
Abstract
Self-reported nutrition intake (NI) data are prone to reporting bias that may induce bias in estimands in nutrition studies; however, they are used anyway due to high feasibility. We examined whether applying Goldberg cutoffs to remove “implausible” self-reported NI could reliably reduce bias compared to biomarkers for energy, sodium, potassium, and protein. Using IDATA data, significant bias in mean NI was removed with Goldberg cutoffs (120 among 303 participants excluded). Associations between NI and outcomes (weight, waist circumference, heart rate, systolic/diastolic blood pressure, and VO2 max) were estimated, but sample size was insufficient to evaluate bias reductions. We therefore simulated data based on IDATA. Significant bias in simulated associations using self-reported NI was reduced but not eliminated by Goldberg cutoffs in 14 of 24 nutrition-outcome pairs; bias was not reduced for remaining cases. 95% coverage probabilities were improved by applying Goldberg cutoffs in most cases but underperformed compared with biomarker data. Although Goldberg cutoffs may achieve bias elimination in estimating mean NI, bias in estimates of associations between NI and outcomes will not necessarily be reduced or eliminated after application of Goldberg cutoffs. Whether one uses Goldberg cutoffs should therefore be decided based on research purposes and not general rules.
Impact Statement Elimination of extreme reporters using Goldberg cutoffs does not always produce unbiased estimates of associations between nutrition intakes and health outcomes.
INTRODUCTION
Measuring nutrition intake plays a pivotal role in obesity and nutrition studies. However, objectively measuring nutrition intake is not easy. Under natural settings with less restriction, two approaches are often used: self-report and biomarkers. Biomarker approaches are considered more accurate compared with self-report; however, they are typically expensive and require special equipment for each nutrient. Self-report approaches are less expensive and do not require special laboratory equipment or techniques, and can be applied to the measurement of any nutrition components from macronutrients (i.e., carbohydrates, fat, and protein) to micronutrients (i.e., minerals and vitamins); however, self-reported data are known to be fraught with bias (1, 2).
Consider the example of biomarker versus self-report energy intake. Energy intake (EI) is defined as a sum of the total metabolizable energy content of consumed foods and beverages (3). EI can be measured using biomarkers, especially by energy balance approaches in which respiratory gas analysis or doubly labeled water (DLW) are used for the calculation of energy expenditure (EE) (4). EI can be calculated using EE accounting for change in energy stores (i.e., body composition) during the period of measurement. The respiratory gas analysis typically requires the participants to wear a gas mask or stay in a metabolic chamber (5), which restricts participants’ behavior; thus, the measured EI using the respiratory gas analysis may not reflect EI from habitual eating behavior. DLW requires the participants to visit the laboratory to drink labeled water enriched with stable hydrogen and oxygen isotopes and collect urine for measurement of isotope levels. It is considered to reflect habitual eating behavior and widely accepted as a standard and reliable approach in measuring EI in free-living individuals (6-8). However, given the high cost of isotopes and laboratories to analyze collected urine, DLW is not practical in large-scale epidemiological surveillance (9).
EI measured using self-report approaches (EISR) is computed by summing up the energy intake from foods and beverages reportedly consumed during the period of measurement, which can commonly range from a day to a year depending on approaches (e.g., 24-hour recall, food diary, and food frequency questionnaire) (10-12). Given that self-report approaches are low cost and scale-up relatively easily, EISR is still widely used in epidemiological studies. However, EISR is biased compared with the EI measured by biomarker such as DLW (EIBIO) (1) and is discouraged from use to estimate actual EI (2). The mechanism behind the reporting bias in EISR has been argued elsewhere. For example, EISR is computed from the information of reported foods and beverages using tables of food and beverage nutrients, composed of weights, calories, and the amount of macro-and micronutrients. Compositions of foods and beverages are different among brands, stores, and seasons (13), and thus nutrient databases cannot be exhaustive. Consequently, EISR using such databases may not be accurate (14). Further factors, including social desirability (i.e., people do not want to be seen as a “big eater” in general) (15) and weight/social status (15-19), are known to be associated with reporting bias. Thus, the difference between EIBIO and EISR is due to systemic biases rather than a random error.
Despite concerns about the accuracy of self-report approaches, they have been predominantly used in large scale nutrition epidemiology due to their high feasibility. Approaches to mitigate the bias in EISR have been argued, including commonly used approaches to exclude the data of EISR that are considered unreliable. For example, one approach is to exclude those reporting EISR out of the range considered by the researchers to be plausible, such as from 500 to 3500 kcal/day (9). However, this rule does not consider individual variability and is not appropriate for those whose intake is truly above 3500 kcal/day, such as elite athletes or those whose body size is large and requires more than 3500 kcal/day to maintain their weight (20, 21).
Other approaches are to use EE prediction equations to account for individual variability in EI (22-28). If the EE predicted considering various factors (e.g., age, weight, sex) is far from EISR, those individuals are considered under/overreporting their actual EI. Indeed, such an approach has evidently reduced misclassification (29). Among proposed approaches, the Goldberg cutoffs (30) have been used in nutrition epidemiology to assess nutritional status in specific populations and investigate the association between nutritional status and health and socioeconomic outcomes (25-28, 31). Note that nutritional status in this context means dietary intakes in general; not only EI but also nutritional constituents (vitamin, fish oil, etc.) and dietary styles (Mediterranean, vegan, etc.) (32-36). Therefore, the rationale of using the Goldberg cutoffs (and other similar approaches) to exclude data from individuals considered to have unreliable EISR is based on an assumption, “if total EI is underestimated, it is probable that the intakes of other nutrients are also underestimated” (37). The corollary for overestimation may also be true.
Bias-correcting approaches like the Goldberg cutoffs are frequently used in nutrition studies. By bias, we are referring to the difference between the estimates and their true values. Here we focus on two typical estimands in nutrition epidemiology: the mean of nutrition intake, and the associations between nutrition intake and health outcomes in a population. However, whether the Goldberg cutoffs reduce bias has not been proved theoretically or empirically. In our previous study, we demonstrated that the Goldberg cutoffs do not necessarily eliminate the bias in estimating the associations between EI and various health outcomes (38). Extending our previous study, we consider nutritional intake beyond EI to include biomarkers of sodium, potassium, and protein with the primary goal to examine if the Goldberg cutoffs eliminate or reduce the bias using a single dataset.
Evaluating the performance of the Goldberg cutoffs solely depending on a single empirical dataset is limited because the dataset is a single realization from an unobserved data-generation process. Further, if the dataset is too small, conclusions may be limited because of issues related to power to detect bias in associations or the power to detect reductions in bias. Therefore, in addition to the empirical data analyses above, we also generated data through simulation and analyzed those generated data that preserve the characteristics of the empirical data. The simulation further enables us to assess the impact of sample size on the performance of the Goldberg cutoffs.
RESULTS
1. Statistical data analysis on IDATA
The list of variables, equations, and metrics is available in Table 1. Abbreviations are summarized in Supplemental Table 1.
The impact of the Goldberg cutoffs on the reporting bias in nutrition intake
Table 2 summarizes the data included in the analyses (n=303). More than 90% of the participants are non-Hispanic whites, and their mean age was 63. The mean BMI was 27.7 kg/m2, and 30% had obesity (BMI≥30). There was significant mean underreporting in which the biomarker nutrition intakes (NIBIO) was greater than the self-reported nutrition intakes (NISR) in all four types of nutrition intake (Table 2).
