
ABSTRACT
Background Data integration of multiple epidemiologic studies can provide enhanced exposure contrast and statistical power to examine associations between environmental exposure mixtures and health outcomes. Extant studies have combined population studies and identified an overall mixture-outcome association, without accounting for differences across studies.
Objective To extend the novel Bayesian Weighted Quantile Sum (BWQS) regression to a hierarchical framework to analyze mixtures across multiple cohorts of different sample sizes.
Methods We implemented a hierarchical BWQS (HBWQS) approach that (i) aggregates sample size of multiple cohorts to calculate an overall mixture index, thereby identifying the most harmful exposure(s) across cohorts; and (ii) provides cohort-specific associations between the overall mixture index and the outcome. We showed results from six simulated scenarios including four mixture components in five and ten populations, and two real case-examples on the association between prenatal metal mixture exposure—comprising arsenic, cadmium and lead—and both gestational age and gestational age acceleration metrics.
Results Results from simulated scenarios showed good empirical coverage and little bias for all parameters estimated with HBWQS. The Watanabe-Akaike information criterion (WAIC) for the HBWQS regression showed a better average performance across scenarios than the BWQS regression. HBWQS results incorporating cohorts within the national Environmental influences on Child Health Outcomes (ECHO) program from three different sites (Boston, New York City (NYC), and Virginia) showed that the environmental mixture—composed of low levels of arsenic, cadmium, and lead—was negatively associated with gestational age in NYC..
Conclusions This novel statistical approach facilitates the combination of multiple cohorts and accounts for individual cohort differences in mixture analyses. Findings from this approach can be used to develop regulations, policies, and interventions regarding multiple co-occurring environmental exposures and it will maximize use of extant publicly available data.
1. Introduction
Environmental exposures are emerging as key factors to understanding the origin and prevention of human diseases.1 Although environmental exposures rarely occur in isolation, prevailing statistical approaches have traditionally analyzed them individually.2, 3 To accommodate the complexity of multiple co-occurring exposures and to assess their joint association with diseases, multiple mixture approaches2, 3 have been developed. Existing mixture approaches incorporate correlation structure among exposures, thereby limiting both a collinearity effect and standard-error inflation.4, 5 However, those methods fail to replicate mixture-outcome associations across cohorts,6 which limits their applicability to regulatory decisions.
To solve this issue, the majority of the studies have combined population studies and identified an overall mixture-outcome association, without taking into account the potential heterogeneity across key characteristics of the studies being combined.6, 7 A few novel statistical approaches have also proposed to identify clusters and factors commonly shared across datasets. For example, multi-study factor analyses identify factors common to all studies leveraging on joint models while the multiple dataset integration approach identifies groups of features that tend to be grouped together in multiple datasets, using a Dirichlet-multinomial allocation mixture and exploiting statistical dependencies between the datasets.8–10 However, those approaches identify clusters of features, but do not show the importance of individual features, thus yielding challenges in interpreting results.
Among the mixture approaches, our team developed the Bayesian Weighted Quantile Sum (BWQS) regression,11 which is a supervised quantile-based approach to assess the association of an outcome with multiple environmental exposures.11–14 All exposures are combined additively into a weighted index, with weights capturing the contribution of each exposure to the mixture.12–14 The BWQS regression provides simplicity of inference, easy interpretability, mixture-response association, and results that are insensitive to exposures’ outliers.11–14 In addition, the BWQS regression does not require a priori selection of the directionality of the mixture-outcome association, thus allowing flexibility of the coefficient estimates. Here we extend the framework of the BWQS regression to a hierarchical setting to accommodate mixture analyses across multiple cohorts of different sample sizes.
This work is organized in a stepwise fashion as follows: in Section 2, we reviewed the BWQS regression and introduce the hierarchical BWQS (HBWQS) regression model; in Section 3, we provide results from six simulated scenarios, also providing an accuracy measure. Section 4 deals with two real-case examples on the relationship between prenatal chemical exposures and both gestational age and gestational age acceleration metrics. Finally, Sections 5 and 6 offer a discussion and some concluding remarks, respectively.
2. Methods: regression model and distributions
2.1 The Bayesian Weighted Quantile Sum (BWQS) regression
We first review the BWQS regression as a framework for assessing the effect of a complex exposure mixture on a continuous normally distributed outcome, yi.11, 15 For each subject i=1,…,n, the BWQS regression relates the outcome to M components of the mixture zi=(z1i,…,zMi) through a weighted index 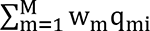 , which represents the linear combination of the quantiles qi=(q1i,…,qMi) of zi, i.e. the empirical cumulative distribution function of zi,, and with wm identifying the weights mapped to the m-th mixture component (zm). The model can be adjusted for C relevant covariates xi=(x1i,…,xCi) and its general form is:
, which represents the linear combination of the quantiles qi=(q1i,…,qMi) of zi, i.e. the empirical cumulative distribution function of zi,, and with wm identifying the weights mapped to the m-th mixture component (zm). The model can be adjusted for C relevant covariates xi=(x1i,…,xCi) and its general form is:
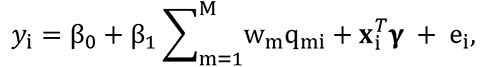 where β0 is the intercept, β1 is the regression coefficient representing the overall linear effect between the weighted index and the outcome, γ= (γ1,…, γC) represents the effects of the potential confounders on the outcome, and ei is the error term distributed as a N(0,σy2), with σy2 being an InvGamma(0.01, 0.01). 11, 15 Considering a Bayesian estimation procedure, we impose a weakly informative priors for all the regression parameters β = (β0, β1) and γ by eliciting two independent multivariate Normal distribution with null mean vector and diagonal covariance matrix with large values (e.g. 100) on the diagonal. As the vector of weights w = (w1,…, wM) follows a Dirichlet prior distribution parameterized by a vector of 1. 11, 15
where β0 is the intercept, β1 is the regression coefficient representing the overall linear effect between the weighted index and the outcome, γ= (γ1,…, γC) represents the effects of the potential confounders on the outcome, and ei is the error term distributed as a N(0,σy2), with σy2 being an InvGamma(0.01, 0.01). 11, 15 Considering a Bayesian estimation procedure, we impose a weakly informative priors for all the regression parameters β = (β0, β1) and γ by eliciting two independent multivariate Normal distribution with null mean vector and diagonal covariance matrix with large values (e.g. 100) on the diagonal. As the vector of weights w = (w1,…, wM) follows a Dirichlet prior distribution parameterized by a vector of 1. 11, 15
2.2 The hierarchical Bayesian Weighted Quantile Sum (HBWQS) regression for multiple cohorts
We now assume J (j=1,…J) cohorts harmonized and combined in a single dataset with the goals of 1) identifying the overall mixture index that summarizes the most harmful mixture compounds across cohorts and 2) assessing the cohort-specific association between the overall mixture index and the outcome of interest. We define the hierarchical BWQS regression as:
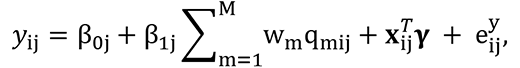 where βj = (β0j, β1j) are random terms of the j-th cohort, respectively intercept and coefficient mapped to the mixture, following independent Normal distributions centered in µβ= (µβ0, µβ1) and with variance σβ= (σβ0, σβ1), with hyperpriors µβ ∼ N(0, 100*I), σβ0 ∼ IG(0.01, 0.01), σβ1 ∼ IG(0.0.01), and I indicating the 2×2 diagonal matrix. In this model, the quantiles qi are calculated using exposure levels across cohorts in order to create a common scale for the exposure mixture.
