
Abstract
Background Utilizing large language models (LLMs), primarily ChatGPT, to interpret the seizure semiology with focal epilepsy could yield valuable data for presurgical assessment. Assessing the reliability and comparability of LLM-generated responses with those from well-trained neurologists, especially epileptologists, is crucial for ascertaining the value of LLMs in the presurgical evaluation.
Methods A total of 865 descriptions of seizure semiology and validated epileptogenic zone (EZ) pairs were derived from 189 public papers. These semiology records were utilized as input of ChatGPT to generate responses on the most likely locations of EZ. Additionally, a panel of 5 epileptologists was recruited to complete an online survey by providing responses on EZ locations based on 100 well-defined semiology records. All responses from ChatGPT and epileptologists were graded for their reliability score (RS) and regional accuracy rate (RAR).
Results In evaluating responses to semiology queries, the highest RARs in each general region from ChatGPT-4.0 were 89.28% for the frontal lobe and 71.39% for the temporal lobe. However, the RAR was lower for the occipital lobe at 46.24%, the parietal lobe at 31.01%, the insular cortex at 8.51%, and the cingulate cortex at 2.78%. Comparatively, the RAR achieved by epileptologists was 82.76% for the frontal lobe, 58.33% for the temporal lobe, 68.42% for the occipital lobe, 50% for the parietal lobe, 60% for the insular cortex, and 28.57% for the cingulate cortex.
Conclusions In this study of seizure semiology interpretation, ChatGPT-4.0 outperformed epileptologists in interpreting seizure semiology originating in the frontal and temporal lobes, whereas epileptologists outperformed ChatGPT-4.0 in the occipital and parietal lobes, and significantly outperformed in the insular cortex and cingulate cortex. ChatGPT demonstrates the potential to assist in the preoperative assessment for epilepsy surgery. Presumably, with the continuous development of LLM, the reliability of ChatGPT will be strengthened in the foreseeable future.
Introduction
Epilepsy is one of the most common neurological diseases affecting more than 70 million people worldwide [1], with approximately 50.4 per 100,000 people developing new-onset epilepsy each year [2, 3]. For those with drug-resistant focal epilepsy (DRE), surgical resection of the epileptogenic zone (EZ) may be curative. Seizure semiology, which refers to the description of signs and symptoms exhibited and experienced by a patient during epileptic seizures [4], yields valuable clues for the localization of the EZ [5]. In order to achieve optimal surgical outcomes, accurately interpreting the seizure semiology plays a crucial role in the preoperative assessment process.
Recently, large language models (LLMs), especially chatbots, have showcased their capabilities across a wide range of natural language processing (NLP) tasks. As a specific instance of LLM, ChatGPT developed by OpenAI [6] posited a dominant position in the current market for chatbot applications. ChatGPT, trained on a diverse database of text across different subjects, can resemble an expert equipped with a broad range of knowledge. In the field of medical informatics, ChatGPT exhibits an advanced proficiency in processing and interpreting extensive textual data upon any input prompt, making it a potent tool for information retrieval, clinical decision support, and medical report generation [7,8,9]. A study in February 2023 reported that ChatGPT has achieved success in passing the United States Medical Licensing Examination (USMLE) [10], demonstrating its potential as a reliable source of medical information.
The increasing application of ChatGPT in diagnosing various diseases inspired the idea of utilizing it to interpret seizure semiology, which may pioneer a novel tool for the surgical treatment of epilepsy [11,12]. However, since several previous studies have raised various concerns about the responses from ChatGPT may include incorrect or limited information [13,14], we, therefore, assess the reliability and accuracy of ChatGPT in seizure semiology interpretation by comparing its performance against that of a panel of Board-certified epileptologists. The descriptive nature of seizure semiology makes LLMs a natural fit for interpreting the associated clinical diagnosis. The semiotic texts were used to generate queries regarding the most likely locations of the EZs. All responses from ChatGPT and epileptologists underwent thorough review, with the addressed EZ locations being systematically cataloged and summarized. By evaluating and comparing responses from ChatGPT and epileptologists, this study provides an in-depth discussion of the strengths and limitations of AI-generated medical information and proposes directions for future research.
