medicaid, commercially-insured, and Military Health System populations[18–23]. Other efforts, such as the Medication Exposure in Pregnancy Risk Evaluation Program (MEPREP)[24, 25], have linked administrative and electronic health record data to state birth records. However, details on linkage confidence and evaluation are sparse[26].
Our study builds on past efforts to create mother-infant linked cohorts in RWD. We created the largest known cohorts of mother-infant linked data using two large, US commercial insurance databases. In contrast to other linkage studies that use proprietary algorithms, our algorithm is publicly available. The algorithm was developed for use against the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) [27, 28], so it may be applicable to similar databases that have been standardized. Our linkage algorithm furthers earlier linkage work based on insurance enrollment ID matching only, by applying additional temporal criteria intended to increase linkage confidence. We evaluated the algorithm through comprehensive characterization comparisons between linked and non-linked mothers and infants.
Materials and Methods
Data sources
The study used two health insurance claims databases, IBM® Marketscan® Commercial Database (CCAE)[2000–2022] and Optum’s de-identified Clinformatics® Data Mart Database (Clinformatics®)[2000–2021]. Both contain de-identified, patient-level, encounter-based, longitudinal, employer-based US administrative health insurance claims records and include inpatient and outpatient diagnoses, procedures, and outpatient prescription dispensing records. Both databases use a unique insurance enrollment ID for identifying beneficiaries and their dependents under a single, primary insurance holder account. Both databases were transformed to the OMOP CDM, which provides a standardized representation of database structure and clinical content[29] to enable consistent analysis across disparate healthcare databases[30, 31].
Linkage algorithm
The linkage algorithm relies on and is distinct from identifying pregnancy episodes and outcomes[32]. The pregnancy episodes algorithm was previously described, implemented, and validated in several administrative healthcare databases, including those in this study[32]. Briefly, it identifies pregnancy outcomes and estimates pregnancy start and end dates using a hierarchy of pregnancy markers, such as last menstrual period, amenorrhea, urine tests, ultrasounds, and delivery procedures in females aged 12-55 years.
Step 1: Identify candidate mothers and infants
We first identified candidate mothers as females whose pregnancy episode(s) ended with live birth and occurred during a period of insurance enrollment.
Multiple periods of insurance enrollment were combined into a single observation period provided gaps between an enrollment period end and subsequent start date were ≤30 days. We identified candidate infants as persons whose year of birth was the same as their first observation period start year (i.e., were 0 years of age at observation period start) and had an insurance enrollment ID shared with a candidate mother. Candidate infants’ date of birth (DOB) was set as year, month, and day. Year of birth was available for all persons in both databases. Where month and day were unavailable, we inferred these components from observation period start month and day. Most day of birth values were set as 1 because insurance enrollment typically begins on the first day of a month.
Step 2: Identify candidate mother-infant links
We identified candidate links between mothers and infants where they matched on insurance enrollment ID and the candidate infant’s DOB occurred during a candidate mother’s observation period.
Step 3: Classify probable mother-infant links
We identified probable links between mothers and infants by restricting to those where the candidate infant’s DOB occurred within ±60 days of the candidate mother’s pregnancy episode end date. This correspondence window was varied in a sensitivity analysis (Appendix Section A).
Step 4: Exclude ambiguous mother-infant links
In Step 2, we identified rare instances where multiple mothers could be associated with a single infant. These records were excluded from analysis.
Cohorts used in algorithm evaluation
Nine cohorts were constructed to compare characteristics between linked vs non-linked mothers and infants. The index date refers to the temporal reference against which covariates were constructed.
1) Mothers linked to ≥1 infant indexed at pregnancy episode start
2) Mothers linked to ≥1 infant indexed at pregnancy episode end
3) Infants linked to a mother indexed at pregnancy episode end
4) Mothers not linked to an infant indexed at pregnancy episode start
5) Mothers not linked to an infant indexed at pregnancy episode end
6) Infants not linked to a mother indexed at inferred DOB
7) Candidate mothers indexed at pregnancy episode start
8) Candidate mothers indexed at pregnancy episode end
9) Candidate Infants indexed at DOB
Characterization analyses
We characterized mother cohorts relative to each index date: once with covariates that reflect events observed during the year before or on the pregnancy episode start date, and again with covariates that reflect events observed during the year before or on the pregnancy episode end date. We characterized the infant cohorts with covariates that reflect events observed on or during the year after the pregnancy episode end date. See Appendix Section B for demographic and clinical covariate details.
