
ABSTRACT
Cardiovascular disease has been established as the world’s number one killer, causing over 20 million deaths per year. This fact, along with the growing awareness of the impact of exposomic risk factors on cardiovascular diseases, has led the scientific community to leverage machine learning strategies as a complementary approach to traditional statistical epidemiological studies that are challenged by the highly heterogeneous and dynamic nature of exposomics data. The principal objective served by this work is to identify key pertinent literature and provide an overview of the breadth of research in the field of machine learning applications on exposomics data with a focus on cardiovascular diseases. Secondarily, we aimed at identifying common limitations and meaningful directives to be addressed in the future. Overall, this work shows that, despite the fact that machine learning on exposomics data is under-researched compared to its application on other members of the -omics family, it is increasingly adopted to investigate different aspects of cardiovascular diseases.
Introduction
Since the mid-20th century, cardiovascular diseases (CVDs) have emerged as the leading cause of death globally. Focusing on Europe, CVDs have been reported to account for 3.9 million deaths annually and over 1.8 million deaths within the European Union (EU) [1]. In addition to this significant epidemiological burden, CVDs are estimated to impose a financial cost of 210 billion euros per year on the EU economy [1]. They represent a large group of diseases attributed to a complex interplay between intrinsic risk factors, such as genetic predisposition, biological sex, age and lifetime exposure to environmental and behavioral risk factors which are considered at least partially modifiable [2]. Environmental exposures to ambient and indoor air pollution, noise, extreme temperatures, second-hand smoke, and chemicals, among other factors, have been recognized by the European Environment Agency as significant contributors to the high burden of CVD. It is estimated that over 18% of CVD-related deaths in Europe are attributable to environmental risks [2]. In recent years, there has been growing recognition of the importance of modifiable factors as a whole in efforts to alleviate the burden of disease [3].
While preventive interventions targeting traditional risk factors (e.g. blood pressure and cholesterol management) have aided in reducing CVD incidents, it remains a major problem at a global scale highlighting the need for new approaches. Unlike one’s DNA, which remains unchangeable, there are primary modifiable contributors to CVD that are amenable to prevention and policy initiatives aimed at promoting cardiovascular health. The fact that environmental CV risks factors are inherently preventable leads to the actionable conclusion that reducing them is a key-step to alleviating the burden of cardiovascular disease in Europe. In this context, investigations are increasingly directed towards non-traditional risk factors that are present in the built, natural, and sociο-economic environments comprising the “Exposome” [3], [4].
Exposome, the youngest member of the widely acknowledged -ome family, was first coined in 2005 by Dr. Christopher Wild, then-director of the International Agency for Research on Cancer (IARC), to complement the human genome and address the limitations of genetic research in explaining chronic disease etiology [5]. Aiming to fill this critical knowledge gap, the exposome was conceptualized as a systematic approach to measuring the entirety of environmental exposures encountered by an individual from conception onwards, including chemical, physical, biological, and lifestyle factors. In 2014, Gary Miller and Dean Jones expanded the exposome so as to emphasize diet, behavior, and endogenous processes, particularly focusing on biological responses to these exposures [6]. According to them, the exposome captures the essence of “nurture” in one of the oldest philosophical discussions of “nature” vs “nurture”, representing the summation and integration of external forces acting upon our genome throughout our lifespan. This includes factors such as diet, living environment, air quality, social interactions, lifestyle choices like smoking and exercise, and inherent metabolic and cellular activities. Measuring a quantity for the exposome serves as a biological index of our “nurture”, contextualizing the impact of specific exposures on health. This expansion and refinement of exposomics led to the inclusion of metabolomics, rather than solely exposure-focused approaches, aiming to capture biological endpoints accompanied with substantial changes [7]. By exploring all these factors that constitute the exposome, researchers aim to understand and pinpoint modifiable risk factors and devise targeted interventions by means such as active personal measures, behavioral strategies, novel policies, urban landscape reforms etc. in an effort to promote health and prevent disease across lifespan.
Along the lines of Genome-Wide Association studies (GWAS) and the identification of genetic basis of many complex traits and diseases [8], there have also been efforts to identify the “environmental” risk factors in the so-called ‘Environment-Wide association studies’ [9]. Finally, the wider term “Exposome-Wide Association Study” (ExWAS) has been proposed as a standardization term and a method designed to systematically investigate the connections between phenotypes and various exposures beyond the classic understanding of environmental factors, in line with the definition of Exposome [6]. This approach facilitates the identification of significant correlations while addressing the challenge of multiple comparisons, aimed at finding the exposomic basis of a disease or trait [10]. Examples focused on CVD can be found in literature [11].
There are different types of environmental risk factors reported in literature. First, chemical pollution, which spans air, soil, water and occupational pollution and is currently acknowledged as the most significant environmental cause of disease and premature death in the world [12]. Air pollution’s main health risks come from particulate matter which is well known to be linked with CVDs [13] while the water pollution hazards stem from unsafe sources. Soil pollution’s health impacts can be attributed mainly to heavy metals, deforestation, over-fertilization, and pesticides, with nano and micro plastics emerging as a threat. Although lead toxicity primarily results from water and soil pollution, it warrants separate consideration due to its widespread environmental presence. There’s a close link between water and soil pollution, as polluted soils can contaminate surface and groundwater. Heavy metals and metalloids are particularly concerning for their contribution to cardiovascular issues through oxidative stress and inflammation [14]. Chemical pollutants and particularly ambient air pollution, have garnered significant attention from research organizations assessing their impacts [15], [16]. These pollutants were also considered in the Global Burden of Disease study [17], [18].