Methods
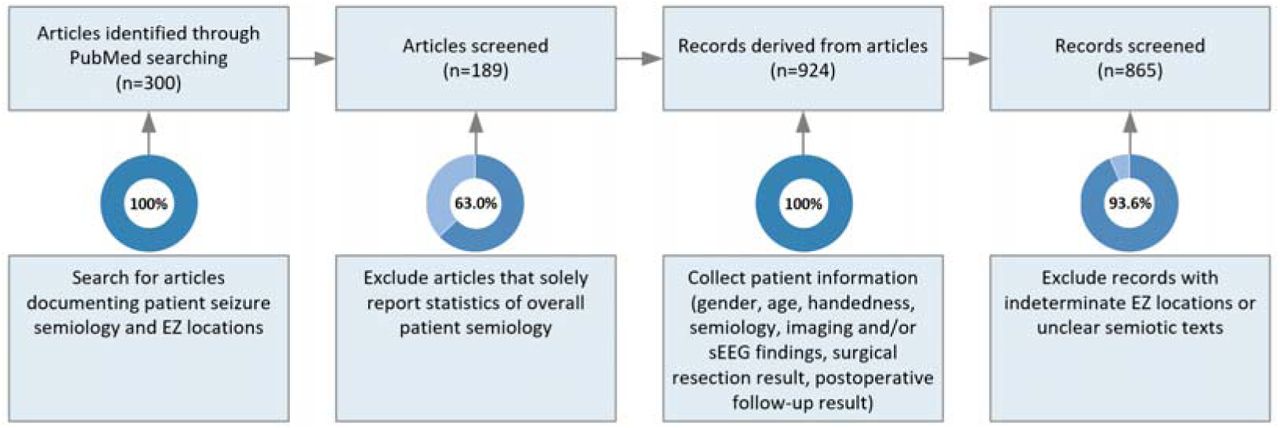
⍰ Database Source
We compiled an epilepsy-specific database by actively utilizing PubMed, a free search engine primarily accessing the MEDLINE database, to source 189 articles by searching for “seizures”, “clinical semiology”, and “epilepsy”, etc [15]. These selected articles documented over 900 epilepsy cases, detailing seizure semiology across various surgically validated EZ locations. These EZ locations (i.e., ground truth) were labeled based on postoperative outcomes (defined as seizure freedom after surgery), concordance of imaging and neurophysiology, or available stereoelectroencephalography (sEEG) findings [16]. Cases with indeterminate EZs or nonspecific semiology were excluded. For example, cases indicating only hemisphere-level EZs, like right hemispherectomy or left subtotal hemispherectomy, without general or specific regional details, were omitted. Additionally, cases described with nonspecific terms, like ‘non-specific aura’ or those aggregating a large patient cohort without providing detailed semiology for each individual, were excluded. The methodology for the data compilation is depicted in Figure 1. In addition, a thorough collection of patient data was compiled, encompassing demographics, seizure semiology, imaging and/or sEEG findings (if provided), and surgical results.

The resultant database comprised 865 patient-derived semiology-EZ pairs, with a demographic spread of 134 right-handed, 22 left-handed, 3 ambidextrous, and 706 unspecified handedness individuals, aged from newborn to 77 years. These semiology-EZ pairs indicate either single or multiple EZ locations. In documenting these locations, the majority of articles merely delineate the general region without providing detailed information on the specific regions of EZs for individual epilepsy cases. Consequently, there were more data on general regions than on specific regions. Besides, these articles present a straightforward anatomic classification for general regions: frontal lobe, parietal lobe, temporal lobe, occipital lobe, cingulate cortex, and insular cortex.
Nevertheless, the delineation of specific regions within these six broader areas presents complexities. First, despite the orthographic differences in EZ location terminology, such terms often refer to the same brain region. For example, ‘medial temporal’ and ‘mesial temporal’ both denote the same specific area within the temporal lobe. Second, specific regions within an individual general region cannot be readily identifiable by their name alone. For example, the frontal lobe includes regions such as the Precentral and Paracentral gyri; and within the parietal lobe lie the Supramarginal, Postcentral, and Precuneus.