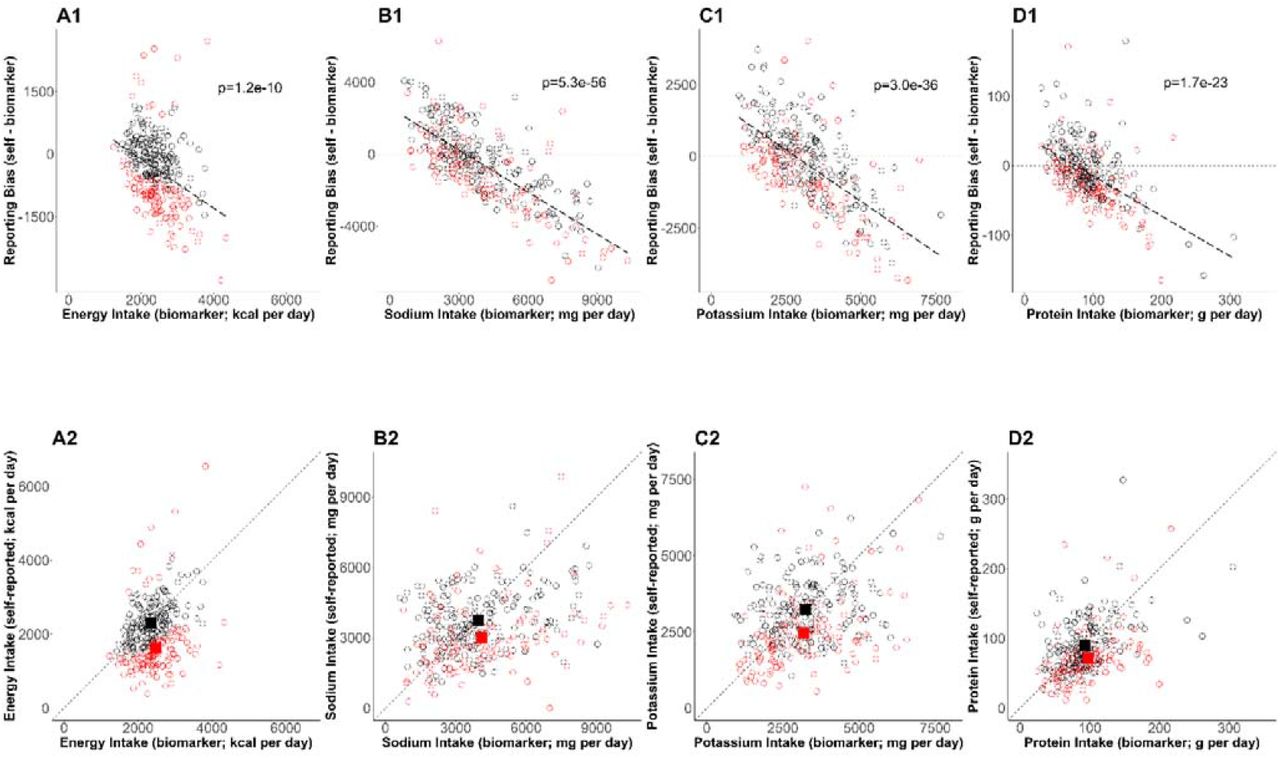
By the Goldberg cutoffs, 120 among 303 participants were excluded (40%) (Table 3). There was significant underreporting in the rejected cases, whereas reporting bias (NISR - NIBIO) was not significant in the accepted cases in all four NI. Further, the difference in the biases between the accepted and the rejected cases was significant. The mean NISR in the accepted cases was significantly larger than that in the rejected cases in all four NI. NIBIO was significantly larger in the rejected cases in sodium intake (SI), whereas it was comparable between those groups in energy intake (EI), potassium intake (PoI), and protein intake (PrI). To further understand the dependency of the bias on NIBIO and the impact of the Goldberg cutoffs on the bias, the individual data were plotted (Figure 1). The bias was significantly and negatively correlated with NIBIO (Figure 1 top panels). The means of accepted cases of NISR correspond to the mean of NIBIO better than the mean of NISR in the rejected cases (Figure 1 bottom panels).

(Upper panels) The error in mean of self-reported nutrition intake (A: energy intake, B: sodium intake, C: potassium intake, D: protein intake) and relevant nutrition intake measured by biomarkers are plotted. The regression lines are plotted with dashed lines and the corresponding p-values are stated. The dotted horizontal lines at zero indicate there is no error in nutrition intake. The red circles and black circles are the rejected cases and the accepted cases, respectively. (Bottom panels) Self-reported nutrition intake and biomarker-based nutrition intake measured are plotted. Closed red and black squares are the mean of nutrition intake in the rejected cases and the accepted cases (NIG), respectively.
These findings suggest that the Goldberg cutoffs reduce (and may eliminate) the bias in mean NISR by identifying predominantly underreporting individuals. The difference in self-reported nutrition intake between accepted and rejected cases is predominantly from differences in reporting and less so from differences in actual biomarker-measured intake. However, statistically significant differences in biomarker-measured intake remained between accepted and rejected cases in SI.
Associations between nutrition intake and health outcomes
The associations between EIBIO, SIBIO, and PrIBIO and WC were statistically significant (Supplemental Figures 1 and 2 and Supplemental Table 2). PoIBIO was significantly associated with VO2. Assuming that the biomarker-based health outcome associations 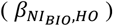 and self-report-based health outcome associations
and self-report-based health outcome associations 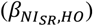 are different, the associations of health outcomes with self-report after applying the Goldberg rule
are different, the associations of health outcomes with self-report after applying the Goldberg rule 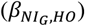 are expected to be between raw self-report and biomarker-based exposures. In other words, the Goldberg cutoffs are supposed to reduce the bias:
are expected to be between raw self-report and biomarker-based exposures. In other words, the Goldberg cutoffs are supposed to reduce the bias:  . We first tested whether bias exists for each nutrition-health outcome pair, and, if so, whether the bias is overestimation or underestimation, using percent bias (b). The percent bias (b) was significantly below 0% (underestimation) in only limited cases (EI and BW, and EI and WC) and we could not conclude whether the bias exists or not for the rest of the cases. Significant overestimation (b > 0) was not observed in any cases (the left panel in Figure 2 and Supplemental Table 2). Note that significant underestimation from self-report was observed in the cases with significant associations in nutrition intake estimated from biomarkers and health outcomes. Second, we tested whether the bias remains after applying the Goldberg cutoffs, and, if so, whether it is overestimation or underestimation, using the percent remaining bias (r). The bias was reduced (|r| < 100) but remained (r ≠ 0) for the association between EI and BW, and between EI and WC. We could not again conclude whether the bias exists or not after applying the Goldberg cutoffs for the rest of the cases.
. We first tested whether bias exists for each nutrition-health outcome pair, and, if so, whether the bias is overestimation or underestimation, using percent bias (b). The percent bias (b) was significantly below 0% (underestimation) in only limited cases (EI and BW, and EI and WC) and we could not conclude whether the bias exists or not for the rest of the cases. Significant overestimation (b > 0) was not observed in any cases (the left panel in Figure 2 and Supplemental Table 2). Note that significant underestimation from self-report was observed in the cases with significant associations in nutrition intake estimated from biomarkers and health outcomes. Second, we tested whether the bias remains after applying the Goldberg cutoffs, and, if so, whether it is overestimation or underestimation, using the percent remaining bias (r). The bias was reduced (|r| < 100) but remained (r ≠ 0) for the association between EI and BW, and between EI and WC. We could not again conclude whether the bias exists or not after applying the Goldberg cutoffs for the rest of the cases.

Italic bold font denotes significant associations between nutrition intake measured by biomarkers and the outcome. Open squares correspond to the maximum likelihood estimators and the bars are 95% CIs. Closed squares are plotted at the left end or right end of the panel when the point estimate is beyond the x-axis limits. Using three types of regression coefficients (βSR : self-reported data, βBIO : biomarker data, βG : Goldberg accepted data), three metrics were defined. (Left panel) Percent bias of the linear regression coefficient, bβ = (βSR − βBIO)/βBIO ∗ 100(%), was computed. *: Significant bias was observed. (Right panel) Percent remaining bias of the linear regression coefficient, dβ = (βG − βBIO)/ βBIO ∗ 100 (%), was computed. #: Significant bias reduction was observed (i.e., bias reduction 95%CI is within -100 to 100). *: Significant remaining bias was observed.