Second, non-chemical pollution such as transportation noise, light pollution and lack of green spaces have been also shown to have substantial impact on CVD [4]. On the one hand, as urban areas expand and the demand for transportation increases, noise pollution is expected to rise. Research has demonstrated a connection between noise pollution and heightened cardiovascular risk, driven by mechanisms such as stress, sleep disruption, and increased inflammation. Furthermore, studies have shown an association between noise pollution and elevated risks of arterial hypertension, dyslipidemia, obesity, and type II diabetes mellitus. Thus, noise pollution not only directly impacts the CV system but also indirectly elevates the risk of developing traditional cardiovascular (CV) risk factors [19]. On the other end, it is known that nocturnal light pollution is associated with abnormal changes in circadian rhythms, which in turn may be linked to an increased risk of CVD [20], [21], increased blood pressure and risk of hospitalization for CVD [22].22 While there is extensive and robust evidence linking noise pollution to an increased risk of CVD, the role of nocturnal light pollution in CV pathology is less studied. In order to validate and substantiate this association, further research is needed to figure out potential thresholds of ‘safe’ or ‘acceptable’ artificial light levels [23]. Finally, latest meta analyses have highlighted strong evidence on the link of green spaces and cardiovascular health [24]. For a comprehensive review on the epidemiology and pathophysiology of environmental stressors with a focus on CVDs, the interested reader may refer to pertinent literature [3], [4], [14], [25].
Apart from the classic environmental risk factors such as pollution, the exposome encompasses a wide range of lifestyle and socioeconomic factors. There is growing evidence that the CVD is characterized by socioeconomic inequalities [26], [27], [28]. These inequalities that are most frequently assessed in terms of income, occupation and education seem to be closely related with dietary habits and harmful lifestyle choices such as smoking and alcohol consumption [26]. The effect of lifestyle intervention aiming at nutrition and physical activity has shown to benefit cardiometabolic risk factors such as Body Mass Index (BMI), triglycerides and Low-Density Lipoproteins (LDL) of individuals at risk [29]. The overwhelming evidence of the impact of lifestyle on traditional cardiometabolic biomarkers has led to the emergence of the framework of “lifestyle medicine” which leverages lifestyle interventions to maintain cardiovascular health [30]. Most often these interventions focus primarily on diet, physical activity, perceived stress and anxiety and also mitigation of harmful habits such as tobacco use and alcohol consumption.
While traditional epidemiology relying on well-established study designs is a valuable tool to investigate the relationship between environmental exposures and health outcomes, new challenges have been posed by the heterogeneous and dynamic nature of exposomics data. The exposome concept aims at considering many environmental stressors simultaneously, as opposed to the one-by-one approach typically used in epidemiological research. This necessity along with the large number of exposures pose challenges such as increased complexity, high dimensionality, high correlation between variables and the need to understand both the combined effects and the causal structure between exposure risk factors and health outcomes. The Machine Learning (ML) toolbox, including Deep Learning (DL) techniques, is particularly well-suited to address these challenges [31]. By leveraging this set of tools, researchers can efficiently reduce data dimensionality and identify complex patterns and interactions; integrate diverse data types; enhance causal inference capabilities and uncover intricate relationships between exposomic factors and health outcomes; provide deeper insights into how combined environmental and behavioral factors influence CVD.
ML techniques, including DL, have been gaining popularity for quite a few years now in the analysis and integration of diverse kinds of -omics data (e.g. genomics, proteomics, metabolomics) especially within the context of precision medicine [32], [33]. However, applications on exposomics are still in early stages. This is partly because the field itself is relatively new (i.e. the term only coined in 2005) but also due to the very nature and scale of the exposome which covers all exposures from conception to death. Thus, data is expected to exhibit significant heterogeneity (e.g. lifestyle factors, socioeconomic variables, biological responses etc.) as well as spatial and temporal variability, requiring integration from multiple sources and technologies. Due to these challenges, researchers proposed a roadmap for the use of federated technologies to accelerate research in the field [34]. Finally, DL, with its capacity for large-scale processing of complex and disparate multi-modal datasets, holds promise for advancing the understanding of the implications of the exposomics in the disease [35].
To date, and to the best of the authors’ knowledge, the only review paper on the application of machine learning techniques on exposomics data for CVD-related investigations exclusively includes social determinants of health [36]. The principal objective served by this work is to address this literature gap, by identifying key studies and providing an overview of the breadth of research in the field of machine learning applications on exposomics data with a focus on cardiovascular diseases. Common limitations have also been identified and meaningful directives to be addressed in the future have been suggested.
The rest of the article is structured as follows: we start with the Methods section reporting the adopted literature search strategy and outlining the three research questions with respect to which the presented analysis has been conducted and then we proceed with the Results section providing the reader with an overview of the relevant literature in the context of the three main axes of our work. Finally and as a result of this review, we summarize findings, discuss remarkable insights, and also identify and address the limitations of this study.