In summary, to address the issues of inconsistent terminology and the ambiguity of region names that do not directly indicate their locations in descriptions of specific EZ (Epileptogenic Zone) regions across various studies, we have referenced a classification system from a website (FreeSurferWiki, LCN-CortLobes). This system organizes the data into six broad regions and over twenty uniquely identifiable specific regions, as detailed in reference [17].
⍰ Response Generation with ChatGPT
In this study, all 865 semiology records in our self-compiled database were leveraged to investigate the capabilities of ChatGPT in accurately identifying the most probable location of the EZ using seizure semiology as inputs. The evaluation encompassed two versions of ChatGPT: ChatGPT-3.5 and ChatGPT-4.0. Additionally, two distinct prompt configurations: zero-shot prompting (ZSP) [18] and few-shot prompting (FSP) [19] were incorporated to examine their influence on the performance of ChatGPT. In the ZSP configuration, ChatGPT received no preliminary information; in the FSP configuration, the input consisted of three semiology-EZ pair examples intended to steer the responses to align with the ground truth (Table 1) more accurately.
Given that consecutive interactions within the same chat session might influence the responses of ChatGPT due to its stateful nature, we adopted a stringent methodology where each query was entered in a separate “New Chat” session to mitigate any potential bias or interference. The query section was conducted over a period extending from December 2023 to January 2024.
⍰ Response Collection from Epileptologists
To conduct the comparison between ChatGPT and epileptologists in seizure semiology interpretation, a panel of eight epileptologists with an average of 10 years of experience in treating epilepsy patients were recruited to complete an online survey on semiology interpretation (https://survey.zohopublic.com/zs/NECl0I). In this survey, we selected a representative subset of 100 semiology records that spanned all six general regions from our previously mentioned self-compiled database to seek the epileptologists’ opinions on the most likely EZ. The selection of semiology records fulfilled the following criteria that have been reviewed by epileptologists: (1) selected semiology records provided comprehensive and explicit descriptions of seizure symptoms; (2) the distribution of EZs corresponding to selected semiology records involved all six general regions, rather than being concentrated in a particular region; (3) the selection of semiology records was intended to capture the broadest possible range of seizure symptoms.
All responses for the survey were collected during the period from January 2024 to February 2024. We found doctors specializing in epilepsy from the National Association Epilepsy Center and American Epilepsy Society and sent out more than 70 survey invitations across the world. Consequently, five epileptologists completed the survey in full and three others completed it partially.
⍰ Statistical Analysis
To facilitate a precise and logical assessment of the responses provided by ChatGPT and epileptologists, two bespoke statistical metrics were introduced: the Reliability Score (RS) and the Regional Accuracy Rate (RAR).
First, the RS quantifies the accuracy of responses, where a score of 1 indicates 100% correct identification of EZ locations, aligning perfectly with ground truth. Scores below 1 suggest partial accuracy by ChatGPT or epileptologists, while those under 0 may represent misleading information, potentially complicating preoperative evaluations by neurologists. The RS is calculated as:
 where NT denotes the total count of EZs identified in the ground truth for a given semiology case. NC and NT respectively represent the counts of correct and incorrect identifications made by ChatGPT or epileptologists, relative to the ground truth of each epilepsy case. A correct identification (NC) positively contributes with a weight of α = 1, while an incorrect one (Ni) carries a negative weight of β = –0.5 to account for its potential to mislead epileptologists in determining the correct EZ location.
where NT denotes the total count of EZs identified in the ground truth for a given semiology case. NC and NT respectively represent the counts of correct and incorrect identifications made by ChatGPT or epileptologists, relative to the ground truth of each epilepsy case. A correct identification (NC) positively contributes with a weight of α = 1, while an incorrect one (Ni) carries a negative weight of β = –0.5 to account for its potential to mislead epileptologists in determining the correct EZ location.
Second, the RAR is a region-specific metric designed to evaluate the precision of EZ location identification for individual regions. It compares the identification of the epileptogenic general region from ChatGPT or epileptologists against the ground truth. The RAR values range from 0% to 100%. When the response from the ChatGPT or epileptologist perfectly matches the ground truth, the RAR is 100%; otherwise, less than 100%.