We compared characteristics between linked vs. non-linked mothers and infants to evaluate differences between populations that did and did not meet linkage algorithm criteria. We made covariate comparisons by calculating the standardized mean difference (SMD) for each covariate in units of the pooled standard deviation, a metric uninfluenced by large sample sizes[33], and interpreted SMD values >0.1 as meaningfully different[34, 35].
Results
All source code and an interactive application for viewing full results is available at https://data.ohdsi.org/MotherInfantLinkEval/.
Figure 1 depicts step-by-step attrition of the linkage algorithm.

Mother-infant linkage algorithm attrition diagram. Primary algorithm implementation: first births, ±60-day pregnancy episode end/infant date-of-birth correspondence. CCAE: IBM® Marketscan® Commercial Database; Optum: Optum’s de-identified Clinformatics® Data Mart Database.
In CCAE, 3,064,263 candidate mothers and 2,942,216 candidate infants were identified in Step 1, of whom 26.8% and 1.4% were dropped respectively during Step 2, resulting in 2,915,538 candidate links. Links were reduced by 13.2% and 0.1% in steps 3 and 4 respectively, which resulted in 2,528,482 links: 2,146,726 linked mothers, and 2,528,482 linked infants. 31.3% of linked infant’s DOB were on the same day as their linked mother’s pregnancy episode end date and 58.3%, 71.5%, and 92.1% occurred within ±7 days, ±14 days, and ±30 days, respectively. Linked infant’s DOB was on average 5.9 days (SD=15.1, median=1) after the pregnancy episode end date. Linked mothers comprised 70.1% of all mothers (n=3,064,263) and linked infants comprised 51.2% of all infants (n=4,935,376)(Appendix Table C1).
In Clinformatics®, 1,684,615 candidate mothers and 1,823,690 candidate infants were identified, of whom 20.6% and 1.4% were dropped respectively during Step 2, resulting in 2,086,438 candidate links. Links were reduced by 12.9% and 12.5% in steps 3 and 4 respectively, which resulted in 1,589,010 links: 1,301,623 linked mothers and 1,589,010 linked infants. 67.4% of linked infant’s DOB were on the same day as their linked mother’s pregnancy episode end date and 98.0% 98.6%, and 99.3% occurred within ±7 days, ±14 days, and ±30 days, respectively. Linked infants’ DOB was on average 0.7 days (SD=4.0, median=0) after the pregnancy episode end date. Linked mothers comprised 77.3% of all mothers (n=1,684,615) and linked infants comprised 47.0% of all infants (n=3,379,811)(Appendix Table C1).
Table 1 reports characteristics and SMDs of linked vs non-linked mothers for several characteristics measured relative to pregnancy episode start date. Pregnancy episode starts were equally distributed by year over the study period, although index dates in non-linked mothers were more common in February and March in CCAE. Mean age was greater among linked mothers in both databases (CCAE: 31.2 vs 27.4 years, Clinformatics®: 30.9 vs 27.9 years). There was greater post-pregnancy mean observation time among linked mothers in both databases (CCAE: 1358 vs 960 days, Clinformatics®: 1221 vs 930 days) and mean pregnancy episode length was greater among linked mothers in CCAE (273 vs 270 days). Linked vs non-linked mothers did not differ in clinical event counts, healthcare utilization, and health status in either database.
Selected characteristics and standardized differences of linked and non-linked mothers in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Mother characteristics were measured on the pregnancy episode start date (index year and month, age) or during the 365-day period before and including the pregnancy episode start date (distinct event occurrence counts). Primary algorithm implementation: all births, ±60-day pregnancy episode end/infant date-of-birth correspondence.
Table 2 reports characteristics and SMDs of linked vs non-linked mothers for the same characteristics as Table 1 except for pregnancy episode length but were measured relative to pregnancy episode end date. Age was greater among linked mothers in CCAE (32.0 vs 30.9 years), which reflects the slightly greater linked pregnancy episode lengths reported above. There was greater post-pregnancy observation time among linked mothers in both databases (CCAE: 1084 vs 690 days, Clinformatics®: 948 vs 660 days). Although uncommon, emergency room visits were greater among non-linked mothers in CCAE (0.7 vs 0.3).