From the above data analyses, we could not conclude that the Goldberg cutoffs do or do not remove the bias in most cases, because of the wide confidence intervals, which could be partially due to the sample size of the data and weak associations between some combinations of NI and HO.
2. Simulation
To strengthen the arguments on the performance of the Goldberg cutoffs, we also generated and analyzed data which preserve the characteristics of the IDATA. The simulation was designed to overcome the sample size limitations of IDATA, but keep the structure and nature of the IDATA.
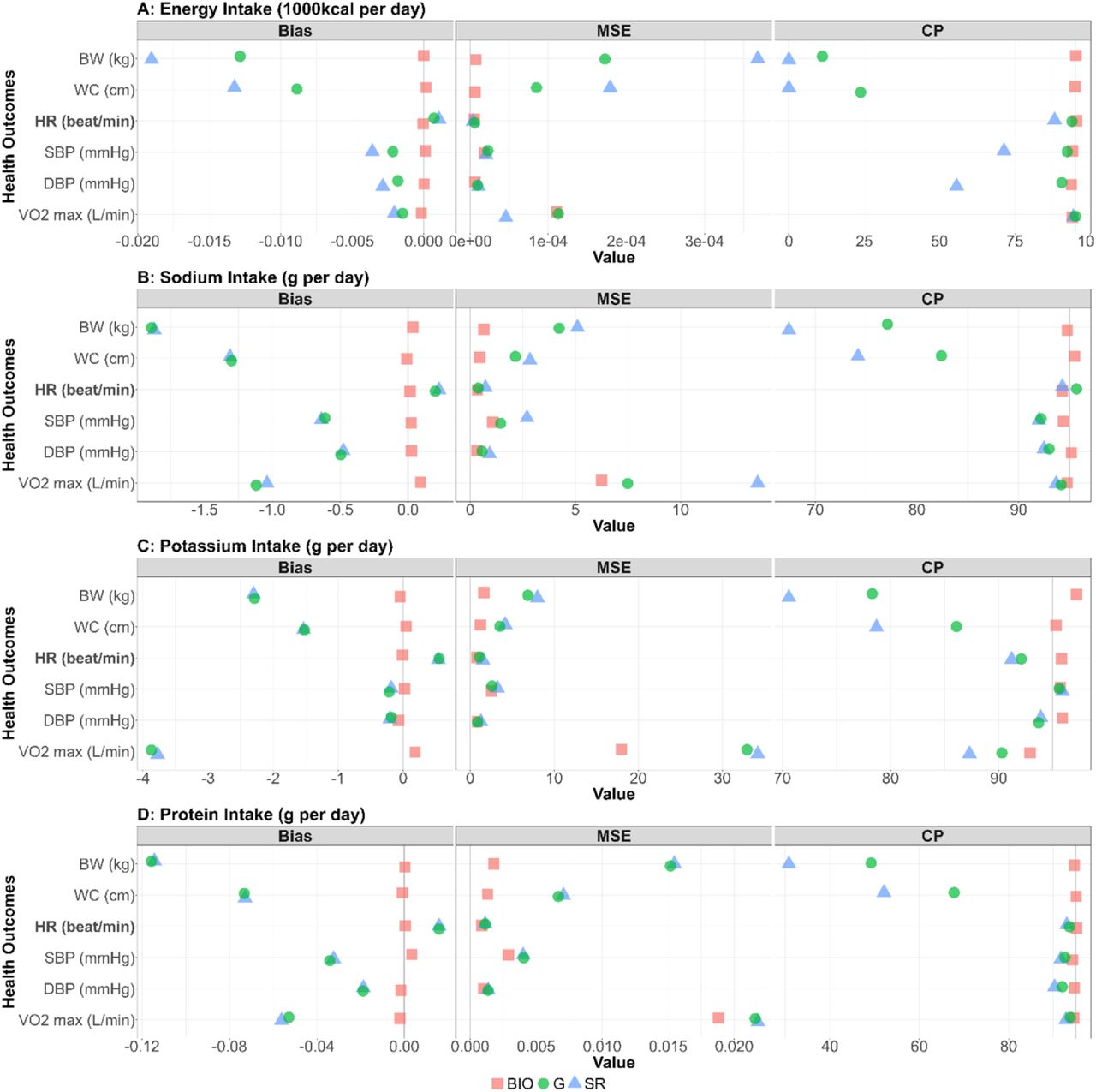
Performance metrics (bias, MSE, and coverage probability) for all the combinations between NI and HO are shown in Figure 3. For each performance metric, the mean across the 1,000 simulation replicates is shown. We confirmed the generated biomarker data were consistent with the IDATA (Supplemental Figure 3). The bias for all biomarker simulations was close to 0 (red squares in Figure 3). For all four NI, the associations with HR were negative and those with the other outcomes were positive (Supplemental Figures 1 and 2). For the cases with positive correlation, the positive bias in  was observed, and for the cases with negative correlation, the negative bias in
was observed, and for the cases with negative correlation, the negative bias in  was observed, suggesting that the self-reported data cause attenuation bias (i.e.,
was observed, suggesting that the self-reported data cause attenuation bias (i.e., 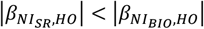 ) as observed in many studies (51). After application of the Goldberg cutoffs, the bias was reduced in 14 among 24 combinations of NI and HO. Notably, the bias was reduced in all six outcomes and reduction was large when EI is used as a predictor. When SI, PoI, and PrI are used as predictors, the bias was not much changed by applying the Goldberg cutoffs. In most cases, the MSE was also smaller for NIBIO compared with NISR, and the MSE for NISR became smaller after applying the Goldberg cutoffs (Figure 3). The coverage probabilities (cp) were close to 95% when NIBIO was used as a predictor, as was expected, whereas it was mostly lower than 95% when NISR was used. The coverage probability increased by applying Goldberg cutoffs; however, it is still lower than 95% in most cases. We repeated the simulation for other values (n = 50, 100, 200, and 300) of sample size and all cases showed similar results (Supplemental Figure 4). We ran sensitivity analyses varying η, an error term for the regression between NI and HO, and σ, the standard deviation of the reporting bias (Supplemental Figure 5). Biases were not affected by varying η for the range of values we considered, suggesting that error in health outcomes (or variance in health outcomes which cannot be explained by variance in biomarker-based nutrition intake) does not influence NI-HO association estimations where NI is used as an independent variable. Bias was negative when self-reported data (NISR or NIG) were used under the default value of σ, and the magnitude of bias increased as σ increased (i.e., the association was attenuated). However, when the error is extremely small (e.g., σ=0.25 in Supplemental Figure 5), the bias becomes positive, which is because the mean error function (µ) was negative at low NI and positive at high NI, thus the association was intensified. Whether or not the bias becomes positive or negative is determined by the balance between the mean error function and random error.
) as observed in many studies (51). After application of the Goldberg cutoffs, the bias was reduced in 14 among 24 combinations of NI and HO. Notably, the bias was reduced in all six outcomes and reduction was large when EI is used as a predictor. When SI, PoI, and PrI are used as predictors, the bias was not much changed by applying the Goldberg cutoffs. In most cases, the MSE was also smaller for NIBIO compared with NISR, and the MSE for NISR became smaller after applying the Goldberg cutoffs (Figure 3). The coverage probabilities (cp) were close to 95% when NIBIO was used as a predictor, as was expected, whereas it was mostly lower than 95% when NISR was used. The coverage probability increased by applying Goldberg cutoffs; however, it is still lower than 95% in most cases. We repeated the simulation for other values (n = 50, 100, 200, and 300) of sample size and all cases showed similar results (Supplemental Figure 4). We ran sensitivity analyses varying η, an error term for the regression between NI and HO, and σ, the standard deviation of the reporting bias (Supplemental Figure 5). Biases were not affected by varying η for the range of values we considered, suggesting that error in health outcomes (or variance in health outcomes which cannot be explained by variance in biomarker-based nutrition intake) does not influence NI-HO association estimations where NI is used as an independent variable. Bias was negative when self-reported data (NISR or NIG) were used under the default value of σ, and the magnitude of bias increased as σ increased (i.e., the association was attenuated). However, when the error is extremely small (e.g., σ=0.25 in Supplemental Figure 5), the bias becomes positive, which is because the mean error function (µ) was negative at low NI and positive at high NI, thus the association was intensified. Whether or not the bias becomes positive or negative is determined by the balance between the mean error function and random error.