For a general region x – which is one of the following regions: frontal lobe, parietal lobe, temporal lobe, occipital lobe, cingulate cortex, and insular cortex – the RARx is calculated as:
 with
with


where N represents the number of semiology-EZ pairs; G and R represent the sets of EZ locations from the ground truth and the responses from ChatGPT or epileptologists, respectively.  is an indicator function that scores 1 if the general region x is included in the ground truth G of a semiology-EZ pairing, otherwise 0.
is an indicator function that scores 1 if the general region x is included in the ground truth G of a semiology-EZ pairing, otherwise 0.  is a similar indicator function that scores 1 if region X is correctly identified in the intersection of the response R and the ground truth G for a semiology-EZ pairing, otherwise
is a similar indicator function that scores 1 if region X is correctly identified in the intersection of the response R and the ground truth G for a semiology-EZ pairing, otherwise  quantifies the aggregate presence of the general region x within the ground truth in N semiology-EZ pairs.
quantifies the aggregate presence of the general region x within the ground truth in N semiology-EZ pairs.  quantifies the intersection of the response R and the ground truth G for a semiology-EZ pairing, in N semiology-EZ pairs, regardless of whether a single region or multiple regions for each pair.
quantifies the intersection of the response R and the ground truth G for a semiology-EZ pairing, in N semiology-EZ pairs, regardless of whether a single region or multiple regions for each pair.
Results
⍰ Evaluation of responses from ChatGPT