where βj = (β0j, β1j) are random terms of the j-th cohort, respectively intercept and coefficient mapped to the mixture, following independent Normal distributions centered in µβ= (µβ0, µβ1) and with variance σβ= (σβ0, σβ1), with hyperpriors µβ ∼ N(0, 100*I), σβ0 ∼ IG(0.01, 0.01), σβ1 ∼ IG(0.0.01), and I indicating the 2×2 diagonal matrix. In this model, the quantiles qi are calculated using exposure levels across cohorts in order to create a common scale for the exposure mixture.
To compare the BWQS and the HBWQS regression models we can use the Watanabe-Akaike information criterion (WAIC), which is comparable to the Akaike Information Criteria for frequentist approaches. The WAIC compares models fitting the same data, and it is computed using the log-likelihood evaluated at the posterior simulations of the parameter values.16, 17 The WAIC closely approximates a Bayesian cross-validation due to its foundation on the series expansion of leave one out cross validation.16, 17
3. Simulation studies
In this Section, we reported the results of a simulation study involving six parametric scenarios. Namely, we simulated six scenarios including 500 synthetic datasets each. To show the stability and goodness of our models, we reported the mean estimates, the bias, the mean square error (MSE) and the empirical coverage of all parameters (βj, w, γ, and σy2) for all scenarios.
In the first five scenarios, we simulated each synthetic dataset comprising five cohorts, while in the sixth scenario we considered 10 cohorts. In all cohorts, we assumed to have a continuous outcome, four mixture components, which were ranked using quartiles, and three covariates. We included two continuous and one binary covariates, whose respectively coefficients were γ = (−0.4, 0.2, 0.5). The cohort sample sizes were assumed to be different in order to mimic the reality. In the first five scenarios, the five cohorts had the following sample sizes: 250, 200, 150, 100, and 100, while the sixth scenario included 10 cohorts of 96, 87, 96, 60, 70, 107, 56, 53, 106, and 72 observations. We assumed σy2 =1 throughout scenarios, unless it is differently specified.
Scenario 1. We assumed that the mixture components contributed differently to the overall mixture w=[0.1,0.4,0.3,0.1] and that the random intercept and slope βj = (β0j, β1j) in the j-th cohort (j=1,..,5) were β1 = (0.65, −1.7); β2 = (−0.38, −0.94); β3 = (0.15, −0.11); β4 = (−0.98, −1.45); β5 = (1.13, −1.88).
Scenario 2. We assumed to have a predominant weight in the overall mixture (i.e. with higher weight wm compared to the other components) and we set the mixture component weights to w=[0.7,0.1,0.1,0.1]. The remaining parameters were unchanged from Scenario 1.
Scenario 3. We evaluated the effect of having a very small weight for a specific mixture component: w=[0.30, 0.45, 0.24, 0.01] and random terms were unchanged from Scenario 1. Scenario 4. Compared to Scenario 1, we assumed that in the first cohort there was no association between the mixture and the outcome, so we had different random terms for first cohort β1 = (0.65, 0), while we left unchanged the remaining random terms and weights.
Scenario 5. We assumed a larger model variance σ 2 =3.12 compared to all other scenarios, while we left unchanged all parameters from Scenario 1.
Scenario 6. We assumed 10 cohorts with random terms of β1 = (0.65, −1.7); β2 = (−0.38, −0.94); β3 = (0.15, −0.11); β4 = (−0.98, −1.45); β5 = (1.13, −1.88), β6 = (−0.55, −0.87); β7 = (0.98, −0.04); β8 = (0.55, −0.81); β9 = (−0.18, −1.95); β10 = (0.13, −0.58). We changed the variance of the model to be σy2 =0.8. We left the weights unchanged from Scenario 1.
We implemented our models and all analyses leveraging Stan, which is a C++ library for Bayesian inference using the No-U-Turn sampler (a variant of Hamiltonian Monte Carlo), and RStan, an R interface to Stan. We illustrated the HBWQS code at https://github.com/ElenaColicino/bwqs/.