The bias, mean squared error (MSE), and the coverage probability in regression coefficients between four nutrition intakes (A: energy intake, B: sodium intake, C: potassium intake, D: protein intake) and six health outcomes (body weight, waist circumference, HR [heart rate] post fitness test, resting SBP [systolic blood pressure], resting DBP [diastolic blood pressure], and VO2 max) for 1000 replicates. Bold font denotes negative associations between nutrition intake measured by biomarkers and the outcome. Red square, blue triangle, and green circle represent biomarker-based nutrition intake, self-reported nutrition intake, and Goldberg accepted nutrition intake, respectively. (Left panel) The bias between estimated and true regression coefficients are plotted. The grey vertical line at zero indicates there is no bias between the true regression coefficient and the mean of the 1000 replicates. For each combination, if the green dot is closer to 0 than the blue dot, then that indicates Goldberg cutoff rule reduced the bias. (Middle panel) The MSE between estimated and true regression coefficients are plotted. The grey vertical line at zero indicates there is no bias between the true regression coefficient and the mean of the 1000 replicates. (Right panel) The coverage probability for simulation studies. The grey vertical line indicates coverage probability consistent with 95% confidence intervals.
DISCUSSION
Dietary self-reporting is a basic component of nutrition epidemiology, particularly for studies of nutrition-health relationships. However, reporting bias in nutrition intake is perhaps one of the greatest impediments to understanding the true effect of nutrition on disease. Failure to account for this bias in self-reports can affect the analysis and interpretation of studies designed to assess the influences of nutrition on health. Correlation or regression coefficients estimating associations between self-reported nutrition intakes and health outcomes can be subject to substantial error (52, 53). To address such reporting bias issues, there has been increased interest in the use of statistical models in conjunction with biomarker data (54, 55).
In this study, reporting bias in self-reported nutrition intake was demonstrated using both empirical data analysis and a simulation study. We first examined whether the bias in mean nutrition intake and the bias in the associations between nutrition intake and health outcomes are reduced by applying the Goldberg cutoffs to an empirical dataset, IDATA. We confirmed the bias in mean self-reported nutrition intake was eliminated by applying Goldberg cutoffs to exclude extreme reporters (mostly under-reporters). This bias can be mostly explained by differences in reporting between the accepted and rejected cases rather than a difference in actual nutrition intake between the accepted and rejected cases. We further tested whether the associations between health outcomes and nutrition intake are biased when self-reported data are used, and whether the bias is reduced by applying the Goldberg cutoffs. The significant bias for the associations between EI and BW and the association between EI and WC were reduced but remained after applying Goldberg cutoffs. We did not observe significant bias in associations for other nutrition-outcome pairs, and therefore cannot make conclusions regarding the utility of applying the Goldberg cutoffs to reduce bias for these associations in the empirical data.
To overcome the limitations of the data (i.e., sample size and weak associations among many nutrition-outcome pairs), we generated and analyzed data preserving the characteristics of the IDATA for the assessment of the Goldberg cutoffs. We confirmed the existence of bias in estimated associations when the self-reported data were used, and these biases were reduced, but not eliminated, by applying the Goldberg cutoffs in general. We also confirmed large MSE and low coverage probability when self-reported data were used; MSE and low coverage probability were improved by using Goldberg cutoffs, but were not recovered to the levels of biomarker data. Overall, the empirical data analyses and the simulation study suggest that the Goldberg cutoffs improve the estimates in nutrition-health outcome associations; however, the biases were not completely removed.
This study has several strengths. First, although energy intake has traditionally been studied more with respect to Goldberg cutoffs, herein we also investigated three other nutrition intakes: sodium, potassium, and protein. In our previous study, we used only energy intake as a predictor (38). However, given that the Goldberg cutoffs are believed to reduce the bias in nutrition intake broadly, we expanded the approach to these other nutrition intakes, which can be measured by biomarkers (37). Second, we conducted the simulation in addition to empirical data analyses. There are two advantages of the simulation design. 1) The data generation process was based on the IDATA dataset. Thus, we were able to simulate datasets reflective of those that would be seen in the real world. Both the sample size of the generated dataset and the variables that we considered are reflective of what is often observed in nutrition studies. 2) Simulation can consider different models for the data-generating process. Although our objective was not to disentangle the underlying data generation mechanisms, we were able to generate data that preserve the characteristics of the IDATA.
The limitations of this study are worth noting. In the analysis of IDATA, we used only bivariate associations for nutrition-health outcomes. It is possible that including various covariates or different models may influence the existence or lack of bias in nutrition-health associations. In the data-generation process for the simulations, assumptions were made on parameter settings. The reporting bias was set to be normally distributed. Modeling the bias using other distributions (such as a heavier tailed distribution that may be more consistent with a zero-bounded intake) may improve model fit, and thus generated more realistic data. We simulated the bias with constant variance, consistent with the apparent stability of variance across the intake quantiles in Supplemental Figure 6 and Supplemental Table 4; however, modeling the variance as a function of intake quantile may alter the data-generating process. We used the self-reported nutrition intake reported by ASA24, as it reflects recent dietary intake. The bias we observed in this study may be different for other self-report methods. Finally, the simulation approach, although based on the IDATA, was nonetheless generated from a limited sample size. We are not aware of thresholds for sufficient sample size for empirical-data-based simulation, and we have had success with smaller plasmode based sampling in the past(56, 57); however, it is possible a larger, more representative, or more robust empirical data set may influence both the empirical and simulated results. Further as the data was from a single population in which white and relatively older people are predominant, generalizability of the study finding should be carefully considered.
In conclusion, we found that the Goldberg cutoffs reduce and eliminate the bias in mean nutrition intake in the IDATA dataset; however, the bias in the associations between nutrition intake and health outcomes, when they exist, can sometimes be reduced but not eliminated by the Goldberg cutoffs in both empirical and simulated results. Investigators considering excluding extreme reporters in epidemiological studies should consider whether such approaches are likely to be helpful in answering their specific research questions, as our study has shown that such cutoffs are more useful in estimating mean nutrition intakes than in studies of associations between nutrition intake and health outcomes.
MATERIALS AND METHODS
We conducted a set of empirical analyses to assess the reporting bias due to self-report and examine whether the Goldberg cutoffs reduce reporting bias using the data from The Interactive Diet and Activity Tracking in the American Association of Retired Persons (IDATA) study (39). The reporting bias in the mean of nutrition intakes and the associations (regression coefficients) between nutrition intakes and health outcomes were assessed. We also conducted a simulation study to investigate the performance of Goldberg cutoffs using the results from the empirical analyses as ground truth. Note that in data analyses, we assumed the estimates from biomarkers are the true values, since the true values (i.e., population parameters) are unobservable.
Among various nutrition intakes (NI), we considered sodium intake (SI), potassium intake (PoI), and protein intake (PrI) in addition to energy intake (EI). These NI were selected because they can be measured by urine samples as well as self-reports. We denote self-reported NI by NISR: EISR, SISR, PoISR, and PrISR. We denote biomarker-based NI by NIBIO: EIBIO, SIBIO, PoIBIO, and PrIBIO. The NISR data remaining after applying the Goldberg cutoffs (hereafter, we call those ‘accepted cases’) are denoted by NIG: EIG, SIG, PoIG, and PrIG. Health outcomes (HO) that may be associated with NI were selected from the data dictionaries; body weight (BW), waist circumference (WC), heart rate after fitness test (HR), resting systolic blood pressure (SBP), resting diastolic blood pressure (DBP), and VO2 max (VO2). The estimated regression coefficients are denoted by the subscript of the explanatory variables and the health outcomes (e.g., 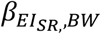 , represents the association between self-reported EI and body weight).