In this study, the performance of ChatGPT-3.5 and ChatGPT-4.0 was evaluated in interpreting seizure semiology from a database of 865 records. The ChatGPT responses generated with ZSP and FSP configurations were compared on the wordiness and reliability regarding EZ locations. The median length (with interquartile range [IQR]) of responses indicated that ZSP yielded significantly longer responses compared to FSP with ChatGPT-3.5 (ZSP: 180 [135∼230] words; FSP: 111 [83∼155] words) and ChatGPT-4.0 (ZSP: 246 [217∼277] words; FSP: 231 [201∼270] words).
Considering that ChatGPT’s identification encompasses both general and specific regions, our assessment was organized into two separate levels: one for general regions and another for specific regions.
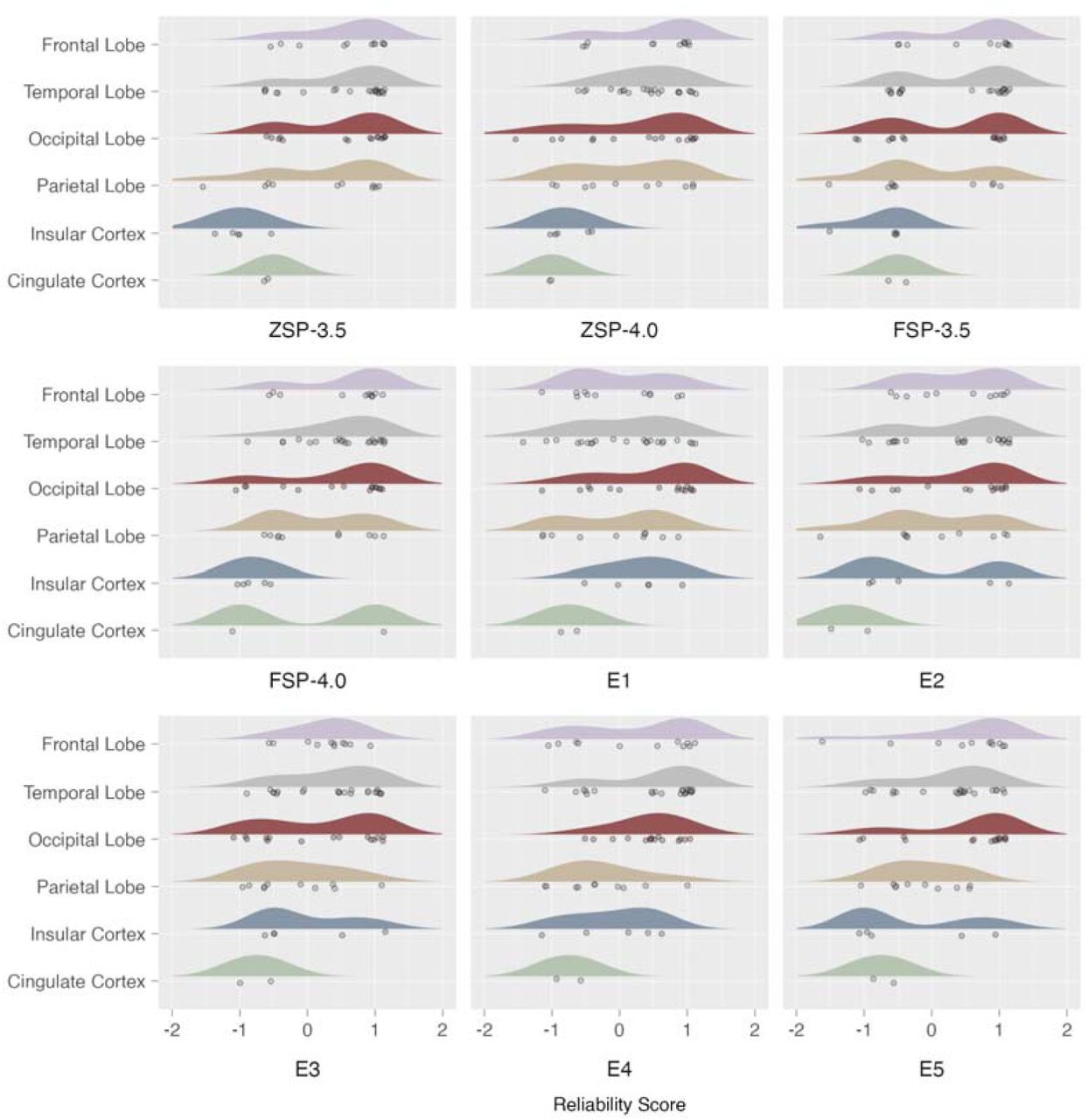
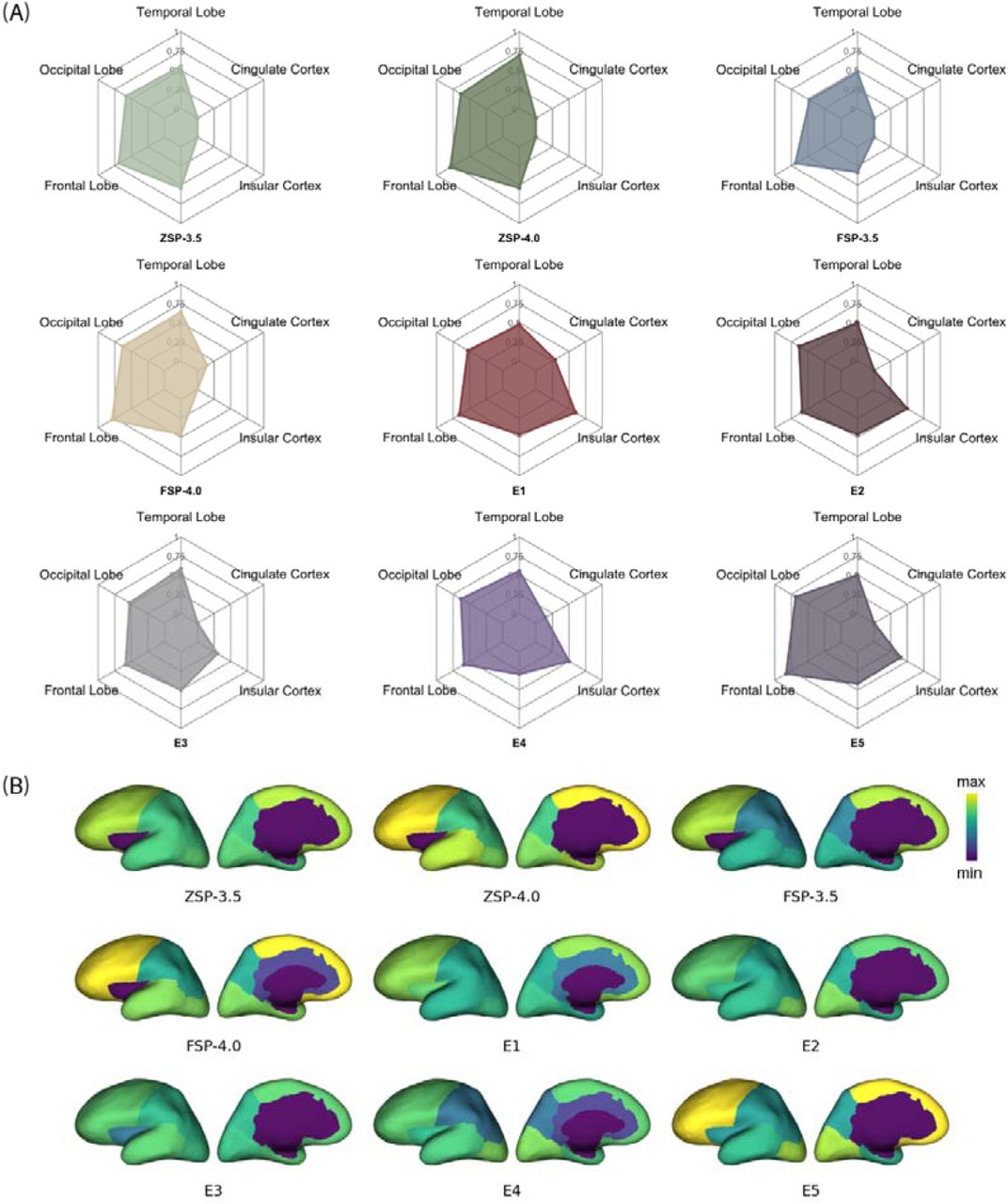
In the general region level, ChatGPT-4.0 using ZSP demonstrated the highest RS: 260 responses (30.06%) were scored as 1 (completely correct), 251 responses (29.02%) were scored as 0.5 to 0.75 (partially correct), and 354 responses (40.92%) were scored less than 0.5 (partially or completely wrong). For the six general regions, the RAR was 89.28% for the frontal lobe, 71.39% for the temporal lobe, 46.24% for the occipital lobe, 31.01% for the parietal lobe, 8.51% for the insular cortex, and 0% for the cingulate cortex (Figure 2). These results highlight ChatGPT’s proficiency in reliably interpreting seizure semiology for frontal and temporal lobe epilepsies, while underscoring its limitations in accurately interpreting semiology associated with the parietal, occipital, cingulate, and insular epilepsies, which are relatively less common.

