
ABSTRACT
Random-effect score test has become an important tool for studying the association between a set of genetic variants and a disease outcome. While a number of random-effect score test approaches have been proposed in the literature, similar approaches for multinomial logistic regression have received less attention. In a recent effort to develop random-effect score test for multinomial logistic regression, we made the observation that such a test is not invariant to the choice of the reference level. This is intriguing because binary logistic regression is well-known to possess the invariance property with respect to the reference level. Here, we investigate why the multinomial logistic regression is not invariant to the reference level, and derive analytic forms to study how the choice of the reference level influences the power. Then we consider several potential procedures that are invariant to the reference level, and compare their performance through numerical studies. Our work provides valuable insights into the properties of multinomial logistic regression with respect to random-effect score test, and adds a useful tool for studying the genetic heterogeneity of complex diseases.
Random-effect based score test has been widely used to investigate the association between a set of genetic variants and a health outcome/trait (Wu et al., 2011; Maity et al., 2012; Sun et al., 2013). While various outcomes/traits have been considered for random-effect based score test, the multinomial outcome has received little attention until recently. Multinomial outcome analysis has important practical applications, such as the subtype analysis which concerns the association between genetic variants and multiple subtypes of a disease (Eckel-Passow et al., 2019). In multinomial analysis, one level is specified as the reference level, and the other levels are compared to this level to examine the association between the outcome and genotypes. It is generally anticipated that a statistical test should be invariant to the choice of the reference level. However, in a recent study, we made the observation that such a test in general is not invariant to the choice of the reference level (Liu et al., 2021). This is intriguing, because the logistic regression model -a model often considered as a special case of the multinomial logistic regression model -has long been observed to possess the invariance property. Moreover, the lack of invariance property for multinomial logistic regression is highly undesirable in practice, because practitioners may make potentially contradictory conclusions due to different choices of reference levels. Here, we elaborate this issue and conduct investigations to understand the fundamental cause of the problem. We first explain why the considered test is not invariant to the choice of the reference level, and then derive the analytical form of the power function when a given level is used as the reference. We next use simulations to compare several potential ways to deal with the non-invariance issue, and then provide practical guidelines at the end of the letter.
Consider a multinomial logistic regression model with J levels and n subjects. For j = 1, …, J and i = 1, …, n, let Yji = 1 if the ith person belongs to jth level, and Yji = 0 otherwise. Let Xi be the adjusting covariates with the first element being the intercept and Gi be the genotypes of p variants. Assume that the J th level is the reference level, then the model can be written as 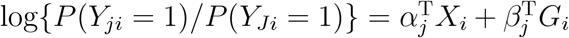 , for j = 1, …, J − 1, where αj and βj are the regression parameters. Let P (Yji = 1) = µji for j = 1, …, J. Note that