, represents the association between self-reported EI and body weight).
Goldberg cutoffs
The Goldberg cutoffs are an approach to identify those who report low or high energy intake that, if sustained across long periods of time, would be implausible to sustain life (for underreporting) or present weight (for overreporting), by comparing the reported EI and the energy expenditure (EE) predicted from body composition and physical activity level (30). First, EE is predicted as a product of physical activity level (PAL) and basal metabolic rate (BMR): EE=PAL*BMR. PAL is assumed to be 1.75 (40). BMR is predicted using fat-free mass (41): BMR = 370 + 21.6 * FFM. Second, the ratio of EISR and predicted EE is computed and examined whether it is in a reasonable range: 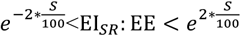 , where S is defined as:
, where S is defined as: 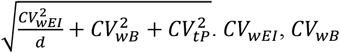 , and CVtP are the within-subject variation in EISR, the within-subject variation in BMR, and the total variation in PAL, and d is the number of days of diet assessment. We set CVwEI = 23 (%), CVwB = 8.5 (%), CVtP = 15 (%), and d = 7 following the previous study (42). Finally, if individuals are not in the range, they were considered under- or overreporters and were excluded from further analyses.
, and CVtP are the within-subject variation in EISR, the within-subject variation in BMR, and the total variation in PAL, and d is the number of days of diet assessment. We set CVwEI = 23 (%), CVwB = 8.5 (%), CVtP = 15 (%), and d = 7 following the previous study (42). Finally, if individuals are not in the range, they were considered under- or overreporters and were excluded from further analyses.
Data
Overview of IDATA
The IDATA study was designed “to evaluate and compare the measurement error structure of diet and physical activity assessment tools against reference biomarkers.” (39) The study participants “were recruited from a list of AARP [American Association of Retired Persons] members aged 50-74 years residing in and around Pittsburgh, Pennsylvania” (39) and were screened for eligibility by phone interview or clinic visit. The eligibility criteria were speaking English, having internet access, having no major medical issues (such as diabetes, renal/heart failure, and any conditions affecting fluid balance), having no mobility issues, and having BMI between 18.5 and 40.0 (kg/m2). The participants “visited the study center three times and also completed assigned activities at home over a 12-month period” (39) from early 2012 through late 2013 (39, 43). Self-reported dietary/physical activity information, biomarker data to estimate dietary intake, and the data from physical objective monitors to estimate physical activity were collected. In addition, demographic information (age, sex, race/ethnicity) and anthropometric measurements (weight, height, and waist circumference) were obtained at a clinical visit or phone screening.
Self-reported nutrition intake: NISR
For self-report dietary assessment (EISR, SISR, PoISR, and PrISR), four different approaches were used in IDATA: Automated Self-Administered 24-Hour Dietary Assessment Tool (ASA24) (44), Diet History Questionnaire (DHQ-II), 7-day food checklist, and 4-day food record. These SR approaches were conducted at different times during the IDATA study. We used the data of ASA24 in our analyses because they were collected closest in time to the DLW measurements. ASA24 is an online self-administered recall system asking about a 24-hour dietary recall for the previous day, from midnight to midnight, using a dynamic user interface.
Biomarker-based nutrition intake: NIBIO
Three approaches were used for biomarker assessment of NI: DLW, urine, and saliva (not used herein). EIBIO was computed from DLW data, and SIBIO, PoIBIO, and PrIBIO were calculated from 24-hour urine samples. EIBIO was estimated as a sum of daily total energy expenditure estimated from DLW and daily change in energy stores during the DLW period. Total energy expenditure was calculated using the approach proposed by Schoeller et al. (6), where the respiratory quotient was assumed as 0.86. Daily change in energy stores during the DLW period (about 2 weeks) was computed from the average daily weight change during the period assuming the energy density of body weight was 2380 kcal/kg (45). The urinary values obtained from 24-hour urine samples were converted into nutrition intakes assuming that 81%, 80%, and 86% of consumed nitrogen, potassium, and sodium are excreted in the urine, respectively. Dietary protein was calculated assuming that 16% of protein is nitrogen. A more comprehensive explanation of measuring EIBIO, SIBIO, PoIBIO, and PrIBIO is reported elsewhere (46).
Health outcomes
From health outcomes (HO) available in IDATA, we selected objective variables that were potentially associated with nutrition intake. BW (kg) and WC (cm) were obtained at clinical visits; HR (beat/min after fitness test), SBP (mmHg), DBP (mmHg), and VO2 max (L/min) were obtained by the modified Canadian Aerobic Fitness Test (mCAFT) (47).
Summary of the data
In IDATA, NISR, NIBIO, and HO were repeatedly measured at different time points. For fair comparison among them, we selected the data measured in the same month; thus, the data of Month 0 and Month 11 were used from Groups 1&3 and Groups 2&4, respectively (39). From 1,082 participants, we excluded 779 participants because we did not have information necessary to apply the Goldberg cutoffs (no fat-free mass information [n=725] or NISR [n=240]) or there was no urine-based nutrition intake data [n=231]. The remaining 303 participants’ data were analyzed.
IDATA data were accessible through the Cancer Data Access System (https://biometry.nci.nih.gov/cdas/idata/; downloaded 11/22/2017) after our project proposal was reviewed and approved by the National Cancer Institute (https://biometry.nci.nih.gov/cdas/approved-projects/1702/).
Statistical analysis of IDATA
Whether the bias in the mean NISR compared to NIBIO (e.g., calculated as EISR - EIBIO) would be reduced by the Goldberg cutoffs was tested. We first tested whether the mean bias in each NISR is significantly different from zero. Then, we repeated the same test for the data of the accepted cases for each NIG (e.g., EIG - EIBIO). We further tested whether the mean NISR are different between those who were removed (rejected cases; NISR excluding NIG) and the accepted cases (NIG).
Further, we tested whether the bias in the estimates of associations between NI and HO would be reduced by the Goldberg cutoffs. We computed regression coefficients (βNI,HO) between HO and each of the three different NI measuring approaches: NIBIO, NISR, and NIG. Note that we did not adjust the analyses for any other covariates, because the purpose of this study is to understand if the Goldberg cutoffs could reliably reduce bias rather than to refine associations accounting for covariates. To comprehensively assess the reporting bias and bias reduction in different outcomes with different units, we used standardized metrics for reporting bias and bias reduction, which was originally proposed in our previous study (38). In brief, we used the percent bias (b) for the assessment of the magnitude of the bias and the percent remaining bias (r) for the assessment of the magnitude of the bias remaining after applying the Goldberg cutoffs, which are defined as follows:
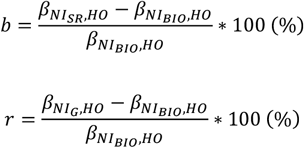 A more in-depth interpretation of the metric is available in our previous study (38). Jackknife estimation (leave-one-out) (48) was used to compute 95% CIs of those metrics. All analyses were performed separately for each combination of nutrition intakes and outcomes. Two-tailed Student’s t test was used to test whether mean of a single variable is different from zero. Two-tailed independent Welch’s t test was used to test the mean difference of a single variable from two independent groups. The jackknife method was used to test the mean difference of a single variable from two non-independent groups (i.e., whole data vs the data of accepted cases). The type I error rate was fixed at 0.05 (2-tailed).