(A), Reliability scores of responses generated by ChatGPT-3.5 with zero-shot prompting (ZSP-3.5), ChatGPT-4.0 with zero-shot prompting (ZSP-4.0), ChatGPT-3.5 with few-shot prompting (FSP-3.5), and ChatGPT-4.0 with few-shot prompting (FSP-4.0). (B) and (C), regional accuracy rate of responses generated by ChatGPT with different prompt configurations (ZSP-3.5, ZSP-4.0, FSP-3.5, FSP-4.0).
At the specific region level, our available collation was limited to 347 records, as some articles merely delineate the general region without detailing specific regions of EZs for individual epilepsy cases. Based on these records, ChatGPT-3.5 with FSP demonstrated the highest RS with 63 responses (18.16%) scored as 1 (completely correct), 25 responses (7.2%) scored as 0.5 to 0.75 (partially correct), and 259 responses (74.64%) scored less than 0.5 (partially or completely wrong). The median [IQR] reliability scores were as follows: ChatGPT-3.5 with ZSP (–0.12 [-0.5∼0.11]), ChatGPT-4.0 with ZSP (–0.25 [-1∼0.26]), ChatGPT-3.5 with FSP (–0.1 [-0.5∼0.5]), ChatGPT-4.0 with FSP (–0.11 [-0.5∼0.5]).
⍰ Comparison of responses from ChatGPT and epileptologists
An online survey comprising 100 questions regarding EZ locations and corresponding seizure semiologies was formed to collect responses from eight Board-certified epileptologists. Out of these, five participants completed the survey entirely while three others completed it partially. Consequently, the analysis was confined to the fully completed responses of five epileptologists (E1, E2, E3, E4, E5). After excluding ambiguous characterization of EZs from the literature, the analysis was further narrowed down to 90 questions for the comparison analysis between ChatGPT and epileptologists.