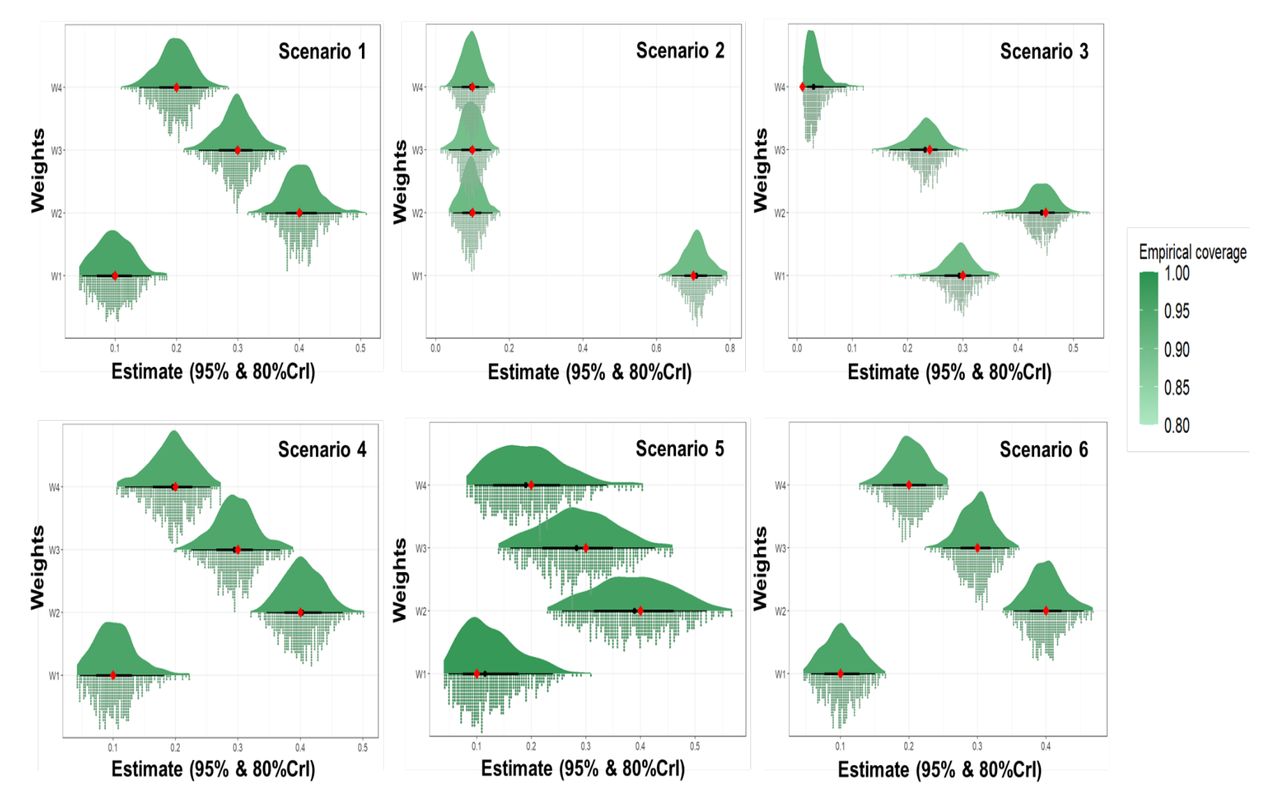
Each model included a single Markov chain of 10,000 iterations with a warm-up of 5,000 and thinning of 10. Table S1 summarizes the truth, estimate, bias, mean square error (MSEs) and empirical coverage of the parameters across all scenarios, while Figures S1-S2 showed the true value, the estimate, and the empirical coverage of all parameters.
Main characteristics of study participants of the PRISM Boston (BOS), PRISM New York City (NYC) and F1000 studies.
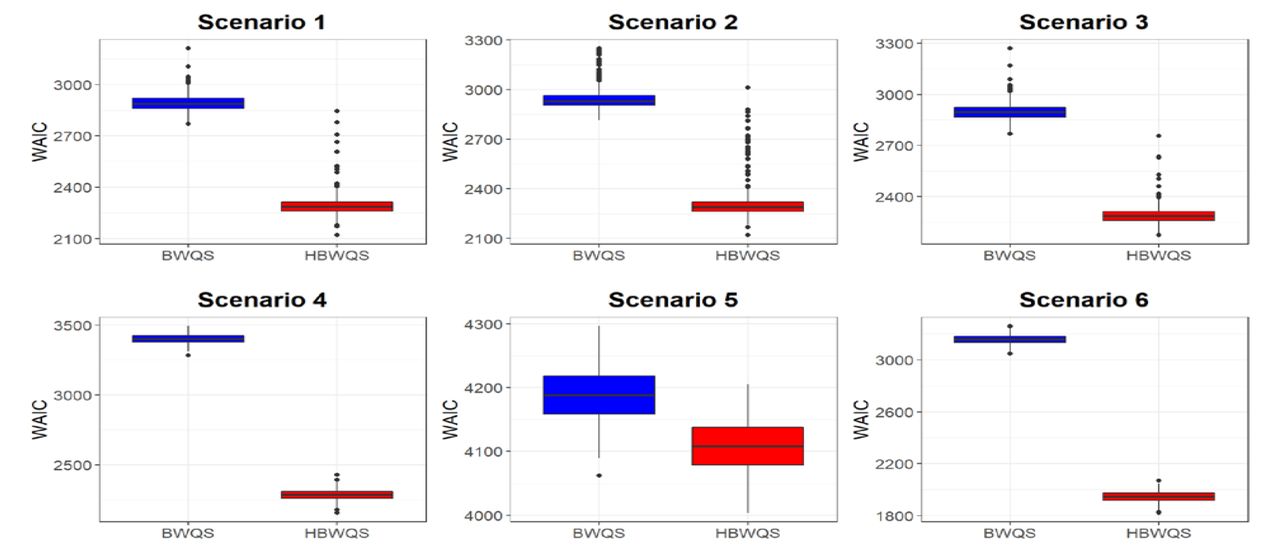
Across scenarios, all parameters showed very little bias ranging from −0.83 to 0.57 for random terms, which were in the [-1.95, 1.13] domain, and from −0.01 to 0.03 for weights, which individually were in the [0,1] domain. The larger biases for random terms were in Scenario 5 due to the large model variability (σy2 =3.12). In general, posterior means provided reliable estimates also in terms of mean squared errors (MSEs) (Table S1). The MSEs were small with the exceptions of random intercepts in Scenario 5, due to the large model variability. All estimated values for weights showed an empirical coverage over 90%, while the majority (34/35 random intercepts and 32/35 random slopes) of random terms showed an empirical coverage above 90% across scenarios (Table S1). We also provided a summary of BWQS results in Table S2, showing good estimates for weights, while larger model variances compared to the actual values for five out of six simulated scenarios. To compare the results from HBWQS and BWQS on simulated data, we used the WAIC metrics, which indicate better performance with the smaller values. In our simulations, the WAIC metrics for the HBWQS regression showed a better average performance across scenarios than the BWQS regression (Figure 1).

Watanabe-Akaike information criterion (WAIC) for the Bayesian Weighted Quantile Sum regression (BWQS) and the hierarchical BWQS (HBWQS) regression across six simulated scenarios.
Both HBWQS and BWQS models had reasonable computing time. The computing time for the HBWQS model required an average time of 7 minutes (426 seconds) for all the scenarios, except Scenario 5, which required 40 minutes (2,413 seconds), while the BWQS computing time required an average of 5 minutes (308 seconds) (Table S3). This is consistent with expectations since an increased model complexity and model variability imply more computing time to have an appropriate model convergence.