Methods
Search strategy
An extensive search of PubMed, IEEE Xplore and ACM Digital Library has been conducted in order to thoroughly identify articles on machine learning applications exploring potential associations of exposomics factors with CVD-related outcomes and published in English. Relevant key terms have been extracted in line with the main aspects of the exposome recognized by the European Human Exposome Network [37]. The latter identifies environmental, lifestyle-related, and socio-economic factors as the key exposures constituting the exposome. These key factors have been adopted as the keywords for this review, searched in the titles and abstracts of published studies. Specifically, the body of work reported herein has been obtained with the following keywords:
‘environment’ AND ‘machine learning’ AND ‘cardiovascular diseases’
‘socio-economic’ AND ‘machine learning’ AND ‘cardiovascular diseases’
‘lifestyle’ AND ‘machine learning’ AND ‘cardiovascular diseases’
Database searches have been supplemented with studies identified through manual searching. This review has been conducted using a systematic approach consistent with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement [38]. No temporal bounds have been imposed on the publication dates.
Study Exclusion Criteria
The following exclusion criteria have been applied in order to ensure that this review maintains focus and relevance to the desired scope:
Non-English articles,
Non-peer reviewed items (e.g. gray literature such as pre-prints, technical reports, web-based guidelines etc.),
Items for which the full text was not accessible (e.g. articles presented at conferences as abstracts),
Articles exclusively focused on traditional statistical methods,
Articles not exploiting exposomics data,
Review articles,
Duplicate articles.
Research questions
The analysis to be presented revolves around the following research questions.
RQ1. Which are the main identified categories of studies with respect to their objective?
RQ2. Which machine learning algorithms have been applied for investigating exposomics impact on CVDs and which seem to be ranking among the top performers?
RQ3. Which exposomic factors have been investigated and which have been identified as potentially good predictors?
The aspect investigated in the context of the first research question (RQ1) focuses on classifying the selected studies into two main categories based on the selected target variables combined with the context of potential application of the developed system. The second research question (RQ2) explores the ML algorithms preferred by the research community in an attempt to rank specific categories of algorithms with respect to their popularity in pertinent literature. Finally, the third research question (RQ3) aspires to shed light on specific categories of promising predictors and hopefully to identify new directions of exposomics variables investigations.
Results
A general overview
Firstly, an overview of pertinent literature is provided, highlighting the temporal distribution of publications, the geographical distribution of utilized datasets, and the specific machine learning tasks addressed.
The timeline of publications identified by using the specified search criteria, as displayed in the barplot below (Fig.1), reveals a pronounced increase of relevant studies from 2021 onwards.

Time evolution of publications leveraging ML techniques to exploit exposomic datasets for CVD-related investigations a. Year of publication (x-axis) and number of identified studies per year (y-axis), b. Time of publication (‘earlier than 2021’ and ‘from 2021 onwards’)
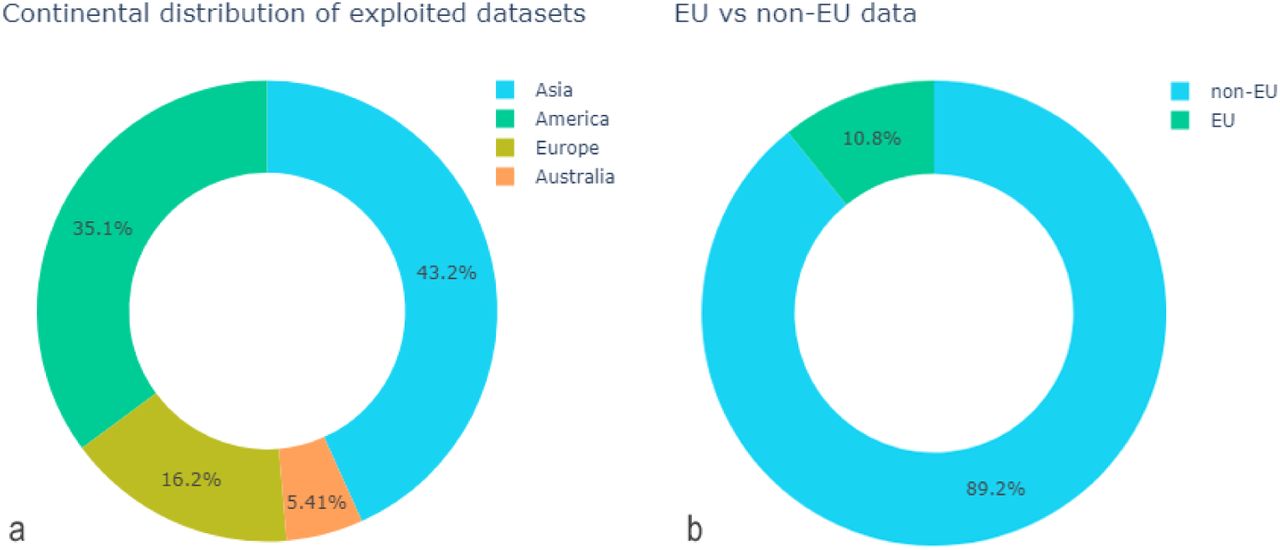
Concerning the spatial distribution, the majority of identified studies reporting the origin of their datasets have been based on datasets collected within US or Asian territory (Fig. 2).

a. Continental distribution of exploited datasets, b. Data of EU vs non-EU origin.
Lastly, regarding the framing of the ML problems addressed in the identified literature, an important observation is the pronounced, almost exclusive adoption of a supervised context. The most widely adopted problem framing is that of classification tasks, followed by regression tasks (Fig. 3).