In the general region level, regarding the evaluation of seizure semiology interpretation, epileptologist E4 demonstrated the highest RS: 25 responses (27.78%) were scored as 1 (completely correct), 23 responses (25.56%) were scored as 0.5 to 0.75 (partially correct), and 52 responses (57.78%) were scored less than 0.5 (basically or completely wrong) (Figure 3). For six general regions, the RAR was 58.62% for the frontal lobe, 55.56% for the temporal lobe, 63.16% for the occipital lobe, 29.17% for the parietal lobe, 50% for the insular cortex, and 14.29% for the cingulate cortex (Figure 4). Notably, ChatGPT demonstrated comparable or superior accuracy to that of epileptologists in interpreting seizure semiology related to the frontal, temporal, parietal, and occipital lobes. However, epileptologists showed significantly better performance in interpreting seizure semiology associated with the cingulate cortex and insular cortex, where EZs are less commonly identified (Figure 4).

Reliability scores of responses generated by ChatGPT with different prompt configurations (ZSP-3.5, ZSP-4.0, FSP-3.5, FSP-4.0) and epileptologists (E1, E2, E3, E4, E5).

At the specific region level, our available collation was limited to 43 records, as some articles merely delineate the general region without detailing specific regions of EZs for individual epilepsy cases. Given most of the answers to the specific regions are not provided by epileptologists E3 and E4, only responses from E1, E2, and E5 were analyzed for the specific EZ locations. Compared to ChatGPT, Epileptologist E5 exhibited the highest RS: 3 responses (6.98%) were scored as 1 (completely correct), 8 responses (18.6%) were scored as 0.5 to 0.75 (partially correct), and 32 responses (74.42%) were scored less than 0.5 (basically or completely wrong). The median [IQR] reliability scores were as follows: ChatGPT-3.5 with ZSP (–0.25 [-0.5∼0]), ChatGPT-4.0 with ZSP (–0.5 [-1∼0.21]), ChatGPT-3.5 with FSP (–0.25 [-0.5∼0]), ChatGPT-4.0 with FSP (–0.12 [-0.62∼0.5]), E1 (–0.25 [-0.75∼0.5]), E2 (0 [-0.5∼0.33]), and E5 (0 [-0.5∼0.38]).
Discussion
We conducted the first assessment evaluating the capability of ChatGPT in interpreting seizure semiology, alongside a comparative analysis with Board-certified epileptologists. A total of 865 seizure semiology and EZ location pairs were extracted from 189 articles to assess the responses generated by ChatGPT. A panel of epileptologists was invited to complete an online survey comprising 100 questions to collect their insights on EZ locations based on reported seizure semiology.
The analysis of reliability scores revealed that ChatGPT-4.0 significantly outperformed its predecessor, ChatGPT-3.5. However, the influence of different prompting techniques on the responses from both versions was minimal. ChatGPT-4.0 displayed a tendency to suggest a broader array of potential EZ locations, which, despite increasing the scope of analysis, occasionally led to the inclusion of incorrect locations, thereby slightly reducing its reliability score compared to ChatGPT-3.5. Notably, ChatGPT demonstrated comparable, and in some cases superior performance to that of epileptologists, particularly in identifying EZ locations that are more commonly found. The responses from ChatGPT were comprehensive and surprisingly valuable for reference, with well-founded reasoning regarding EZ locations (Table 1). Nonetheless, our accuracy analysis highlighted that for seizure semiology indicating less common EZ locations, such as the cingulate and insular cortex, interpretations from epileptologists remained more precise and reliable. The discrepancy in epilepsy manifestations in less common regions can be attributed to an insufficient data volume, which hampers the training of language models to achieve predictive reliability comparable to that of epileptologists.
Our results align with findings from previous studies assessing ChatGPT’s performance in epilepsy-related inquiries [20][21]. Specifically, Kim et al. assessed the reliability of responses of ChatGPT to 57 commonly asked epilepsy questions, and all responses were reviewed by two epileptologists. The results suggested that these responses were either of “sufficient educational value” or “correct but inadequate” for almost all questions [20]. Wu et al. evaluated the performance of ChatGPT to a total of 378 questions related to epilepsy and 5 questions related to emotional support. Statistics indicated that ChatGPT provided “correct and comprehensive” answers to 68.4% of the questions. However, when answering “prognostic questions”, ChatGPT performed poorly with only 46.8% of answers rated comprehensive [21].