4. Real data applications: gestational age and gestational age acceleration in relation to metal mixture
4.1 Cohorts’ descriptions and ethics
The PRogramming of Intergenerational Stress Mechanisms (PRISM) study
The mother-infant pairs included in these analyses are participants in the PRISM prospective pregnancy cohort study designed to examine the effects of prenatal and early life psychosocial, physical, and chemical environmental exposures on child developmental outcomes. Beginning in 2011, pregnant women were recruited from prenatal clinics in Boston and New York City. Women were eligible if they were English or Spanish speaking, 18 years or older, and pregnant with a singleton. Exclusion criteria included maternal intake of ≥7 alcoholic drinks per week prior to pregnancy, any alcohol intake after pregnancy recognition, and HIV+ status. The study recruited n=1,109 women at 25 ± 7 weeks of gestation receiving prenatal care from the Beth Israel Deaconess Medical Center and East Boston Neighborhood Health Center in Boston, MA (from March 2011–December 2013) and Mount Sinai Hospital in New York City, NY (from April 2013– February 2020) who delivered a live newborn with no significant congenital anomalies noted at birth that could impact participation in follow-up procedures.18, 19 Metals and creatinine were measured in a subset who also had urine samples collected during pregnancy (N=641, 252 in Boston (BOS) and 389 in New York City (NYC)). Within two weeks of enrollment, mothers completed standardized surveys via in-person interviews to ascertain relevant covariates and exposures. Study protocols were approved by the Institutional Review Boards (IRBs) of the Brigham and Women’s Hospital and the Icahn School of Medicine at Mount Sinai. Mothers provided written consent in their primary language. In these analyses we split the PRISM study using the enrollment location, due to the differences in participants’ characteristics (Table 1) The First 1000 Days and Beyond (F1000 or FTDL) study is a longitudinal pregnancy cohort of mother-child pairs living in Virginia.20, 21 Women were ≥18 years of age and willing to participate in 12 longitudinal surveys during the first 12 months postpartum. All women were enrolled in 2012 at 26 ± 5 weeks’ gestation at the Inova Health System in Falls Church, VA for the genetics study. Starting in 2016, participants from the ongoing F1000 study were invited to participate in the national ECHO program, with 1,400 mothers consenting for themselves and their children to participate between 2016 and 2021.22, 23 A total of 708 mother-child pairs with complete data on birth information also consented for biospecimen collection including urine for metal assays. The human studies committee at the George Mason University ceded review to the Mount Sinai IRB for ECHO follow-up and mothers provided written informed consent.
4.2 Primary birth outcomes
Gestational age and gestational age acceleration metrics are good indicators of the fetal environment and predictors of neonatal short-and long-term child health24–26
Gestational age
In PRISM, gestational age was calculated based on maternal report of last menstrual period (LMP) and updated, if discrepant by more than three weeks, based on obstetric estimates from ultrasound data in the medical record review at delivery.27 In F1000, ultrasounds were not performed routinely as standard of care; thus, gestational age was based on LMP and a standardized physical examination at birth to determine gestational age.28, 29
Gestational age acceleration metrics
In PRISM, we estimated three placental epigenetic gestational age estimators: a “robust placental clock” (RPC), a “control placental clock” (CPC) and a “refined RPC” (refRPC). 30 The RPC metric was developed to be unaffected by pregnancy conditions, such as preeclampsia, gestational diabetes, and trisomy; the CPC metric was designed for measuring gestational age in normal pregnancies, and the refRPC was trained for uncomplicated term (gestational age > 36 weeks) pregnancies.30 We then used the epigenetic gestational age estimators to compute gestation age acceleration metrics that were formally defined as studentized residuals resulting from regressing the gestational age estimators on observed gestational age. By definition, these residual-based measures of gestational age acceleration were not correlated with true gestational age (r=0).30 The three placental epigenetic gestational age metrics leveraged PRISM placenta DNA methylation data collected immediately following birth as previously described.31, 32 Briefly, sufficient DNA was available from 234 placenta samples and DNA methylation was measured using the 450K array (Illumina, San Diego, CA). To minimize batch effects, samples were randomized into chips and plates.33, 34 Raw methylation data were processed using the R package ewastools.35, 36 We removed samples that were outliers and were potentially contaminated, and we corrected for dye bias using RELIC.37 Observations with detection p-values < 0.05 were also removed.35, 36 In F1000, placenta DNA methylation data were not available, so analyses on gestational age acceleration metrics included only sites from the PRISM study.
4.3 Prenatal chemical exposures: Arsenic, Cadmium and Lead concentrations
In both cohorts, maternal urine collected during gestation was stored at −80°C, and shipped to Mount Sinai for laboratory analysis as previously described. 19 Urine samples (200 µl) were diluted with solution in a polypropylene trace-metal-free Falcon tube.19 Samples were analyzed using matrix-matched calibration standards using an 8800 triple-quad inductively coupled plasma tandem mass spectrometer (Agilent Technologies) with appropriate gases to eliminate ion interference. Internal standards were used to correct for differences in sample introduction, ionization, and reaction rates.19 To monitor the accuracy, recovery rates, and reproducibility of the procedure, quality control and quality assurance procedures included analyses of initial calibration verification standards and continuous calibration verification standards.19 The limits of detection for analytes by this procedure were between 0.02 and 10 ng/ml.19 When we had two urinary metal measurements during gestation, we considered the average exposure between the 2nd and the 3rd trimesters to reflect the entire pregnancy exposures.
4.4 Covariates
Both PRISM and F1000 studies included maternal age, race/ethnicity, parity, maternal education and child sex.20, 26 Urinary creatinine levels, available for both cohorts, were measured using a well-established colorimetric method (limit of detection [LOD]: 0.3125 mg/dL)38 and were used to correct metal levels for urinary dilution variation. Creatinine levels were averaged when we considered the simple average exposure between the 2nd and the 3rd trimesters. Individuals with missing covariate information or smoking during pregnancy, for consistency across studies and due to the strong smoke effect on birth outcomes, were removed from the analyses, as described in the flowchart (Figure S3).
4.5 Models
We log2-transformed all metals to reduce the skewness of their distributions and we harmonized the covariates to accommodate any major difference. We then employed the HBWQS regression to evaluate the association of each outcome with the urinary metal mixture including all cohorts. We also applied the BWQS regression in each cohort separately and combining all cohorts in a single analysis. All HBWQS models included a single chain of 20,000 iterations, whose 10,000 were part of the burn-in and we used 10 as thinning parameter, while all BWQS models had a single chain of 10,000 with 5,000 warm-up and 3 thin. We reported the quality of the convergence of the chain of each parameter using 1) trace and 2) autocorrelation plots, 3) Rhat coefficients, and 4) the number of effective sample size (ESS), which reflects the autocorrelation within the chain.39, 40 For the gestational age analyses, we first analyzed all n=1,349 samples (BOS n=252, NYC n=389, F1000 n=708, Table 1, Figure S3) and we then restricted our sample size to children born at term (gestational age ≥ 37 weeks) to mitigate any potential skewness of the outcome distribution, thus leaving n=1,276 (BOS n=238, NYC n=346, F1000 n=692) for the analyses. For the analyses on gestational age acceleration metrics, we considered only PRISM data, thus leaving n=170 (BOS n=106, NYC n=60, Table 1, Figure S3). We finally compared HBWQS and BWQS regression on the same data using the WAIC metrics and provided computing time for all analyses.