A Venn diagram of ML tasks categories encountered in literature focusing on exploring CVDs
Research questions
Proceeding with the conducted analysis, we elaborate on identified categories of studies across pertinent literature with respect to the aspects corresponding to the research questions:
RQ1. Which are the main identified categories of studies with respect to their objective?
Two main categories of studies have been identified based on the selected target variable combined with the application context of the system under development. The first category aims at forecasting crucial cardiovascular outcomes or associated risk level and often focuses on identifying key determinants of the target outcomes and ranking them in terms of feature importance. The latter category opts for resource-related target variables, typically reflecting healthcare demand such as number of CVD-induced hospital admissions or identification of peak demand days of hospitalizations. This kind of approach usually aspires to build and eventually deploy an early-warning system for medical resource allocation and management.
Starting from the articles focusing on the prediction/ forecast of cardiovascular outcomes, a general observation would be that most of the approaches either forecast cardiovascular disease incidence/ prevalence or investigate cardiovascular cause-specific mortality. Less often, disease risk stratification or disease severity prediction is conducted. Guimbaud et al. [39] have built early-life environmental risk scores (ERS) to assess the cumulative impact of environmental exposures on diverse health outcomes, including cardiometabolic health. The authors aimed at informing practitioners about actionable factors towards prevention measures in healthcare for high-risk children. In Chen et al. the association between machine vision–based built environment and prevalence of cardiometabolic disease at the neighborhood level has been investigated [35]. The authors aspired to identify at-risk neighborhoods, thereby contributing to a more informed and targeted public health strategy for mitigating CV risks associated with specific environmental factors. In Hossain et al. the authors focused on identifying crucial factors in predicting CVD risk [40]. As the authors claimed, the eventual goal of this work has been to enhance clinical practice by providing doctors with a new instrument to determine a patient’s CVD prognosis. The primary objective in the study by Nissa et al. has been to identify individuals at risk of developing CVDs and eventually enable healthcare professionals to foster proactive healthcare measures [41]. County phenotypes associated with premature CV mortality have been identified in Dong et al. and their geographic distributions have been investigated using machine learning approaches as well as geographic information systems [42]. The authors conclude that interventions to reduce premature cardiovascular mortality should be targeted to geographic areas with high-risk phenotypes of premature cardiovascular mortality. Leirião et al. have generated forecasts of cardiorespiratory mortality in the elderly aiming at providing decision-makers with a powerful tool for the evaluation of environmental public health-related policies [43]. Martin-Morales et al. predicted CVD mortality with a focus on identifying associated risk factors from a pool of significant nutritional variables [44]. Lee et al. have generated forecasts of mortality from cardiovascular, respiratory, and non-accidental diseases [45]. Proceeding with the studies attempting to predict cardiovascular incidents, Marien et al. have forecasted the number of daily incidents of myocardial infarctions based on case-only data and claimed that the suggested ML approach provides a promising basis to model future MI under changing environmental conditions, as projected by scenarios for climate and other environmental changes [46]. Bhakta et al. have demonstrated the potential of ML models for the early detection of CVD, ultimately enabling medical professionals to implement timely interventions and achieve improved patient outcomes [47]. Liu et al. developed a detection system of stroke survivors with a focus on identifying key factors associated with stroke records [48]. Monaco et al. have evaluated the severity of CVD incidents and identified clinical features mostly associated with CVD risk [49]. Yao et al. have exploited multi-source spatio-temporal data to predict MI severity and to spatially analyze associated risk factors [50]. The authors also proposed urban planning-related directives aiming at reducing the risk and mortality. Atehortua et al. have attempted to demonstrate the potential of exposome-based machine learning as a risk assessment tool by developing an ML model for CVD risk prediction performing comparably to a more integrative model requiring clinical information [51]. Alaa et al. leveraged an automated ML framework applied on non-traditional variables to increase the accuracy of CVD risk predictions in asymptomatic individuals compared to a well-established risk prediction algorithm based on conventional CVD risk factors (Framingham score) and other baseline models [52]. Ren et al. have identified maternal exposure to PM10 as the primary risk factor for congenital heart defects based on two machine learning models [53]. Park et al. [54] developed several updated Environmental Risk Score (ERS) measures constructed to predict GGT, an indicator of oxidative stress, which has been exploited as a summary measure to examine the risk of exposure to multi-pollutants. Subsequently, associations between ERS and cardiovascular endpoints (blood pressure, hypertension and total and cardiovascular disease (CVD) mortality) have been evaluated. Lee et al. [11] performed an exposome-wide association study (ExWAS) on a selection of cardiovascular outcomes (cardiac arrhythmia, congestive heart failure, coronary artery disease, heart attack, stroke, and a combined atherogenic-related outcome comprising angina, angioplasty, atherosclerosis, coronary artery disease, heart attack, and stroke) using statistics and machine learning and claim to have identified novel risk factors for CVD. Li et al. [55] have identified and ranked prominent factors associated with CVD in a supervised context using CVD diagnoses. In Hsiao et al. [56] environmental and outpatient records have been utilized for detecting the incidence of four specific categories of cardiovascular diseases. The authors claim that the proposed model can be further developed as a tool for personalized healthcare management. Lastly, Dominici et al. [57] have explored the association between short-term exposure to airborne particles and daily hospitalizations with respiratory or CV etiology on a national scale highlighting this ongoing threat to the health of the elderly population.