Selected characteristics and standardized differences of linked and non-linked mothers in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Mother characteristics were measured on the pregnancy episode end date (index year and month, age) or during the 365-day period before and including the pregnancy episode end date (distinct event occurrence counts). Primary algorithm implementation: all births, ±60-day pregnancy episode end/infant date-of-birth correspondence.
Table 3 reports characteristics and SMDs of linked vs non-linked infants for several characteristics measured at the pregnancy episode end date. Non-linked births were more common in the early study period (2000-2002) in both databases and in CCAE linked births were more common in January. There was greater post-birth observation time among non-linked infants in both databases (CCAE: 886 vs 454 days, Clinformatics®: 751 vs 601 days). Condition (CCAE: 6.7 vs 5.7, Clinformatics®: 7.7 vs 6.4) and procedure (CCAE: 12.8 vs 9.9, Clinformatics®: 12.3 vs 10.0) occurrences were greater among linked infants. Healthcare utilization (i.e., outpatient and inpatient visits) was similarly greater among linked infants.
Selected characteristics and standardized differences of linked and non-linked infants in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Infant characteristics were measured on the pregnancy episode end date (index year and month, age, sex) or during the 365-day period after and including the pregnancy episode end date (distinct event occurrence counts). Primary algorithm implementation: all births, ±60-day pregnancy episode end/infant date-of-birth correspondence.
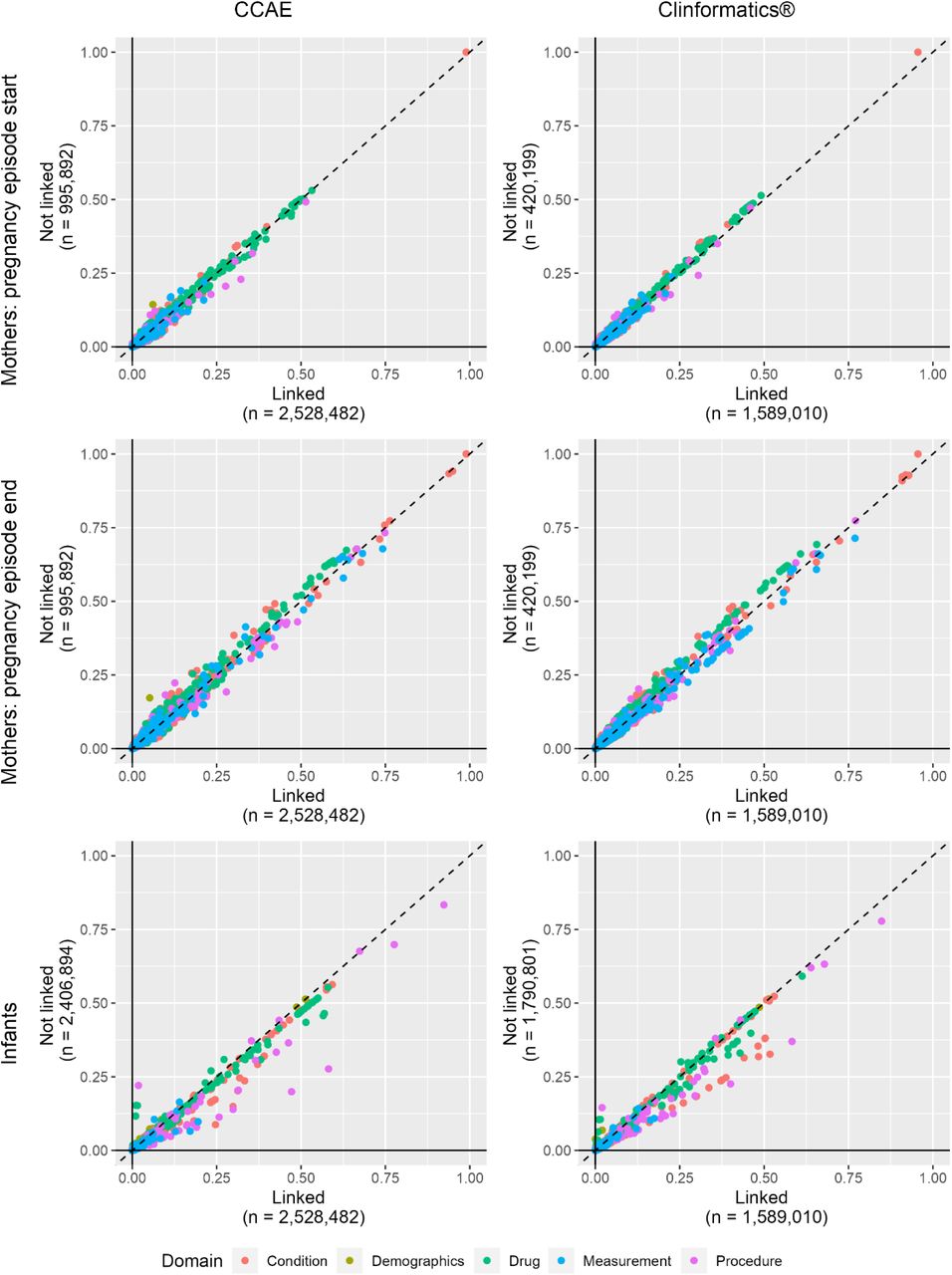
Figure 2 depicts the comparative prevalence of demographic, drug exposure, condition, procedure, and measurement occurrence covariates for the linked vs non-linked mother and infant cohorts.