, for j = 1, …, J − 1, where αj and βj are the regression parameters. Let P (Yji = 1) = µji for j = 1, …, J. Note that 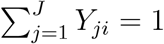 and
and 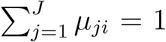 . Then under H0 : β1 = … = β(J−1) = 0, the log-likelihood can be written as
. Then under H0 : β1 = … = β(J−1) = 0, the log-likelihood can be written as
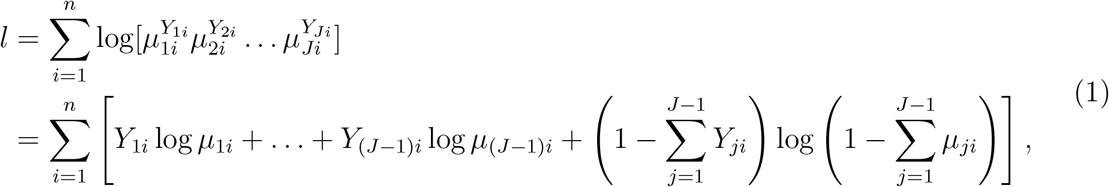 where
where 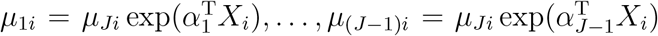 . Let
. Let 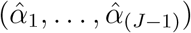 be the maximal likelihood estimator of (α1, …, α(J−1)) under H0. Then, the estimated µji’s are
be the maximal likelihood estimator of (α1, …, α(J−1)) under H0. Then, the estimated µji’s are 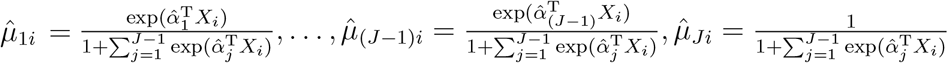 . Let G = (G1, …, Gn)T, Yj = (Yj1, …, Yjn)T and
. Let G = (G1, …, Gn)T, Yj = (Yj1, …, Yjn)T and 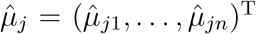 . Then, the half score of the random effects for βj(j = 1, …, J − 1) can be derived as
. Then, the half score of the random effects for βj(j = 1, …, J − 1) can be derived as
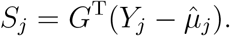 Let IJ−1 = diag(1, …, 1)(J−1)×(J−1), X = (X1, …, Xn)T, 𝕏= IJ−1 ⊗ X, 𝔾 = IJ−1 ⊗ G, and
Let IJ−1 = diag(1, …, 1)(J−1)×(J−1), X = (X1, …, Xn)T, 𝕏= IJ−1 ⊗ X, 𝔾 = IJ−1 ⊗ G, and 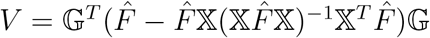 , where
, where
 and
and
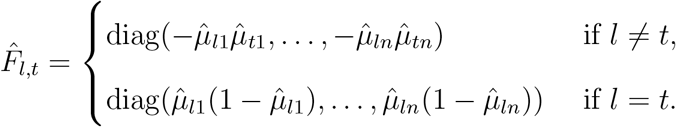 Then the score statistic
Then the score statistic 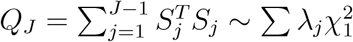 , where λj’s are eigenvalues of V. Let the p-value of this score statistic be PJ.
, where λj’s are eigenvalues of V. Let the p-value of this score statistic be PJ.
Suppose that we now wish to consider a different level as the reference level. Not to lose generality, let us consider the first level as the reference level. The model can be written as 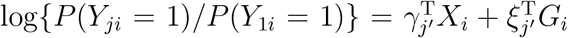 , for j = J, 2, …, J − 1 and j′ = 1, 2, …, J − 1, where γj′ and ξj′ are the regression parameters. Then under the null hypothesis that ξ1 = … = ξ(J−1) = 0, the log-likelihood has a similar form as equation (1) and can be written as
, for j = J, 2, …, J − 1 and j′ = 1, 2, …, J − 1, where γj′ and ξj′ are the regression parameters. Then under the null hypothesis that ξ1 = … = ξ(J−1) = 0, the log-likelihood has a similar form as equation (1) and can be written as
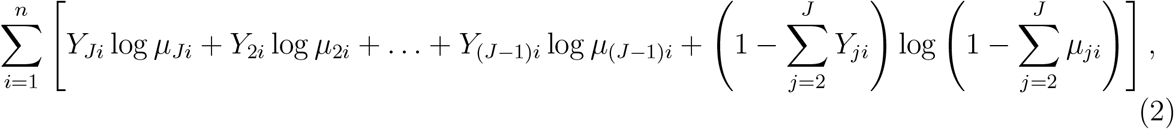 where
where 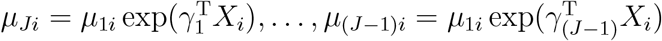 . Since the likelihood in (2) is equal to that in (1), one can show that the parameter estimators
. Since the likelihood in (2) is equal to that in (1), one can show that the parameter estimators
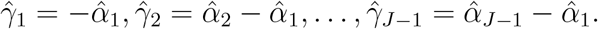 Therefore
Therefore  based on equation (2) is the same as that based on equation (1). Then the half score of the random effects for ξj(j = 1, …, J − 1) can be written as
based on equation (2) is the same as that based on equation (1). Then the half score of the random effects for ξj(j = 1, …, J − 1) can be written as
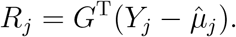 It follows that
It follows that
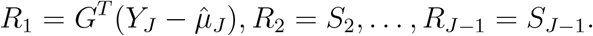 Then the score statistic
Then the score statistic 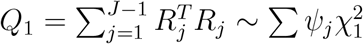 , where ψj’s are eigenvalues of V∗, where V∗ is the counterpart of V. Let the p-value of this score statistic be P1. In a similar manner, one can obtain Qj and Pj when jth level is chosen as the reference level.