Proceeding with the category that focuses on predicting/ forecasting medical resources-related variables, the identified attempts aspiring the development of a healthcare resources management tool will be reported. Sun et al. [58] exploited ML techniques to identify the determinants of population-based CVD outcomes, such as the prevalence of CVD and its related health care costs. The authors focused on county level since counties have departments of health that are equipped with public health personnel and have the capacity to report and monitor real-world cardiovascular prevalence and costs. The findings have important policy implications for controlling the health care costs from CVD. Lin et al. [59] selected emergency department visits with CVD-related etiology as a target variable, emphasizing the critical need for ML-enabled decision support in clinical manpower and resource management. By predicting the incidence of emergent CVD events, they aimed at providing a basis for the development of a management system to address this need. Sajid et al. [60] demonstrated satisfactory performance in predicting CVD incidence with the use of nonclinical features readily available in any healthcare system. The authors aimed at reducing the potential burden of disease on already overburdened health systems in low-middle-income countries, which have limited access to health facilities by enabling the implementation of preventive strategies. Chen et al.[61] focused on providing an early-warning system upon potentially excessive numbers of hemorrhagic stroke admissions to medical institutions by forecasting the demand for hemorrhagic stroke healthcare services. Qiu et al. [62] aimed at the implementation of a decision-making tool for medical resource management by forecasting peak demand days of CVD admissions. The authors have also identified the main weather-related and air quality-related contributors to prediction accuracy. Along similar lines, Lu and Qiu have focused on forecasting daily hospital admissions due to cerebrovascular disease and claimed that their approach offers practical value for hospital management teams in early warning and healthcare resource allocation [63]. In Usmani et al. [64] prediction of the trends of daily and monthly hospitalization has been conducted and along similar lines Jalili et al. [65] forecast the number of hospital admissions of CVD patients without however elaborating on a specific application context. Hu et al. [66] identified major determinants of stroke incidence at the neighborhood level potentially useful to prioritize and allocate resources to optimize community-level interventions for stroke prevention. Nghiem et al. [67] employed a selection of ML algorithms to predict high health-cost users among individuals with CVD, aiming to advance the application of preventive measures for population health improvement and ultimately the optimization of health services planning.
RQ2. Which machine learning algorithms have been applied for investigating exposomics impact on CVDs and which seem to be ranking among the top performers?
Tasks encountered in pertinent literature have been predominantly addressed within classification and regression contexts, with clustering being much less common. Overall, a broad palette of machine learning algorithms spanning from linear to non-linear and ensemble algorithms has been exploited. In many cases different categories of algorithms are employed and compared against each other. A detailed reporting of algorithms used in each study can be found in Table 1.
Research endeavors conducting comparative experiments among diverse algorithms account for nearly 70% of the identified studies. Starting from the most extensive investigations, a considerable part of the literature has explored a selection of linear, non-linear and ensemble methods [35], [40], [45], [46], [47], [48], [54], [60], [61], [62], [63], [67], [68]. The second most commonly encountered comparative approach involves utilizing non-linear and ensemble methods [41], [55], [68].Guimbaud et al. [39] have exploited linear and ensemble algorithms and Jalili et al. [65] have focused on linear and non-linear algorithms. Another comparative approach involves selecting more than one algorithm but within a specific family of models. In this context, Usmani et al. [64], have focused on the use of non-linear models while Hu et al. [66] have exclusively investigated ensemble models.
Proceeding with the remaining 30% of pertinent literature that does not conduct performance comparison whatsoever, a part of research opted for a non-linear algorithm [42], [43], [56], [57], while another part has focused on an ensemble algorithm of their selection [50], [51], [58], [59].
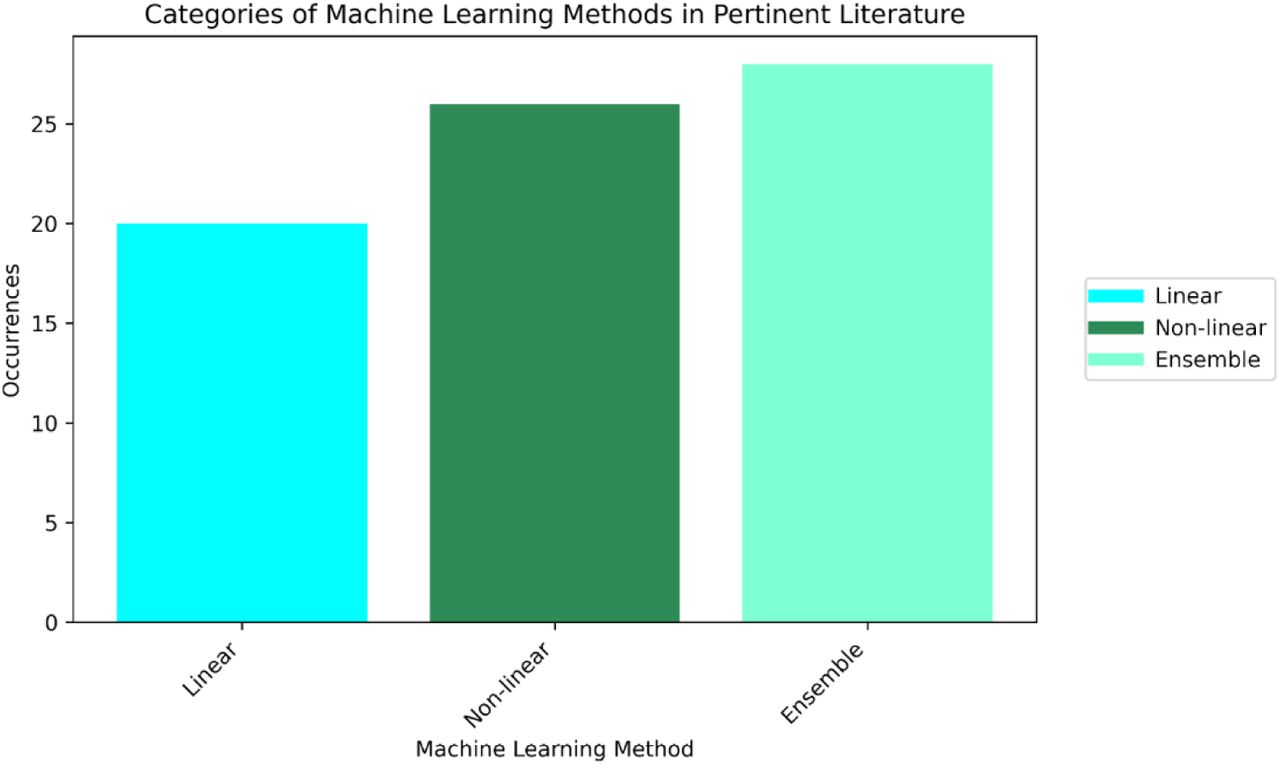