Limitations
Although this study offered an important reference on the ability of ChatGPT to deliver reliable insights into interpreting seizure semiology, there are still several limitations. First, the number of articles involved in compiling the semiology-EZ database can be further expanded and updated. These semiology records were mainly related to seizures originating from the frontal lobe and temporal lobe, while for the remaining regions, especially the cingulate cortex and insular cortex, the collected semiology descriptions were inadequate and incomplete. Future studies could include more semiology corresponding to regions where EZs are rarely found. Second, the small number of human epileptologists limited the power of comparative analysis between ChatGPT and human responses.
Furthermore, ChatGPT was trained on the Common Crawl corpus, which encompasses a wide array of general knowledge from books, articles, web pages, etc., limiting the ability of ChatGPT to generate responses with a specific focus on the medical domain. Future research could explore the application of LLMs fine-tuned on epilepsy-specific corpora for improved seizure semiology interpretation.
Conclusions
In this cross-sectional study of seizure semiology interpretation, ChatGPT-generated responses outperformed or matched responses from epileptologists in regions where EZs are commonly located, such as the frontal lobe and the temporal lobe. However, epileptologists provided more accurate responses in regions where EZs are rarely located, such as the insula and the cingulate cortex. Overall, our results demonstrate that ChatGPT might serve as a valuable tool to assist in the preoperative assessment for epilepsy surgery. However, it must be acknowledged that the information provided by ChatGPT may not always be backed by reliable sources, posing a challenge to the verification of ChatGPT-generated responses.
Furthermore, medical professionals, including epileptologists and epilepsy surgeons, must fully recognize the limitations of ChatGPT and exercise caution when utilizing its responses. This study serves as an important reference for employing ChatGPT in seizure semiology interpretation while underscoring its present constraints.
Data Availability
All data produced in the present study are available upon reasonable request to the authors after the completion of the project.
Competing interest declaration
“All authors have completed the Unified Competing Interest form at www.icmje.org/coi_disclosure.pdf.” Dr. Aboud has served on the advisory board for Servier and is supported in part by the UC Davis Paul Calabresi Career Development Award for Clinical Oncology as funded by the National Cancer Institute/National Institutes of Health through grant #2K12CA138464-11. Dr. Rosenow has received research support from the Federal State of Hesse, specifically at the Center for Personalized Translational Epilepsy Research from 2018 to 2022. Dr. Rosenow has received research support from Chaja-Foundation Frankfurt, focusing on establishing and evaluating the ketogenic diet in institution. Dr. Rosenow received research support from Reiss-Foundation Frankfurt, mainly for the research on the ketogenic diet in GLUT1-DS. Dr. Rosenow received research support from German Ministry of Education, focusing on the ERAPerMed Raise-Genic.
Author Contributions
Jiao (data curation, formal analysis, software, Visualization, Writing – Original Draft), Luo (data curation, formal analysis, software, Visualization, Writing – Original Draft), Fotedar (Conceptualization, Methodology, Validation, Investigation, Writing – Review & Editing), Karakis (Validation, Investigation, Writing – Review & Editing), Aboud (Validation, Investigation, Writing – Review & Editing), Rao (Validation, Investigation, Writing – Review & Editing), Asmar (Validation, Investigation, Writing – Review & Editing), Xian (Statistical Analysis, Validation, Writing – Review & Editing), Wen(Statistical Analysis, Validation, Writing – Review & Editing), Lin (Resources, Validation, Writing – Review & Editing), Rosenow (Validation, Investigation, Writing – Review & Editing), Sun (Conceptualization, Methodology, Validation, Investigation, Writing – Review & Editing), Liu (Conceptualization, Supervision, Formal analysis, Funding acquisition, Resources, Methodology, Writing – Original Draft)
Acknowledgments
The authors are grateful to the epileptologists who completed the survey.
Footnotes
Updated two brain plot figures.




{kind=link}
{kind=link}
{kind=link}
{kind=link}