A more in-depth interpretation of the metric is available in our previous study (38). Jackknife estimation (leave-one-out) (48) was used to compute 95% CIs of those metrics. All analyses were performed separately for each combination of nutrition intakes and outcomes. Two-tailed Student’s t test was used to test whether mean of a single variable is different from zero. Two-tailed independent Welch’s t test was used to test the mean difference of a single variable from two independent groups. The jackknife method was used to test the mean difference of a single variable from two non-independent groups (i.e., whole data vs the data of accepted cases). The type I error rate was fixed at 0.05 (2-tailed).
Simulation
To strengthen the arguments on the performance of the Goldberg cutoffs, we also generated and analyzed data that preserve the characteristics of the IDATA.
Data generation
We generated data composed of four variables: NIBIO (biomarker), NISR (self-reported), HO (health outcomes: BW, WC, HR, SBP, DBP, and VO2), and FFM (fat-free mass). NIBIO and FFM were resampled from the IDATA. HO is computed using a linear model using NIBIO as a predictive variable:
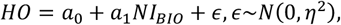 where α0, α1, and η2 are the model parameters estimated from the IDATA. NISR is generated by adding an error term (i.e., reporting error), e, to NIBIO, adapting the approach proposed by Ward et al. (49):
where α0, α1, and η2 are the model parameters estimated from the IDATA. NISR is generated by adding an error term (i.e., reporting error), e, to NIBIO, adapting the approach proposed by Ward et al. (49):
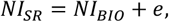 where e is determined by the percentile of NIBIO in the empirical distribution, p(NIBIO). The reporting error e is assumed to follow a normal distribution parametrized by percentile-specific mean, µ(p(NIBIO)), and a constant standard deviation, σ: e∼N(µ, σ). µ and σ were estimated by fitting polynomial models to the
where e is determined by the percentile of NIBIO in the empirical distribution, p(NIBIO). The reporting error e is assumed to follow a normal distribution parametrized by percentile-specific mean, µ(p(NIBIO)), and a constant standard deviation, σ: e∼N(µ, σ). µ and σ were estimated by fitting polynomial models to the 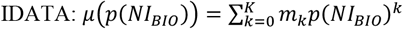 , where K is the order of the polynomial. The order of the polynomial function was varied from 1 to 5 and we selected the value of K that yields the smallest MSE. We used k-fold cross-validation with 10 folds to calculate the test MSE for each model. This resulted in k = 1, 3, 3, 5 for EI, SI, PoI, and PrI, respectively (Supplemental Table 3 and Supplemental Figure 6). For example, assuming EIBIO is 3000 kcal, which corresponds to 90.4 percentile, the mean of the reporting error, µ, was -749.6 and the standard deviation of the reporting error, σ, was 759.1. Therefore his/her e is randomly sampled from the normal distribution: N(−749.6,759.1). We further confirmed our assumption of homoskedastic σ is reasonable by the Goldfeld Quandt test(50) (Supplemental Table 4). The Goldfeld Quandt test compares variance in high and low values of a variable; we discarded the middle 20% of the total observations (eliminated the center 61 observations among 303 in total) to define the high and low groups. The simulated data were truncated so that NISR>0. The variable NIG was generated by applying the Goldberg cutoffs to EISR using FFM (thus, NIG is a subset of NISR). The above process was repeated for each NI. We generated n = 100 individuals, and the data generation was repeated 1000 times, leading to 1000 replicates. The data generating process is summarized in Figure 4.
, where K is the order of the polynomial. The order of the polynomial function was varied from 1 to 5 and we selected the value of K that yields the smallest MSE. We used k-fold cross-validation with 10 folds to calculate the test MSE for each model. This resulted in k = 1, 3, 3, 5 for EI, SI, PoI, and PrI, respectively (Supplemental Table 3 and Supplemental Figure 6). For example, assuming EIBIO is 3000 kcal, which corresponds to 90.4 percentile, the mean of the reporting error, µ, was -749.6 and the standard deviation of the reporting error, σ, was 759.1. Therefore his/her e is randomly sampled from the normal distribution: N(−749.6,759.1). We further confirmed our assumption of homoskedastic σ is reasonable by the Goldfeld Quandt test(50) (Supplemental Table 4). The Goldfeld Quandt test compares variance in high and low values of a variable; we discarded the middle 20% of the total observations (eliminated the center 61 observations among 303 in total) to define the high and low groups. The simulated data were truncated so that NISR>0. The variable NIG was generated by applying the Goldberg cutoffs to EISR using FFM (thus, NIG is a subset of NISR). The above process was repeated for each NI. We generated n = 100 individuals, and the data generation was repeated 1000 times, leading to 1000 replicates. The data generating process is summarized in Figure 4.

The associations between nutrition intake (EI: Energy Intake, SI: Sodium Intake, PtI: Potassium Intake, PrI: Protein Intake) and health outcomes (HO: body weight, waist circumference, heart rate after fitness test, resting systolic blood pressure, resting diastolic blood pressure, and VO2 max). The subscripts “SR”, “BIO”, and “G” denote self-reported NI, biomarker-based NI, and self-reported NI after applying the Goldberg cutoffs, respectively. Fat free mass is denoted by FFM and used to calculate the Goldberg cutoff threshold. An arrow from one node, A, to another, B, means “B is generated by A”. Rectangles represent the variables that are resampled from the empirical distribution, and ellipses are for the variables generated from the models.
Measurement of the performance of the Goldberg cutoffs
The point estimates of the regression coefficients for an NI and an HO from the ith simulation are denoted as 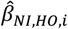 (e.g.,
(e.g., 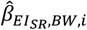 is the ith regression coefficient for self-reported energy intake and body weight). The performance of the Goldberg cutoffs was assessed by three metrics: bias, mean squared error (MSE), and coverage probability:
is the ith regression coefficient for self-reported energy intake and body weight). The performance of the Goldberg cutoffs was assessed by three metrics: bias, mean squared error (MSE), and coverage probability:
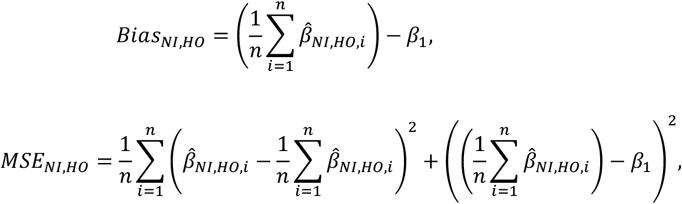
 where NI = {EISR, EIBIO, EIG, SISR, SIBIO, SIG, PoISR, PoIBIO, PoIG, PrISR, PrIBIO, PrIG}, HO = {BW, WC, HR, SBP, DBP, VO2}, I(•) is an indicator function, low and high represent the lower and upper 95% confidence intervals, and β1 is the true parameter value, which we define as the point estimate from the IDATA. Note that bias is used differently here than in the empirical analysis because the parameters remain unknown in the empirical analysis whereas we define the parameters in the simulation.
where NI = {EISR, EIBIO, EIG, SISR, SIBIO, SIG, PoISR, PoIBIO, PoIG, PrISR, PrIBIO, PrIG}, HO = {BW, WC, HR, SBP, DBP, VO2}, I(•) is an indicator function, low and high represent the lower and upper 95% confidence intervals, and β1 is the true parameter value, which we define as the point estimate from the IDATA. Note that bias is used differently here than in the empirical analysis because the parameters remain unknown in the empirical analysis whereas we define the parameters in the simulation.
Sensitivity analyses were performed varying the sample size and two other parameters: error term for the regression between health outcome and biomarker-based nutrition intakes (η), and the standard deviation of the reporting error (σ). All simulations and analyses were performed using the statistical computing software R (version 4.0.1); code book and analytic code are publicly and freely available without restriction at http://doi.org/10.5281/zenodo.7013204. The variables, data generation models, and metrics of performance of the Goldberg cutoffs are summarized in Table 1. STROBE guideline was followed, and the statement is available as supplementary material.