As it becomes obvious from Figure 4 ensemble algorithms are the most popular choice encountered in pertinent literature [35], [39], [40], [41], [44], [45], [46], [47], [48], [49], [50], [51], [52], [53], [54], [55], [58], [60], [61], [62], [63], [66], [67], [68], closely followed by non-linear algorithms [35], [41], [42], [43], [44], [45], [46], [47], [48], [49], [54], [59], [60], [62], [64], [65], [66], [67], [68], [69], [70], [71], [72]. The most widely adopted algorithms per category are Random Forest (RF) followed by Extreme Gradient Boosting (XGBoost) from the family of ensemble methods, Artificial Neural Networks (ANN) followed by Support Vector Machines (SVM) from the family of non-linear methods and linear/logistic regression as well as Lasso and Ridge variants from the linear algorithms.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Popularity of categories of ML algorithms as reflected by the number of corresponding occurrences in identified literature.
As Table 2 shows, the majority of comparative studies identify different representatives of the family of ensemble models as top-performing algorithms. Among these, the RF algorithm is the most frequently highlighted as the best performer, followed by XGBoost.
Linear methods exploited in pertinent literature are logistic regression [48], [62],SVM with linear kernel [61], Ridge regression [46],Elastic Net (EN) [63], although the latter in a meta-learning context.
From the popular family of ensemble models, quite a few works have reported the use of Random Forests (RF) [44], [46], [49], [50], [55], [61], [62], [68], followed by XGBoost [44], [51], [55], [61], Light Gradient Boosting Machine (LGBM)[44], Gradient Boosting (GB) [46], Random Ferns [55], Bayesian additive regression tree (BART) [54] and Stacking ensemble model [63].
Regarding non-linear methods, the use of artificial neural networks (ANN) and/or DL has been adopted in a considerable part of literature [35], [43], [46], [48], [49], [52], [56], [60], [62], [64], [65], [69].
RQ3. Which categories of exposomics factors have been investigated?
During the last years feature space investigations have broadened to include non-traditional CVD risk factors found in built, natural, and social environments, significantly contributing to the disease burden. The primary feature categories investigated in pertinent literature, whether individually or in combination, are environmental exposure factors, lifestyle και socio-economic status-related factors. The majority of identified articles exploit a combination of the aforementioned categories while the remaining works exclusively consider environmental factors. For a detailed reporting of the categories of exposomics features exploited in literature, see Table 3.
Environmental exposure is the most widely adopted category of exposome with the bulk of relevant literature exploring a broad palette of factors ranging from pollutants concentrations, average sound levels and meteorological parameters to biomarkers reflecting the extent of human exposure to heavy metals. Following closely are socio-economic factors, including factors such as current employment status, education level, income, lack of health insurance and food insecurity. Lastly, lifestyle-related factors, mostly reflecting dietary/sleep patterns along with various health habits, are also addressed in a significant portion of pertinent literature. Notably, environmental exposure is the only category often investigated individually while socioeconomic and lifestyle factors are typically studied in combination with other categories.
The most widely used environmental parameters include air pollutant concentrations and meteorological parameters [43], [45], [46], [53], [64], [69], [72]. Additionally but less often, parameters reflecting noise pollution [39], [51], green spaces [39], [46] and traffic proximity/volume [41], [66] are also included in the exploited feature space. In very few cases, variables reflecting daily or work exposures such as number of smokers at home [11], [39], [52], biohazardous materials [11] and heavy metals concentration based on human scalp hair analysis [49], blood or urine samples are exploited [68]. Lastly, a novel approach worth mentioning consists in the exploitation of machine vision-enabled assessment of the built environment to investigate potential associations with CVD-related variables [35]. Features extracted from Google Street View (GSV) images could also generate activation maps enabling the identification of high-risk neighborhoods.
Regarding socio-economic factors, a wide range of variables are used, primarily reflecting income, education levels, economic status and/or the subject’s occupation [39], [41], [47], [48], [51], [55], [67], [71]. Less often, extra variables such as lack of private health insurance, home ownership, housing type or severe housing cost burden are also considered [42], [44], [58], [70], [74].