4.5 Results
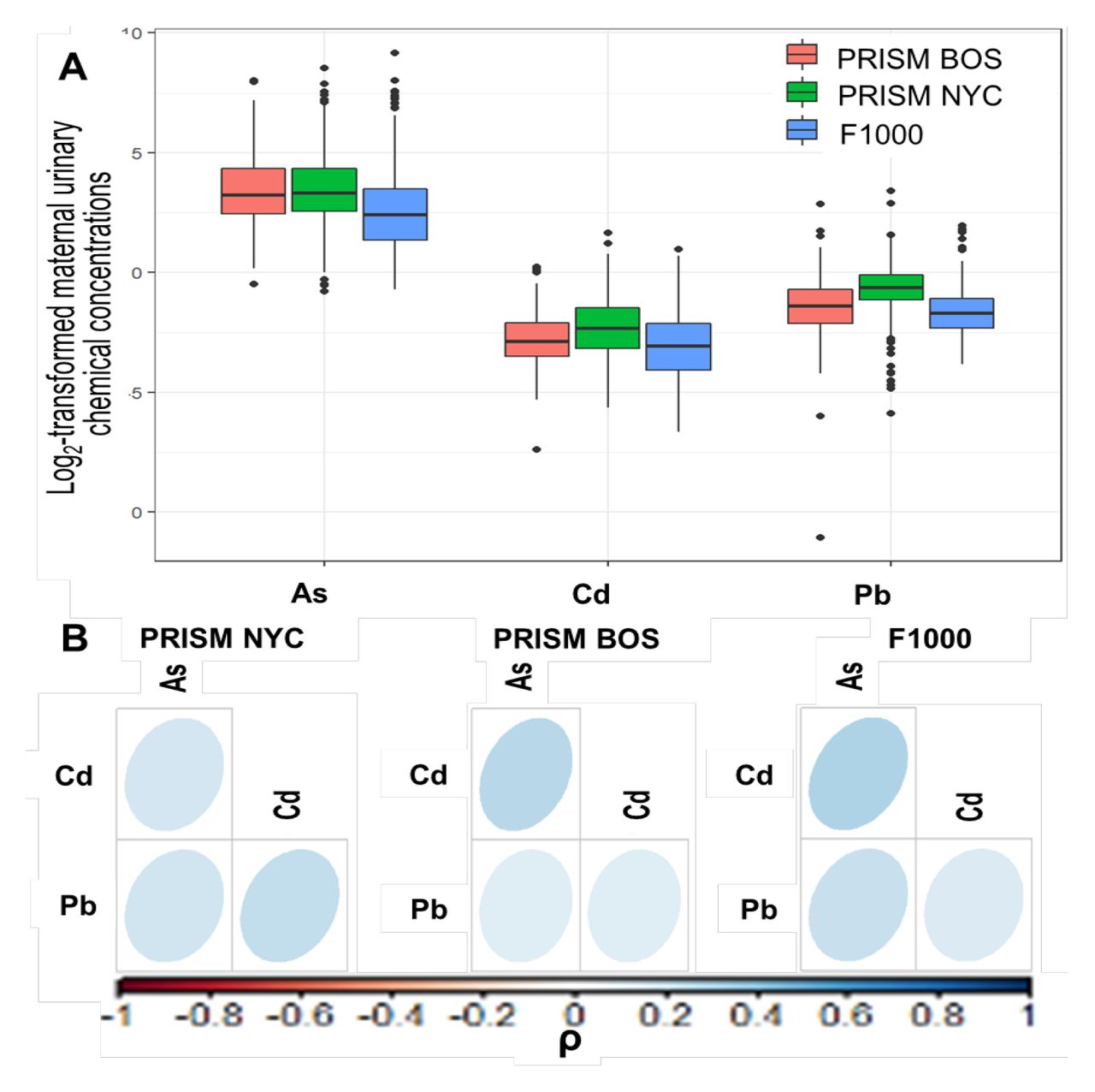
The three studies showed differences across participants’ characteristics. Women living in NYC showed shorter gestational age (38.5 weeks) compared to the other studies (Gestational age: BOS: 39.2, F1000: 39.3, pvalue<0.001, Table 1) and delivered at younger age (28.1 years) compared to other locations (BOS: 32.0, F1000: 32.5, pvalue<0.001). We identified differences of race/ethnicity distribution across studies (pvalue<0.001), with higher proportion of Black (57%) and non-Black Hispanic (38%) in PRISM NYC, compared to PRISM BOS (Black: 21%, Non-Black Hispanic: 33%) and F1000 (Black: 4%, Non-Black Hispanic: 14%). No difference of gestational age acceleration was identified between PRISM BOS and PRISM NYC (Table 1). Despite the difference in mean metal concentrations across cohorts (pvalue<0.001; As PRISM BOS: 3.45 PRISM NYC: 3.42 F1000: 2.57; Cd: PRISM BOS:-2.83 PRISM NYC:-2.20 F1000:-3.04; Pb: PRISM BOS:-1.43 PRISM NYC:-0.65 F1000:-1.65, Table 1), the metals had common domains (Figure 2A) and similar correlation pattern (Figure 2B). To create a common scale, the metal domains across studies were used to compute the exposure quantiles. The correlation between metals was moderate in each cohort, ranging between 0.13-0.28 in PRISM BOS, between 0.18-0.24 in PRISM NYC and between 0.15-0.31 in F1000. All models showed a good convergence of the chains: 1) all trace plots show good evolution of the parameter vector over the Markov chain iterations (Figures S4-S5), 2) the autocorrelation across post-warmup iterations of the posterior distributions dropped quickly to zero with increasing lags, indicating no autocorrelation across iterations (Figures S6-S7), 3) Rhat statistics were approximately 1 for all parameters, indicating that the chain has converged to the equilibrium distribution (Tables S4-S5) and 4) the ratio between the effective sample size (ESS) and the total sample size of chain iterations of the posterior distributions was above 0.75 for all parameters, indicating good ability of the chain to estimate the true mean value of the parameters (Figures S8-S9, Tables S4-S5). We reported the computing time for the HBWQS and BWQS models on the same data (Table S6). As we showed in the simulated scenarios, more complex models, i.e. HBWQS regressions, had a higher computing time with than simple ones, i.e BWQS regressions.