Data Availability
Code book and analytic code will be made publicly and freely available without restriction at http://doi.org/10.5281/zenodo.7013204. Data described in the manuscript are available through the National Cancer Institute per their terms of use (https://biometry.nci.nih.gov/cdas/idata/).
Supplementary Online Content
Supplemental Figures

The estimated linear regression: associations between (A) EI, (B) SI, (C) PoI, (D) PrI and (1) body weight (kg), (2) waist circumference (cm), and (3) heart rate after the fitness test (beat/min). Open blue squares, filled green squares, and open red circles correspond to self-reported nutrition intake of the whole cases, self-reported nutrition intake of the accepted cases, and nutrition intake measured by biomarkers, respectively. Dashed blue, dotted green, and solid red lines are estimated regression lines using the data with the corresponding color, respectively

The estimated linear regression: associations between (A) EI, (B) SI, (C) PoI, (D) PrI and (4) resting systolic blood pressure (mmHg), (5) resting diastolic blood pressure (mmHg), and (6) maximal oxygen uptake (L/min). Open blue squares, filled green squares, and open red circles correspond to self-reported nutrition intake of the whole cases, self-reported nutrition intake of the accepted cases, and nutrition intake measured by biomarkers, respectively. Dashed blue, dotted green, and solid red lines are estimated regression lines using the data with the corresponding color, respectively.

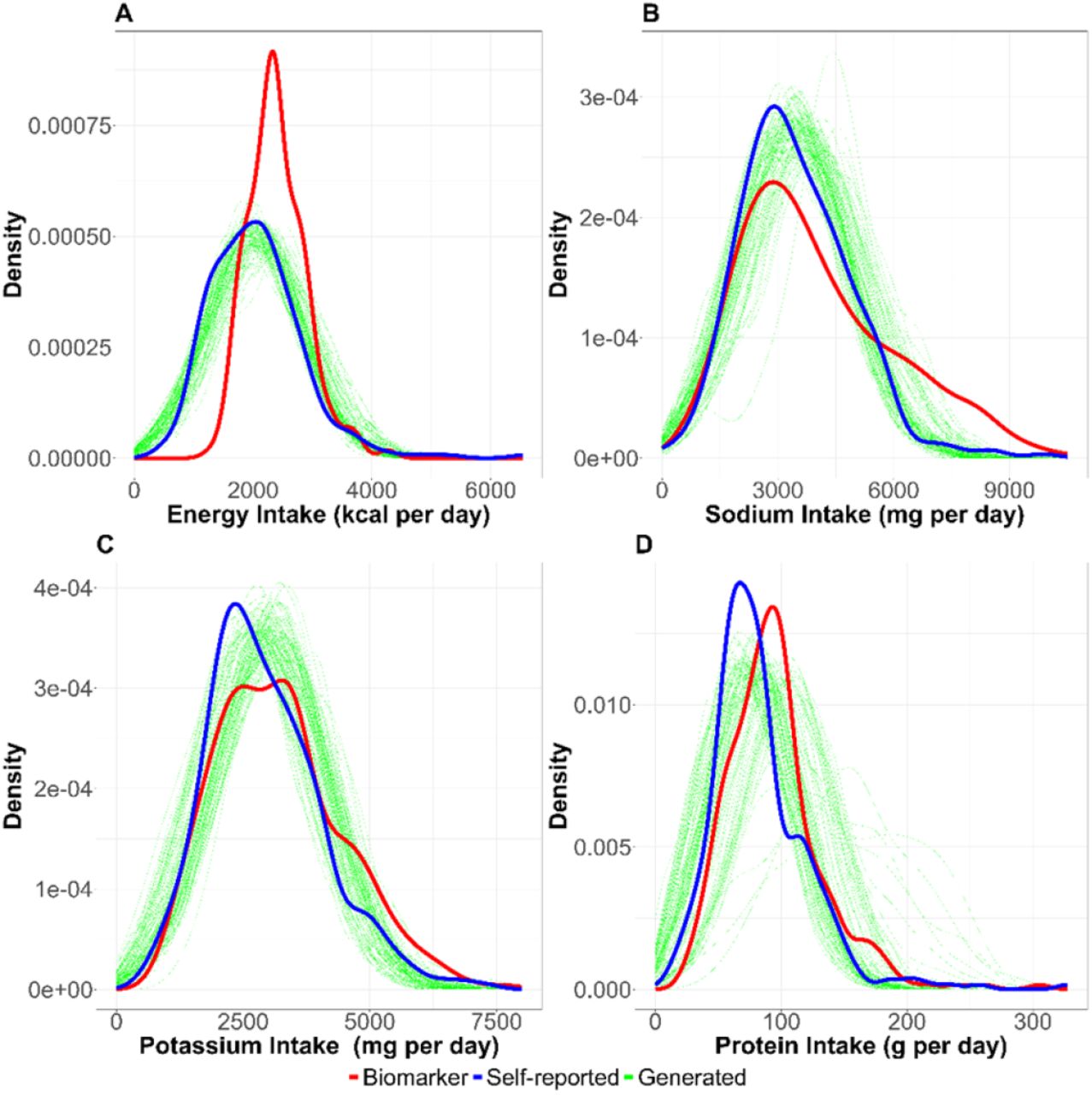
The distributions of nutrition intake (A: energy intake, B: sodium intake, C: potassium intake, and D: protein intake) are shown. Red, blue, and green lines correspond to biomarker-based nutrition intake, self-reported nutrition intake, and generated (self-reported) nutrition intake, respectively. Each simulation generating nutrition intake was with n=100 and the simulation was repeated 1000 times in this figure.

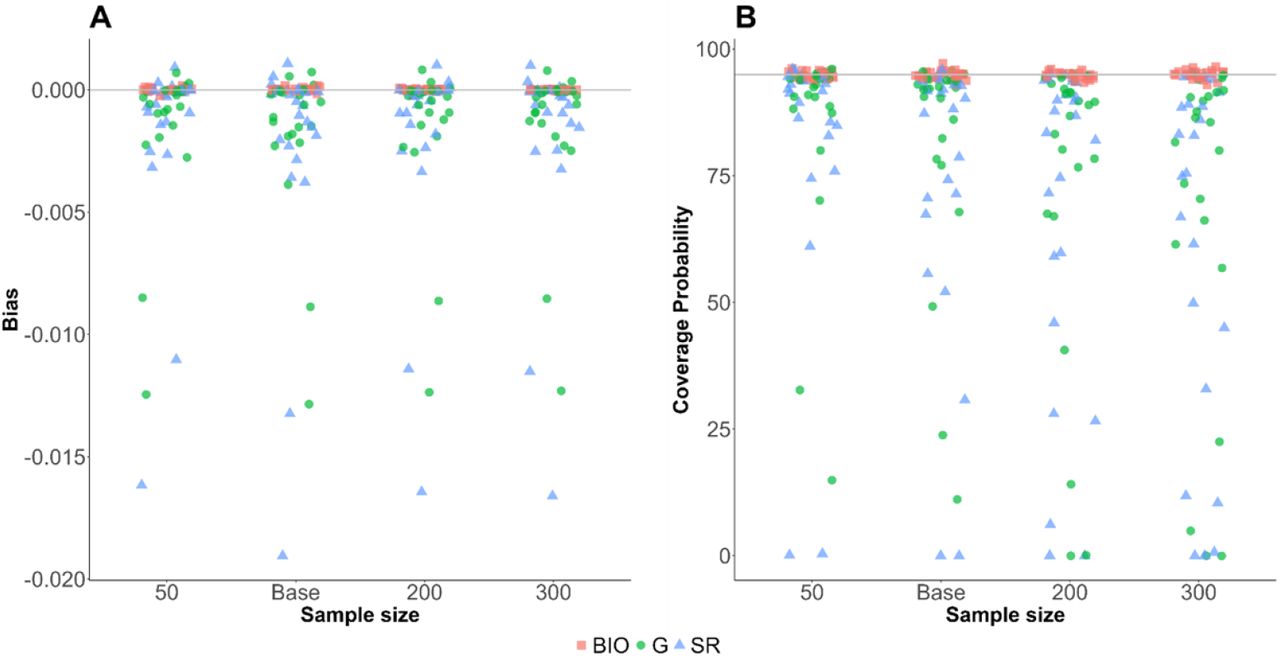
Sensitivity analysis of the sample size. The sample size was varied between 0.5 and 3 times of the baseline values (n = 50, 100, 200, and 300). Red square, blue triangle, and green circle represent bias (A) and coverage probability (B) for biomarker-based nutrition intake, self-reported nutrition intake, and Goldberg accepted nutrition intake, respectively.