, where ψj’s are eigenvalues of V∗, where V∗ is the counterpart of V. Let the p-value of this score statistic be P1. In a similar manner, one can obtain Qj and Pj when jth level is chosen as the reference level.
Recall that S1, …, SJ−1 are the scores when J th level is set as the reference, while R1, …, RJ−1 are the scores when the first level is set as the reference. The above derivation shows that there is a close relationship between S1, …, SJ−1 and R1, …, RJ−1. Indeed, using these results, we can further derive that
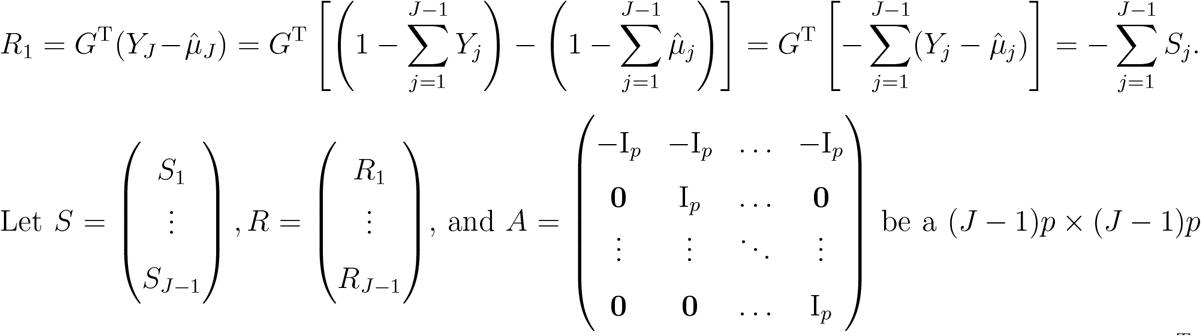 matrix, then it follows that R = AS and the covariance matrix of R, Cov(R) = ACov(S)AT. Therefore we obtain the key results that RTR = STATAS and V∗ = AV AT.
matrix, then it follows that R = AS and the covariance matrix of R, Cov(R) = ACov(S)AT. Therefore we obtain the key results that RTR = STATAS and V∗ = AV AT.
The above results indicate that, when a different level is chosen as the reference level, the random-effect score statistics (Qj and Qj′) will have different values, and the covariance matrices for the scores will also differ. Thus, Pj in general is not equal to Pj′. In other words, the p-values of the described statistics are not invariant to the choice of the reference level. Then an interesting question arises, that is, why does the logistic regression model, which is a special case of the multinomial logistic regression model, indeed have the invariance property? It turns out that for J = 2, one has A = −Ip and R = AS = −S. Then it follows that RTR = STS and V∗ = V. Thus, when J = 2, i.e., in the case of logistic regression, the p-value remains the same regardless of which level is chosen as the reference level.
Since the p-value varies with the choice of reference level, we investigate how this choice influences the statistical power. For ease of presentation, let us consider J = 3, i.e., three levels for the outcome. Using the relationship between R and S, we have
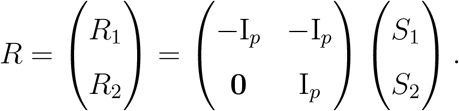 To facilitate presentation, define
To facilitate presentation, define  , then
, then 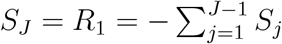 . Subsequently, we have that
. Subsequently, we have that
the score statistic using Y3 as the reference is
 ;
;the score statistic using Y1 as the reference is
;the score statistic using Y2 as the reference is
.