A. Boxplots of the log-2 transformed urinary metal levels (Arsenic (As), Cadmium (Cd), Lead, (Pb), in the three studies (PRISM Boston (BOS), PRISM New York City (NYC), F1000). B Pearson correlation plots of the log-2 transformed urinary metal levels within each study.
Gestational age
The HBWQS regression showed a negative association between the metal mixture and gestational age in the PRISM NYC (Est. −0.22; 95%CrI:-0.40; −0.02; 80%CrI: −0.34; −0.10, Table S4, Figure 3), with Cd (64%) contributing the most to the overall mixture effect (As: 21%; Pb:15, Figure 3). While using the BWQS regression, no evidence of association was identified between gestational age and metal mixture at any site separately (PRISM BOS: Est. 0.02; 95%CrI:-0.23; 0.28; 80%CrI: −0.15; 0.19; PRISM NYC: Est. −0.11; 95%CrI:-0.53; 0.32; 80%CrI: −0.40; 0.17; F1000: Est. −0.05; 95%CrI:-0.18; 0.08; 80%CrI: −0.13; 0.03 Table S4, Figure 3) or in combination (Est. −0.09; 95%CrI:-0.24; 0.06; 80%CrI: −0.19; 0.01 Table S4, Figure 3). The HBWQS showed a better performance (WAIC: 5180) than the BWQS regression on the combined sites (WAIC: 5200) (95%CrI of the WAIC difference: 1.00; 39.80). Once we included only women that delivered at term (≥37 weeks) (n=1,276), the majority of results were consistent with previous analyses showing no association between the metal mixture and gestational age in individual sites or in combination. Although HBWQS findings showed no longer a significant association between gestational age and the metal mixture in PRISM NYC, the relationship was consistent in the directionality (Table S4, Figure S10).

A-C Estimated association between the prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age (weeks) in the PRISM New York City (NYC), PRISM Boston (BOS) and F1000 by using the Bayesian weighted quantile (BWQS) regression at the individual sites (cohort BWQS) and in the overall sample aggregating all sites (Overall BWQS) and by using the hierarchical BWQS (HBWQS) regression. D Contribution of metals to the mixture.
Gestational age acceleration
There was no evidence of the association between the metal mixture and the gestational age acceleration metrics in the overall PRISM study combining both sites with BWQS regressions (RPC metric: Est. −0.05; 80%CrI: −0.18; 0.08; CPC metric: Est. - 0.3 80%CrI: −0.16,0.10; refRPC metric: Est. −0.10; 80%CrI: −0.22; 0.03 Table S5, Figure 4) or using the HBWQS approach (RPC metric: PRISM BOS: Est. −0.02; 80%CrI: −0.15; 0.12; PRISM NYC: Est. −0.08; 80%CrI: −0.24; 0.06; CPC metric: PRISM BOS: Est. 0.00; 80%CrI: −0.14; 0.14; PRISM NYC: Est. −0.05; 80%CrI: −0.20; 0.10; refRPC metric: PRISM BOS: Est. −0.10; 80%CrI: - 0.24; 0.04; PRISM NYC: Est. −0.13; 80%CrI: −0.29; 0.03 Table S5, Figure 4). However, all estimates showed consistent negative directionality and similar magnitude of the mixture effects on the outcomes. Across gestational age acceleration metrics, HBWQS WAIC values were similar to those of the BWQS model combining the two sites (RPC metric: HBWQS: 461 BWQS: 460; 95%CrI WAIC difference: −3.8; 1.7; CPC: HBWQS: 461 BWQS: 461; 95%CrI WAIC difference: −3.3; 3.0 refRPC: HBWQS: 462 BWQS: 460; 95%CrI WAIC difference: −3.1; 0.1) and under these circumstances the simplest BWQS analysis is preferable than the HBWQS regression with random terms for site. We identified a weak evidence of a negative association between the metal mixture and both RPC (Est. −0.34; 95%CrI:-0.78; 0.10; 80%CrI: −0.63; −0.05), and refRPC (Est. −0.31; 95%CrI:-0.74; 0.12; 80%CrI: −0.59; −0.03) in the PRISM NYC study, probably due to the higher homogeneity of this population. In both associations, Pb (RPC: 46%, refRPC: 41%) and Cd (RPC: 34%. refRPC: 37%) showed the highest contribution to the mixture (Table S5, Figure 4A-B).

A.1-A.2, B1-B.2, C.1-C2 Estimated association between the prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age acceleration metrics (RPC, CPC, refRPC) in the PRISM New York City (NYC), and PRISM Boston (BOS) by using the Bayesian weighted quantile (BWQS) regression at the individual sites (cohort BWQS) and in the overall PRISM sample aggregating all sites (Overall BWQS) and by using the hierarchical BWQS (HBWQS) regression. A.3, B.3, C.3 Contribution of metals to the mixture. RPC= robust placental clock; CPC: control placental clock; refRPC: refined RPC
5. Discussion
We developed and applied the HBWQS regression, which estimates (i) an overall mixture index for the exposures and (ii) cohort-specific regression coefficients that characterize the association between an outcome and this overall mixture index. The overall mixture is a weighted index that linearly combines the exposures that can be previously ranked in quantiles. The mixture weights are assumed to follow a Dirichlet distribution, thus implying that each weight is constrained to be positive and the sum of all weight is constrained to be 1, so that they can be sorted by relative importance. Exposures that affect the outcome to a greater degree have higher weights, whereas exposures with little or no impact on the outcome have near-zero weights. The HBWQS method uses random slopes to infer the association between the outcome and the overall weighted mixture index in each cohort. Our simulations showed that the parameters estimated with HBWQS regression showed very little bias and had a good empirical coverage across scenarios. The MSEs were small and close to zero for the majority of parameters. We also compared the HBWQS and BWQS regressions using the WAIC and simulation findings showed that the HBWQS performed better than BWQS regressions on the same datasets.