Demographic, drug exposure, condition, procedure, measurement, and visit occurrence covariate prevalence comparing linked vs. non-linked mother cohorts indexed at pregnancy episode start (row 1), linked vs non-linked mother cohorts indexed at pregnancy episode end (row 2) in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Primary algorithm implementation: all births, ±60-day pregnancy episode end/infant date-of-birth correspondence. CCAE: IBM® Marketscan® Commercial Database; Optum: Optum’s de-identified Clinformatics® Data Mart Database. The x-axes display the prevalence of each covariate in the linked populations and the y-axes display the prevalence of each covariate in the non-linked population. Data points that lay on the diagonal represent covariates that are equally prevalent in the linked and non-linked populations. Data points to the right the diagonal represent covariates that are more prevalent in the linked populations and those to the left are more prevalent in the non-linked populations.
The plots illustrate that the characteristics of linked and non-linked mothers were generally similar. However, infant characteristics, including conditions, measurements, drugs, and procedures were more prevalent among linked vs. non-linked infants. Large SMD covariates with greater prevalence among the linked infants included procedural billing records related to infant care, infant screening procedures, immunizations, and some conditions (see interactive web application to review all characteristics). We also observed a greater prevalence of birth-related covariates among linked infants than non-linked infants (e.g., “Single live birth”, ”Finding related to pregnancy”). Despite these differences, we still observed absolute SMDs of <0.1 for >99% of covariates across all algorithm implementations of each linked vs non-linked comparison in both databases where the number of covariate comparisons ranged from 58,611 (CCAE infants) to 68,368 (Clinformatics® mothers pregnancy end).
The final person and record counts for each of the 9 cohorts constructed by the 3 linkage algorithm implementations in each database are reported in Appendix Table C1. Result sets for the two algorithm sensitivity implementations are reported in Appendix Sections D and E. We observed similar stepwise attrition proportions across sensitivity implementations. Attrition proportions in the first births sensitivity implementation were greater in Step 3 because this is where first birth restrictions were made. There were no appreciable differences in linked vs. non-linked mother and infant characteristics across algorithm sensitivity implementations.
Comment
Principal Findings
We developed and implemented an algorithm to infer mother-infant links in two large US commercial healthcare databases that exhibited high linkage coverage and similar characteristics across linked vs. non-linked persons. This signifies generalizability of linked mother-infant pairs to commercially insured populations, which facilitates large-scale research on prenatal exposures and infant outcomes.
Our algorithm identified >3.4 million linked mothers and >4.1 million linked infants, which to our knowledge, makes these among the largest mother-infant linked cohorts constructed. Access to large, linked populations makes feasible the study of a wide range of prescription drug exposures, maternal and neonatal outcomes, and subgroups that are often unavailable in smaller linked populations[36, 37] and registries[38–40]. This approach requires fewer study resources compared to studies that require primary data collection[41].