Sensitivity analysis of the selected parameters. The parameters were varied between 0.25 and 2 times of the baseline values. Red square, blue triangle, and green circle represent bias for biomarker-based nutrition intake, self-reported nutrition intake, and Goldberg accepted nutrition intake, respectively.
(A) Error term for the regression between health outcome and biomarker-based nutrition intake (η) was varied. (B) Variance of the bias between self-reported nutrition intake and biomarker-based nutrition intake (σ) was varied.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
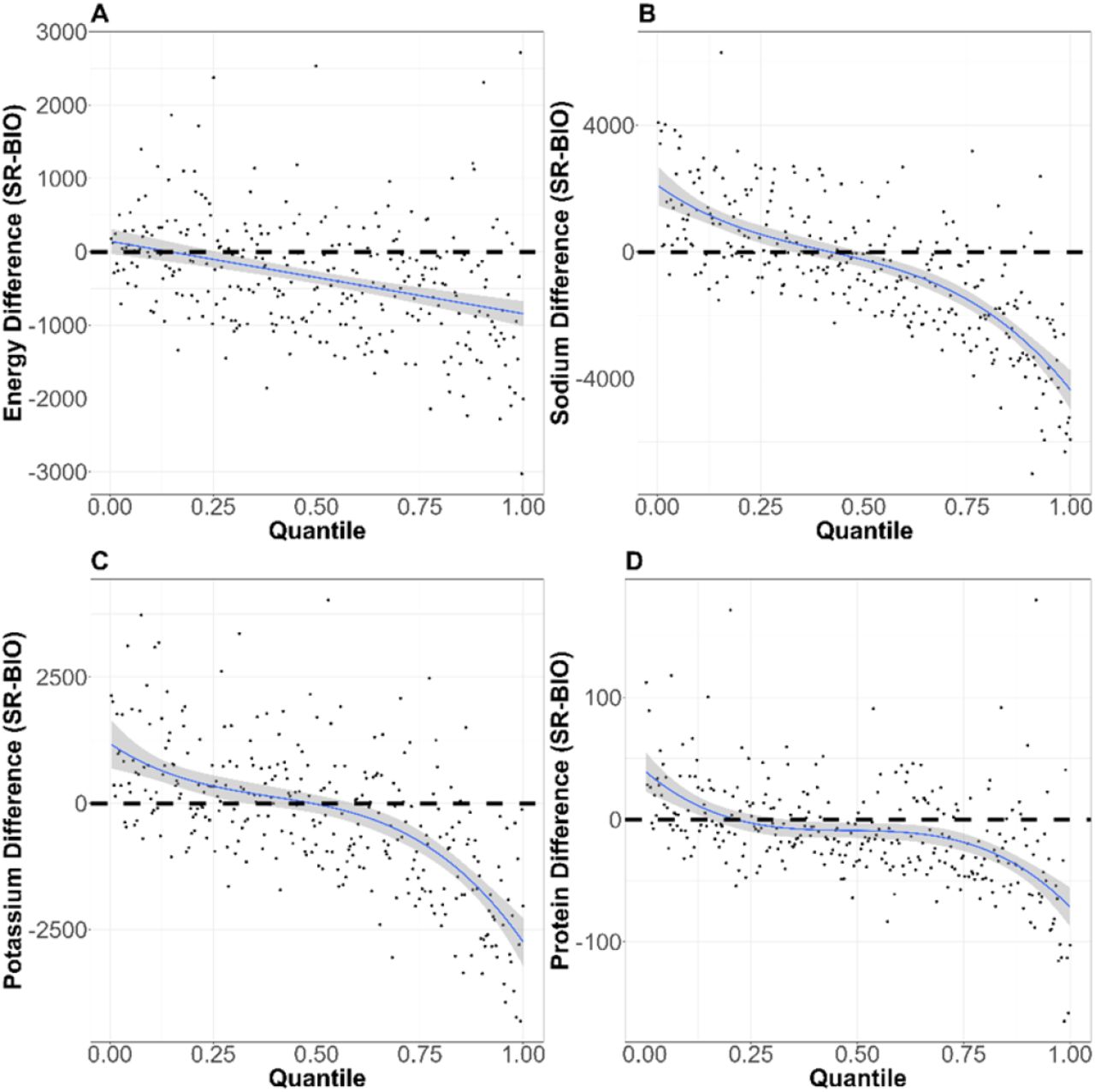
The distributions of reporting error on quantiles of different nutrition intakes (A: energy intake, B: sodium intake, C: potassium intake, and D: protein intake) are shown. The horizontal dotted lines correspond with no reporting error. The blue lines and the shaded areas are the fitted polynomials (degrees of polynomials are 1, 3, 3, and 5 for energy intake, sodium intake, potassium intake, and protein intake, respectively) and the 95% CI of the polynomials.
Supplemental Tables
Footnotes
Sources of Support: NIH grants R25HL124208, R25DK099080, R25GM141507, 1R01DK132385-01, U01-CA057030-29S1. Japan Society for Promotion of Science (JSPS) KAKENHI grant 18K18146. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health or any other organization.
Data sharing: Code book and analytic code will be made publicly and freely available without restriction at http://doi.org/10.5281/zenodo.7013204. Data described in the manuscript are available through the National Cancer Institute per their terms of use.
Competing Interests: AWB declares: in the past three years (since 2019-09-19), Dr. Brown has received travel expenses from International Food Information Council; speaking fees from Eastern North American Region of the International Biometric Society, Purchaser Business Group on Health, Purdue University, and University of Arkansas for the Medical Sciences; monetary awards from American Society for Nutrition; consulting fees from LA NORC, Pennington Biomedical Research Center, and Soy Nutrition Institute Global; and grants through his institution from Alliance for Potato Research & Education, American Egg Board, National Cattlemen’s Beef Association, NIH/NHLBI, NIH/NIDDK, and NIH/NIGMS. In addition, he has been involved in research for which his institution or colleagues have received grants or contracts from Center for Open Science, Gordon and Betty Moore Foundation, Hass Avocado Board, Indiana CTSI, NIH/NCATS, NIH/NCI, NIH/NHLBI, NIH/NIA, NIH/NIGMS, NIH/NLM, and Sloan Foundation. His wife is employed by Reckitt Benckiser. NY, KE, and RZ declare that they have no competing interests.
Abbreviations
- AARP
- American Association of Retired Persons
- ASA24
- Automated Self-Administered 24-Hour Dietary Assessment Tool
- BIO
- biomarker
- BW
- body weight
- DBP
- resting diastolic blood pressure
- DHQ-II
- Diet History Questionnaire
- DLW
- doubly labeled water
- EI
- energy intake
- EE
- energy expenditure
- FFM
- fat-free mass
- FM
- fat mass
- G
- Goldberg cutoffs
- HO
- health outcome
- HR
- heart rate
- IDATA
- Interactive Diet and Activity Tracking in American Association of Retired Persons
- MSE
- mean squared error
- NI
- nutrition intake
- PoI
- potassium intake
- PrI
- protein intake
- SI
- sodium intake
- SBP
- resting systolic blood pressure
- SR
- self-reported
- VO2
- VO2 max
- WC
- waist circumference.
References