This approach offers several advantages. First the overall mixture index is based on the quantile for each metal exposure, thereby reducing the impact of extreme values in right-skewed distributions. This step also creates a common scale across cohorts for each exposure, because the quantiles are created using the exposure data from all cohorts15. Second, the weights wj are constrained to be positive and sum to 1 so that all exposures in the mixture are assessed simultaneously and incorporated into a single index.15 These weights give the relative importance of the exposures, identifying which exposure within the mixture is the most relevant into the mixture.15 Third, the hierarchical form of this approach and specifically the random effect terms enable us to have a cohort-specific association between the outcome and the overall mixture index and a cohort-specific intercept, respectively. In addition, this hierarchical method incorporates the differences in exposures correlation structure of each cohort with random effects and facilitates sharing information across cohorts as all hierarchical Bayesian approaches do. 41 The advantages of information sharing of hierarchical modeling include the shrinkage of extreme coefficient estimates towards an overall average and the fewer observations a cluster, i.e. cohort, has the more information is borrowed from other clusters and the greater the pull towards the average estimate is.42, 43 Finally, HBWQS regression capitalize upon the idea that independent studies are randomly sampled from a population of studies, and individual subjects are randomly sampled within each study.41 The combination of multiple individual studies, which are thought to be sub-studies from a population of studies, substantially increases the statistical power for testing research hypothesis and integrates between-study heterogeneity. Indeed, when multiple independent studies are combined, there is often an increase in statistical power when testing the same hypotheses based upon the aggregated versus independent studies.44 Also the between-study heterogeneity may serve to have more generalizable conclusions on the composition of the overall mixture index and may offer novel insights of mixture-outcome associations in each individual study. This approach may help mitigate the need for creating novel studies designed to resolve conflicting findings across studies posited to result from between-study design differences.
We applied the HBWQS regression to three ethnically diverse populations sharing the same outcomes, exposures (As, Cd, and Pb) and harmonized covariates. We found a detrimental negative association between the metal mixture and gestational age in the PRISM NYC sample using the HBWQS regression. The mixture was mostly composed by Cd (64%). Although there was no evidence of the mixture associations with gestational age acceleration metrics using HBWQS and BWQS on aggregated sites, all results suggested a negative direction of the associations. We also uncovered a weak evidence of a negative association between the metal mixture and gestational age acceleration (both RPC and refRPC) in the PRISM NYC sample using BWQS analysis with Cd and Pb having higher contribution to the mixture. This set of results suggested a slower biological gestational age with higher exposure in the metal mixture.
Our results are consistent with prior literature showing prenatal individual and mixture exposure to arsenic (As), lead (Pb), and cadmium (Cd) associated with shorter gestation 45–48, and preterm birth 47, 49–51 in populations exposed to chemicals at different levels of exposure. However, results considering environmental mixtures are still conflicting on showing the most detrimental exposures into the mixture and the significance of the overall the mixture-outcome associations.48, 52–55 Overall, our application highlighted the importance of evaluating metal mixture in relation to children health, including birth outcomes. Indeed, compared to adults, children have differences in metal exposure patterns and have greater vulnerability to metal exposures due to crawling, hand-mouth behaviors, and diet.56 In addition, environmental metal exposures may be higher than adults due to higher surface-to-volume ratios, higher consumption rates of food and water, higher respiration rates, and different toxicokinetics.56 Although high levels of many individual metal exposures, such as lead, produce observable toxicity early in life, including on gestational age, lower doses of multiple metals may be detrimental.57 During critical developmental periods, including gestation, low levels of numerous metal exposures might induce only subtle alterations in endocrine signaling or gene expression but could lead to permanent changes that program health outcomes throughout the life course.57
Our real case studies supported the idea that analyses at individual heterogeneous studies may be limited by sample size to capture small effect sizes, which can be different across studies and cannot be identified in aggregated analyses. This novel approach, however, cannot be blindly used for combining data from any independent studies, and some considerations should be assessed before applying the HWQBS regression. Although study harmonization is the first step for developing commensurate measures and a good HBWQS application, it may be not sufficient. Indeed, even identical variables which do not require harmonization may function differently across studies, due to differences in regional interpretations, historical periods, and laboratory conditions and technologies. 58 For example, the same construct may not have equivalent meaning across studies of children at different ages.44 Also, even when the same study-characteristics are assessed with the same instrument in different laboratories, some technical artifacts may lead to some discrepancies across studies. 44
In addition, differences in study design characteristics may limit the applicability of this approach. For example, cross-study discrepancies in exposure ranges or socio-demographic characteristics can largely increase the sources of between-study variability and thus limiting the applicability of this approach. 44 Also, information missing by design (e.g. race/ethnicity) in a single cohort may be challenging to address using this approach, which requires to constrain the analysis to common items. Although a missing at random assumption could seem quite plausible in many cases, the exclusion of the missing variable should be evaluated with sensitivity analyses and alternatives approaches, such as residual analysis. Also, different study-designs, such as case-control vs observational studies, may be not appropriately treated in a combined analysis with random effects and fixed-effects approach, i.e. BWQS regressions, should considered instead. 44 Finally there must be a sufficient number of independent samples and studies to allow for the reliable estimation of the random variability. Although further research can help to detect the sufficient number of samples and studies to allow for proper estimation of mixture-outcome association with random effects, prior general multilevel framework suggested between 20 to 30 as a minimum number of samples, while three as the minimum number of studies.44, 59 The influences of all these potential sources of between-study heterogeneity should be considered and mitigated when possible before applying HBWQS regression in order to optimally capture the estimates of the mixture-outcome associations and mixture component contribution.
Overall, the HBWQS approach directly supports the increased calls for data sharing, the maximization of available resources and the creation a new research endeavors, where researchers can contribute with secondary data analyses, and multiple innovative methodologies thus offering novel insights of the data. The analysis of extant data is an extremely cost efficient mechanism for conducting research and this efficiency is further realized by considering not just one but multiple existing datasets with same exposures and outcomes.60
6. Conclusions
The HBWQS regression is the first mixture approach that can be applied to multiple cohorts and that can illustrate the discrepancies in the mixture-outcome associations across cohorts and characterize the individual contribution of each component to the overall mixture index.
Data Availability
For all data produced in the present study please contact the corresponding author
Funding Acknowledgments and Disclaimer
The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Research reported in this publication was supported by the Environmental influences on Child Health Outcomes (ECHO) Program, Office of the Director, National Institutes of Health, under Award Numbers U2COD023375 (Coordinating Center), U24OD023382 (Data Analysis Center), U24OD023319 with co-funding from the Office of Behavioral and Social Science Research (PRO Core), 5U2COD023375-06 (Colicino), UH3OD023337 (Wright).
SUPPLEMENTAL MATERIAL

Real value (red dot), estimate (black dot), 95% and 80% Credible Interval (CrI) (thin and bold error bars), empirical coverage (color), and estimate distribution (distribution on the top, histogram on the bottom) of the random terms of the six simulated scenarios using the hierarchical Bayesian weighted quantile sum regression (HBWQS).

Real value (red dot), estimate (black dot), 95% and 80% Credible Interval (CrI) (thin and bold error bars), empirical coverage, and estimate distribution (distribution on the top, histogram on the bottom) of the weights of the six simulated scenarios using the hierarchical Bayesian weighted quantile sum regression (HBWQS).