Results in the Context of What is Known
Across databases, linked mothers comprised 73.6% of all mothers with live births. In Clinformatics®, 77.3% of mothers were successfully linked to infants, which is lower but comparable to the 84% reported in a recent study using data from the same source with fewer linkage restrictions [18]. Despite similar methods, other linkage studies have reported mixed linkage coverage, suggesting that differences are due to data accuracy and/or availability variation across sources. Palmsten et al. linked Medicaid-enrolled mothers and infants and reported linkage coverage of 55.6% for inpatient deliveries, although with considerable variation by state (0-96%)[22], which the authors attribute to varying family identifier quality. A study in TRICARE enrollees in the Military Health System reported 90% of pregnancies ending in live births were linked with infants[42], which may be attributable to lower insurance coverage churn.
In our study, linked infants comprised 49.1% of all infants defined as persons 0 years of age at their observation period start. Contextualizing our linked infant coverage is difficult because most studies only report the proportion of linked pregnancies[18, 22]. However, Garbe et al. conducted a study using the German Pharmacoepidemiological Research Database (GePaRD), a claims database from four statutory health insurance providers, and reported that 77.3% of newborns were linked with mothers[43]. Additionally, a study among Medicaid enrollees in Tennessee reported 97% of infants were linked with a delivery, however such high coverage is likely explained by the use of vital record data with identifying information[37].
While our primary analysis used a ±60-day window between infant DOB and mothers’ pregnancy episode end to identify candidate links, in sensitivity analyses, we observed high correspondence at 7, 14, and 30 days, including same-day correspondence of 31.3% in CCAE and 67.4% in Clinformatics®. Overall correspondence was greater in Clinformatics®, which may be due to more accurate and specific DOB information. Increasing the correspondence window to 90 days increased the proportion of linked infants by 1.5% in CCAE and 0.2% in Clinformatics®, which we do not interpret as material because most of the correspondence occurs within ±30 days.
Clinical and Research Implications
Characteristic comparisons between linked and non-linked mothers revealed similar demographic, health, and healthcare utilization profiles. Our linkage evaluation largely supports the generalizability of the linked mother population, having compared thousands of covariates between linked and non-linked mother cohorts and observing few differences. We found that SMDs were <0.1 for nearly all observed characteristics, suggesting that in a prenatal exposure study on a small, exposed subset of the linked mother population, systematic differences between the study sample and non-linked mothers to whom the results will apply will be minimal.
Despite substantial similarity between linked and non-linked infants, we observed more differences than when comparing mothers. Of note, linked infants had greater total healthcare utilization and prevalence of individual clinical events, including birth and infant-care related claims. Because our algorithm linked mothers to infants by a shared insurance ID within a defined temporal interval, candidate infants whose inferred DOB fell outside of that interval would be non-linked and less likely to have their clinical events captured in the database. This suggests that some billing records may be attributed to family members on other insurance plans among the non-linked populations. Still, this evaluation supports the generalizability of the linked infant population.
Strengths and Limitations
A strength of our study is the rigorous linkage approach utilizing insurance ID in addition to delivery and birth procedure dates in large US claims databases representing the commercially insured population. Other studies have used related methods successfully[18, 22, 23, 43]. Further, we provide open-source code and a web-application for interactive characterization results, which provides valuable context for the external validity of future studies among linked populations. Additionally, our linked populations are larger than other mother-infant linked databases such as such as MEPREP (1,221,156 linked infants)[24, 25], the US Military Health System (827,753 linked live births)[23], GePaRD (250,355 linked live births), Medicaid Analytic Extract (1,173,280 linked pregnancies)[22], and Optum’s de-identified Clinformatics® Data Mart Database (524,227 linked live births)[18]. Lastly, developing a reproducible mother-child linkage algorithm in large administrative databases facilitates evidence generation in pregnant populations with improved rigor by avoiding recall, referral, and self-selection biases inherent to registry or other primary data collection studies of prenatal medication use[39].
Using administrative healthcare claims databases in pharmacoepidemiologic research has limitations. Erroneously coded or missing diagnostic, procedure, and drug dispensing records results in misclassification which may under- or over-estimate exposures, covariates, health outcomes, other clinical events, and healthcare utilization[44]. Subsequent information bias that can result from misclassification is underappreciated[45] and could bias findings of future drug safety studies. Still, developing reliable mother-infant linkages in large healthcare databases has increased the capacity to examine associations between rare prenatal drug exposures and infant outcomes with sufficient power. For example, prenatal use of antidepressants, stimulants, antihypertensive medications, and sulfonamides have been studied in relation to validated congenital anomalies[46–50]. This has yielded needed real-world evidence on the safety of prenatal exposures.