In terms of lifestyle factors the focus is predominantly on health-related habits and adopted dietary, physical activity and sleep patterns/quality [11], [39], [41], [42], [44], [48], [51], [52], [55], [58], [67], [70], [71]. The most commonly considered health habit-related parameters is smoking status and/or alcohol consumption [11], [41], [44], [52], [55], [58], [67], [70], [71].
A considerable part of literature explores combinations of all three categories i.e. environmental, lifestyle, and socio-economic factors [11], [39], [41], [47], [51], [52], [74]. Additionally, socio-economic and lifestyle-related parameters are frequently combined to investigate associations of exposomics data with CVD-related variables [42], [44], [48], [55], [58], [67], [70], [71]. One last commonly encountered combination of categories consists in simultaneous investigation of socio-economic and environmental categories [35], [54], [60], [68].
The remaining part of identified articles exclusively considers environmental parameters, with a part of literature exploiting air quality-related features (mostly air pollutants concentrations) to forecast CVD-related variables [57], [64], [65], [69], and another part further expanding the feature space to include meteorological parameters as well [43], [45], [59], [63], [72]. Additionally, Marien et al. [46] further expanded the feature space with vegetation index. Ohashi et al. [73] is the only work exclusively based on meteorological parameters. Lastly, Monaco et al. [49] focused on heavy metals concentrations obtained by human scalp hair analysis tests to perform ML-enabled estimation of the severity of CVD.
Discussion
This scoping review aimed at presenting the state-of-the-art of ML applications on exposomic data, specifically focusing on CVDs. To this end, a substantial amount of current literature on the selected topic has been identified and analyzed with respect to diverse aspects i.e. study objectives, ML techniques employed and the categories of exposomic data exploited. Based on the insights from the previous sections, we will take a step further and identify key challenges and opportunities in ML-enabled exploitation of exposomic data for CVD-related variables.
As reflected by the timeline of identified publications the presented field is constantly expanding, particularly from 2021 onwards, with the expansion in exploitation of ML on exposomics targeting CVDs being predominantly driven by research in the US and Asia. However, the past 4 years the EU has shown an increasing interest in the Human Exposome Project initiating multimillion funding and thus recognizing potential to enhance public health [75].
Two main categories of studies have been identified based on the selected target variable and the application context of the system under development. The first category focuses on forecasting crucial cardiovascular outcomes or associated risk levels while the second targets resource-related variables typically reflecting healthcare demand such as the number of CVD-induced hospital admissions or the identification of peak demand days of hospitalizations. The former studies often aim to identify key determinants of the target outcomes and rank them in terms of feature importance and the latter usually aspires to build and deploy an early-warning system for medical resource allocation and management. Overall, the direction of research efforts falls within the scope of AI-driven health interventions aimed at effective risk stratification, public health surveillance, and health policy planning, all of which are described to contribute to health-related sustainable development goals [76].
Regarding ML techniques, it is noteworthy that ML tasks have been primarily framed in a supervised context, leaving ample space for the exploration of under-researched unsupervised techniques. Overall, a variety of machine learning algorithms spanning from linear to non-linear and ensemble algorithms has been exploited. In many cases different categories of algorithms are employed and compared against each other. Ensemble algorithms seem to be the most widely adopted approach and especially Random Forest and XGBoost which frequently rank as the most efficient solutions in comparative experiments. In the context of unsupervised learning and data clustering, more methods could be explored imposing minimal assumptions on data, trying to identify patterns, simplify large datasets and also enhance predictive modeling. An addition to the toolbox of the well-established linear clustering methods would be the case of non-linear clustering algorithms and specifically the so-called manifold learning, which aims to cluster data by identifying the intrinsic manifold upon which the data resides [77].
With respect to investigations related to the employed feature space, environmental exposure seems to be the most widely adopted category within the exposome. The bulk of relevant literature explores diverse factors ranging from pollutant concentrations, average sound levels and meteorological parameters to biomarkers reflecting the extent of human exposure to heavy metals. Following closely are socio-economic factors, encompassing aspects such as current employment status, education level, income, lack of health insurance and food insecurity. Lastly, lifestyle-related factors, mostly reflecting dietary/sleep patterns and quality along with various health habits such as drinking alcohol or smoking, are also addressed in a significant portion of the identified literature. Notably, environmental exposure is the only category often investigated individually while socioeconomic and lifestyle factors are typically studied in combination with other categories.
Important limitations have been reported across pertinent literature. Firstly, validity of exploited ground truth cannot be ascertained e.g. upon the use of diagnostic codes corresponding to hospitalizations or death certificates. Second, in case of self-reported data categories such as lifestyle data, subjectivity and recall bias cannot be avoided. Third, the bulk of conducted research only involved incidents that occurred in a single region. Another important limitation stems from the lack of temporal alignment between the collection of medical data concerning CVD incidents and the collection of exposome-related data. Most of the time, the data sources are not comprehensive and/ or standardized [36]. Fifth, several works report limited availability of data sources and finally, it is difficult to directly compare results from different studies since they are heterogeneous in terms of target, problem framing, study design and sample size and outcome assessment as reflected by the occasional lack of an external validation process but also by the diverse metric scores reported.
Extending the feature space to include non-traditional CVD risk factors spanning environmental, social and life-style domains has shown promising results in improving the performance of conventional models targeting CVD-related variables. In this sense, exploitation of exposome-related variables brings the researcher community one step closer to identifying major environmental, social and lifestyle determinants of CVDs. This additional knowledge at a personal level could form the basis for developing tools for personalized healthcare management. At a broader level (neighborhood, city, etc.), it could help prioritize and allocate healthcare resources. The latter would enhance healthcare workflow optimization and implementation of prevention and intervention measures to reduce CVD-induced healthcare costs.