Flowchart for A) The PRogramming of Intergenerational Stress Mechanisms (PRISM) study and B) The First 1000 Days and Beyond (F1000) study. Grey boxes indicate the study subsets for the main analysis on both gestational age and gestational age acceleration metrics.

Trace plots of the post-warmup (10,000-20,000) iterations (X-axis) of the posterior distribution (Y-axis) of all main parameters (random intercepts: b0, random intercept: b1, weights: w)) of the hierarchical Bayesian weighted quantile (HBWQS) regression linking prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age (weeks) in the PRISM New York City (NYC), PRISM Boston (BOS) and The First 1000 Days and Beyond (F1000) studies.

Trace plots of the post-warmup (10,000-20,000) iterations (X-axis) of the posterior distribution (Y-axis) of all main parameters (random intercepts: b0, random intercept: b1, weights: w)) of the hierarchical Bayesian weighted quantile (HBWQS) regression linking prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age acceleration metrics (panel A. RPC= robust placental clock; panel B. CPC: control placental clock; panel C. refRPC: refined RPC) in the PRISM New York City (NYC), and PRISM Boston (BOS).

Autocorrelation plots of the Markov chain of the posterior distributions (Y-axis)—separately up to 25 lags (X-axis). We showed the posterior distributions of all main parameters (random intercepts: b0, random intercept: b1, weights: w)) of the hierarchical Bayesian weighted quantile (HBWQS) regression linking prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age (weeks) in the PRISM New York City (NYC), PRISM Boston (BOS) and The First 1000 Days and Beyond (F1000) studies.

Autocorrelation plots of the Markov chain of the posterior distributions (Y-axis)—separately up to 25 lags (X-axis). We showed the posterior distributions of all main parameters (random intercepts: b0, random intercept: b1, weights: w)) of the hierarchical Bayesian weighted quantile (HBWQS) regression linking prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and and gestational age acceleration metrics (panel A. RPC= robust placental clock; panel B. CPC: control placental clock; panel C. refRPC: refined RPC) in the PRISM New York City (NYC), and PRISM Boston (BOS).

Ratio between the effective sample size (ESS) and total sample size of chain draws of the posterior distribution for main parameters(random intercepts: b0, random intercept: b1, weights: w)) of the hierarchical Bayesian weighted quantile (HBWQS) regression linking prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age (weeks) in the PRISM New York City (NYC), PRISM Boston (BOS) and The First 1000 Days and Beyond (F1000) studies.

Ratio between the effective sample size (ESS) and total sample size of chain draws of the posterior distribution for main parameters(random intercepts: b0, random intercept: b1, weights: w)) of the hierarchical Bayesian weighted quantile (HBWQS) regression linking prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and and gestational age acceleration metrics (panel A. RPC= robust placental clock; panel B. CPC: control placental clock; panel C. refRPC: refined RPC) in the PRISM New York City (NYC), and PRISM Boston (BOS) studies.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sensitivity analysis including only women that delivered at term (≥37 weeks) (n=1,276). A-C Estimated association between the prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age (weeks) in the PRISM New York City (NYC), PRISM Boston (BOS) and F1000 by using the Bayesian weighted quantile (BWQS) regression at the individual sites (cohort BWQS) and in the overall sample aggregating all sites (Overall BWQS) and by using the hierarchical BWQS (HBWQS) regression. D Contribution of metals to the mixture.
Real value, mean estimate, bias, Mean Square Error (MSE) and empirical coverage of the main parameters (random intercepts: beta0, random intercept: beta1, weights: W, model variance: sigma) of the six simulated scenarios using the hierarchical Bayesian weighted quantile sum regression (HBWQS).
Mean estimate and standard deviation (SD) of the main parameters (intercept: beta0, slope: beta1, weights: W, model variance: sigma) of the six simulated scenarios using the Bayesian weighted quantile sum regression (BWQS).
Mean computing time in seconds (and Standard Deviation (SD)) for the iterations of the generated posterior parameter values of the Bayesian weighted quantile (BWQS) and the hierarchical BWQS (HBWQS) regressions across all simulated Scenarios.
Mean estimate, 95% and 80% Credible Intervals (CrI), number of effective sample size (ESS) and Rhat of the association (b1 coefficient) between the prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age in the PRISM New York City (NYC), PRISM Boston (BOS) and F1000 studies by using the Bayesian weighted quantile (BWQS) regression at individual sites and in the overall PRISM study aggregating all sites and by using the hierarchical BWQS (HBWQS) regression using all sites.
Mean estimates, 95%CrI and 80%CrI, ESS, and Rhat of the intercept (b0 coefficient) and the contribution (weight (W)) of each metal to the mixture.
Mean estimates, 95% and 80% Credible Intervals (CrI), number of effective sample size (ESS) and Rhat of the association (b1 coefficient) between the prenatal urinary metal mixture exposure (Arsenic (As), Cadmium (Cd), and Lead (Pb)) and gestational age acceleration metrics (RPC, CPC, refRPC) (weeks) in the PRISM New York City (NYC), and PRISM Boston (BOS) by using the Bayesian weighted quantile (BWQS) regression at individual sites and in the overall PRISM study aggregating all sites and by using the hierarchical BWQS (HBWQS) regression using both sites.
Mean estimates, 95%CrI and 80%CrI, ESS, and Rhat of the intercept (b0 coefficient) and the contribution (weight (W)) of each metal to the mixture.
RPC= robust placental clock; CPC: control placental clock; refRPC: refined RPC
Computing time (in seconds) for 1,000 generated posterior parameter values from the Bayesian weighted quantile (BWQS) and the hierarchical BWQS (HBWQS) regressions during the warm-up and the post warm-up periods in the real case scenarios.
ECHO Collaborators Acknowledgments
The authors wish to thank our ECHO Colleagues; the medical, nursing, and program staff; and the children and families participating in the ECHO cohorts. We also acknowledge the contribution of the following ECHO Program collaborators:
ECHO Components—Coordinating Center: Duke Clinical Research Institute, Durham, North Carolina: Smith PB, Newby LK; Data Analysis Center: Johns Hopkins University Bloomberg School of Public Health, Baltimore, Maryland: Jacobson LP; Research Triangle Institute, Durham, North Carolina: Catellier DJ; Person-Reported Outcomes Core: Northwestern University, Evanston, Illinois: Gershon R, Cella D.
ECHO Awardees and Cohorts—Boston Children’s Hospital, Boston, MA: Bosquet-Enlow M.
References