While we found few differences between linked and non-linked populations suggestive of high internal validity to the underlying commercially insured US population, our results do not necessarily ensure external validity to those covered under other types of insurance or lacking coverage. The data in this study are representative of people with US-based, employer-sponsored health insurance. Further, administrative healthcare databases include detailed outpatient drug dispensing records but provide fewer details on inpatient dispensing records, prescriptions, or administrations typically available in electronic medical records. Lastly, our study has not been validated. However validation of a similar algorithm developed in claims data among Medicaid beneficiaries showed high positive predictive value[51].
Conclusions
Our study reinforces the shift towards implementing pharmacoepidemiology studies on prenatal drug exposures utilizing large electronic healthcare data as a supplement to traditional pregnancy registries. Our algorithm and evaluation demonstrate the ability to assemble large mother-infant linked cohorts for investigating prenatal drug exposure effects on infant outcomes.
Data Availability
All source code and an interactive application for viewing full results is available at https://data.ohdsi.org/MotherInfantLinkEval/.
A. Algorithm sensitivity implementation descriptions
The primary linkage algorithm implementation identified all births for a given mother and required ±60-day correspondence between the infant’s date of birth (DOB) and the mother’s pregnancy episode end date as described in Step 3. The first sensitivity analysis limited results to first births per mother only and maintained the ±60-day correspondence between the infant’s DOB and the mother’s pregnancy episode end. The second sensitivity analysis identified all births for a given mother and increased the correspondence between the infant’s DOB and the mother’s pregnancy episode end to ±90-days. The intent of limiting to first births was to assess whether linked and non-linked mother characteristic differences depended on multiparous status. The intent of extending the pregnancy end/DOB correspondence was to increase linkage sensitivity given that some day of birth values were inferred as 1 from typical insurance enrollment start dates and new children may not be enrolled with coverage immediately after birth.
B. Covariate construction
Mothers were characterized by age in years, index year (i.e., year in which pregnancy started/ended), index month, pre- and post-index database observation time in days, pregnancy episode length in days, and the Charlson Comorbidity Index (CCI)1. Infants were characterized by sex, index year, index month, and post-index observation time in days. Both mothers and infants were characterized by verbatim condition (SNOMED-CT) and aggregated condition group (SNOMED-CT clinical finding level) occurrences, drug ingredient level (Unified Medical Language System - RxNorm) and aggregated drug group (World Health Organization Anatomical Therapeutic Chemical Classification System 3rd, 4th, and 5th levels) exposures, procedure occurrences, measurement occurrence (but not values), and counts of distinct conditions, drug ingredient exposures, procedures, and measurements. Health care utilization was characterized by proxy using visit counts and counts of specific visit types (outpatient, inpatient, emergency department). Continuous measures were reported with mean, standard deviation, and median and clinical event occurrences were reported as proportions. We chose pregnancy episode end as the index date for linked infants rather than the infant’s inferred DOB because live birth procedures are well-captured in claims data with reliable dates, whereas DOB information is limited or redacted as part of enrollment and de-identification and enrollment date is an imprecise birth marker.
C. Person and record counts
1) Linked mothers (pregnancy episode start)
Mothers linked to ≥1 infant indexed at pregnancy episode start
2) Linked mothers (pregnancy episode end)
Mothers linked to ≥1 infant indexed at pregnancy episode end
3) Linked infants
Infants linked to a mother indexed at pregnancy episode end
4) Not linked mothers (pregnancy episode start)
Mothers not linked to an infant indexed at pregnancy episode start
5) Not linked mothers (pregnancy episode end)
Mothers not linked to an infant indexed at pregnancy episode end
6) Not linked infants
Infants not linked to a mother indexed at inferred DOB
7) All candidate mothers (pregnancy episode start)
Mothers without infant linkage restrictions indexed at pregnancy episode start
8) All candidate mothers (pregnancy episode end)
Mothers without infant linkage restrictions indexed at pregnancy episode end
9) All candidate infants
Infants without linkage restrictions indexed at DOB
Person and record counts by database, algorithm implementation, and cohort
D. Linkage algorithm sensitivity implementation 1 evaluation results

Mother-infant linkage algorithm attrition diagram. Sensitivity algorithm implementation 1: first births, ±60-day pregnancy episode end/infant date-of-birth correspondence. CCAE: IBM® Marketscan® Commercial Database; Clinformatics®: Optum’s de-identified Clinformatics® Data Mart Database

Demographic, drug exposure, condition, procedure, measurement, and visit occurrence covariate prevalence comparing linked vs. non-linked mother cohorts indexed at pregnancy episode start (row 1), linked vs non-linked mother cohorts indexed at pregnancy episode end (row 2). Sensitivity algorithm implementation 1: first births, ±60-day pregnancy episode end/infant date-of-birth correspondence. CCAE: IBM® Marketscan® Commercial Database; Clinformatics®: Optum’s de-identified Clinformatics® Data Mart Database.