At this point it should be stressed that a lack of consensus is observed within the research community regarding the distinct categories that constitute the exposome and the specific variables included in each of these categories. This leads to inconsistencies in terminology and classification, hindering comparability and standardization across studies. For instance, part of the research community might refer to ‘smoking status’ while another part may be making use of alternative terms such as ‘tobacco use’ etc. This holds for other terms as well, that may be used by researchers interchangeably, despite potentially referring to slightly different concepts. To enhance the reliability and comparability of exposome research, there is a need for standardization of terms and definitions used to describe predictor variables. Overall, standardized protocols for data collection and sharing should be developed.
Finally, there is a need to explore exposomics from a multi-disciplinary perspective. Since its scope is becoming clearer and clearer every day and more and more studies include exposomics in etiological research, actions are needed from multiple stakeholders to join forces for the unification of frameworks and the establishment of guidelines regarding an Exposome Study Design and even a comprehensive exposome database [78].
Conclusions
Even though ML techniques application on exposomics data with a focus on cardiovascular diseases is in its early stages compared to similar use cases that are based on other kinds of -omic data such as genomic data, there is a pronounced increase of pertinent publications during the last years. However, the vast majority of relevant studies has been based on data outside EU territory and specifically on data originating from the US and China. Regarding the ML framing of CVD-related problems, it is worth highlighting the nearly exclusive adoption of a supervised context across identified literature, irrespective of the cardiovascular outcome addressed, with just two works addressing a clustering task. As machine learning applications on exposomics data expand and reach a higher maturity level, it seems to hold promise for uncovering new insights into the environmental determinants of health but also for identifying valuable strategies for CVD prevention and healthcare resource allocation. Towards this aim, further research could focus on the more manageable and easily adjustable modifiable factors in contrast to those that are stiffer such as the socio-economic status and try to use the first as inhibitors to avert a “poor” exposome. Understanding the modifiability of different factors is crucial for public health strategies. Focusing on more modifiable factors can empower individuals to make positive changes in their lives, while also pursuing broader societal and policy changes to address the other less modifiable factors. Finally, there is need of standardization in terms of language so as to enable comparability between different studies as this is often hard even to categorize similar studies using the most prevalent keywords in the literature.
Statements and Declarations
The authors declare that they have no conflicts of interest regarding the publication of this manuscript.
Data Availability
This is a scoping review paper.
Footnotes
Corrections have been applied on citations and figure captions.
Abbreviations
- AdaBoost
- Adaptive Boosting
- AENET-I
- Adaptive Elastic-Net with main effects and pairwise interactions
- AI
- Artificial Intelligence
- ANN
- Artificial Neural Network
- APS
- Average Precision Score
- AUC-PR
- Area Under the Precision Recall Curve
- AUC-ROC
- Area Under the Receiver Operating Characteristic Curve
- AUC
- Area Under the Curve
- BAG
- Bagging (regressor or classifier based on context)
- BART
- Bayesian additive regression tree
- BKMR
- Bayesian Kernel Machine Regression
- BMI
- Body Mass Index
- CART
- Classification And Regression Tree
- CatBoost
- Categorical Boosting
- CNN
- Convolutional Neural Network
- CVD
- Cardio-Vascular Disease
- GB
- Gradient Boosting
- DL
- Deep Learning
- DT
- Decision Tree
- ELSTM
- Enhanced Long Short-Term Memory Model
- EN
- Elastic Net
- ERS
- Environmental Risk Score
- ExWAS
- Exposome-Wide Association Study
- FDR
- False Discovery Rate
- FNR
- False Negative Rate
- FPR
- False Positive Rate
- GGT
- Gamma-Glutamyl Transferase
- GSV
- Google Street View
- IDI
- Integrated Discrimination Improvement
- IF
- Isolation Forest
- KNN
- k-nearest neighbors
- KOBT
- Knockoff Boosted Trees
- LASSO
- Least Absolute Shrinkage and Selection Operator
- LDL
- Low-Density Lipoproteins
- LGBM
- Light Gradient Boosting Machine
- LMEM
- Linear Mixed Effects Model
- LOO-CV
- Leave-One-Out Cross-Validation
- LR
- Logistic Regression
- LSTM
- Long Short-Term Memory Model
- MAE
- Mean Absolute Error
- MAPE
- Mean Absolute Percentage Error
- MCC
- Matthew’s Correlation Coefficient
- MI
- Myocardial Infarction
- ML
- Machine Learning
- MLP
- Multi-Layer Perceptron
- MSE
- Mean-Squared Error
- MSPE
- Mean-Squared Prediction Error
- NB
- Naïve Bayes
- NPV
- Negative Predictive Value
- NRI
- Categorical Net Reclassification Improvement
- PCA
- Principal Component Analysis
- PRESS
- RF
- Random Forest
- RMSE
- Root Mean Squared Error
- SHAP
- SHapley Additive exPlanations
- SVC
- Support Vector Classification
- SVM
- Support Vector Machines
- XGBoost
- Extreme Gradient Boosting
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].↵
- [72].↵
- [73].↵
- [74].↵
- [75].↵
- [76].↵
- [77].↵
- [78].↵