Selected characteristics and standardized differences of linked and non-linked mothers in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Mother characteristics were measured on the pregnancy episode start date (index year and month, age) or during the 365-day period before and including the pregnancy episode start date (distinct event occurrence counts). Sensitivity algorithm implementation 1: first births, ±60-day pregnancy episode end/infant date-of-birth correspondence.
Selected characteristics and standardized differences of linked and non-linked mothers in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Mother characteristics were measured on the pregnancy episode end date (index year and month, age) or during the 365-day period before and including the pregnancy episode end date (distinct event occurrence counts). Sensitivity algorithm implementation 1: first births, ±60-day pregnancy episode end/infant date-of-birth correspondence.
Selected characteristics and standardized differences of linked and non-linked infants in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Infant characteristics were measured on the pregnancy episode end date (index year and month, age, sex) or during the 365-day period after and including the pregnancy episode end date (distinct event occurrence counts). Sensitivity algorithm implementation 1: first births, ±60-day pregnancy episode end/infant date-of-birth correspondence.
E. Linkage algorithm sensitivity implementation 2 evaluation results

Mother-infant linkage algorithm attrition diagram. Sensitivity algorithm implementation 2: all births, ±90-day pregnancy episode end/infant date-of-birth correspondence. CCAE: IBM® Marketscan® Commercial Database; Clinformatics®: Optum’s de-identified Clinformatics® Data Mart Database

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Demographic, drug exposure, condition, procedure, measurement, and visit occurrence covariate prevalence comparing linked vs. non-linked mother cohorts indexed at pregnancy episode start (row 1), linked vs non-linked mother cohorts indexed at pregnancy episode end (row 2). Sensitivity algorithm implementation 2: all births, ±90-day pregnancy episode end/infant date-of-birth correspondence. CCAE: IBM® Marketscan® Commercial Database; Clinformatics®: Optum’s de-identified Clinformatics® Data Mart Database.
Selected characteristics and standardized differences of linked and non-linked mothers in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Mother characteristics were measured on the pregnancy episode start date (index year and month, age) or during the 365-day period before and including the pregnancy episode start date (distinct event occurrence counts). Sensitivity algorithm implementation 2: all births, ±90-day pregnancy episode end/infant date-of-birth correspondence.
Selected characteristics and standardized differences of linked and non-linked mothers in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Mother characteristics were measured on the pregnancy episode end date (index year and month, age) or during the 365-day period before and including the pregnancy episode end date (distinct event occurrence counts). Sensitivity algorithm implementation 2: all births, ±90d pregnancy episode end/infant date-of-birth correspondence.
Selected characteristics and standardized differences of linked and non-linked infants in IBM® Marketscan® Commercial Database and Optum’s de-identified Clinformatics® Data Mart Database. Infant characteristics were measured on the inferred pregnancy episode end date (index year and month, age) or during the 365-day period after and including the inferred pregnancy episode end date. (Distinct event occurrence counts). Sensitivity algorithm implementation 2: all births, ±90d pregnancy episode end/infant date-of-birth correspondence
Footnotes
Source of funding This work was conducted as part of employment at Johnson & Johnson.
Conflict of interest JW, JHH, CB, AAK, MHJ, and PBR are employees of Janssen Research and Development, a Johnson & Johnson company. JW, JHH, CB, and PBR hold stock in Johnson & Johnson.
Condensation This research developed and evaluated an algorithm to link mothers and infants in two US commercial healthcare databases to facilitate research on prenatal medication exposure and infant health outcomes.
↵1 Charlson, M.E., et al., A new method of classifying prognostic comorbidity in longitudinal studies: development and validation. J Chronic Dis, 1987. 40(5): p. 373-83.
References