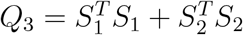
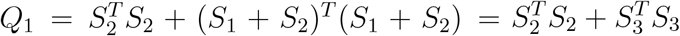
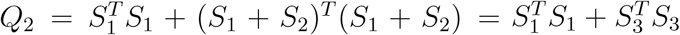
To study the asymptotical distribution of the test statistic Qj under the alternative hypothesis, let us consider a special case: X = 1n ≡ (1, …, 1)T. Then it can be shown that 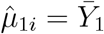 and
and 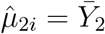 . Thus
. Thus
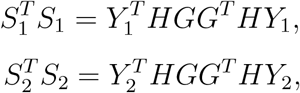 where
where 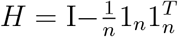 . It is known that asymptotically GT HY1 ∼ N (GT Hµ1, Δ1 = GT HΣ1HG), where Σ1 = diag(µ1(1 − µ1)). It follows that
. It is known that asymptotically GT HY1 ∼ N (GT Hµ1, Δ1 = GT HΣ1HG), where Σ1 = diag(µ1(1 − µ1)). It follows that 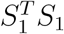 asymptotically follows a mixed noncentral chi-squared distribution:
asymptotically follows a mixed noncentral chi-squared distribution:
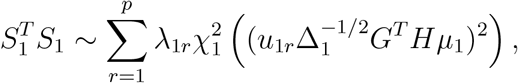 where λ1r’s are the eigenvalues of
where λ1r’s are the eigenvalues of 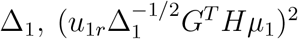 is the noncentral parameter, and u1r’s are the corresponding eigenvectors of Δ1. Similarly, let Σ2 = diag(µ2(1 − µ2)) and Δ2 = GT HΣ2HG, then
is the noncentral parameter, and u1r’s are the corresponding eigenvectors of Δ1. Similarly, let Σ2 = diag(µ2(1 − µ2)) and Δ2 = GT HΣ2HG, then
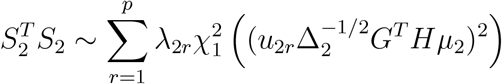 asymptotically, where λ2r’s are the eigenvalues of Δ2, and u2r’s are the corresponding eigenvectors of Δ2. To find the distribution for
asymptotically, where λ2r’s are the eigenvalues of Δ2, and u2r’s are the corresponding eigenvectors of Δ2. To find the distribution for 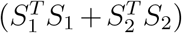 , let µ12 = (GT Hµ1, GT Hµ2)T, Σ12 = Cov(Y1, Y2) = diag(−µ1µ2), and
, let µ12 = (GT Hµ1, GT Hµ2)T, Σ12 = Cov(Y1, Y2) = diag(−µ1µ2), and
 Then one can derive that
Then one can derive that
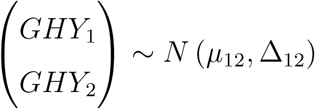 asymptotically. Therefore,
asymptotically. Therefore, 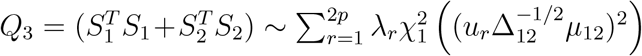 asymptotically, where λr’s are eigenvalues of Δ12, and ur’s are the corresponding eigenvectors of Δ12. In a similar manner, we can derive the asymptotical distributions of Q1 and Q2, respectively.
asymptotically, where λr’s are eigenvalues of Δ12, and ur’s are the corresponding eigenvectors of Δ12. In a similar manner, we can derive the asymptotical distributions of Q1 and Q2, respectively.
Recall that the power function is Ψj(Qj ≥ cj), where Ψj is the cumulative distribution function of Qj under H1, and cj is the critical value determined by the distribution of Qj under H0. It is tempting to directly compare Qj’s power functions using the above derived asymptotical distributions, but it is challenging to do so. This is because when the reference level is replaced, the Qj’s asymptotical distributions under both the null and the alternative hypotheses will change, making it extremely difficult to compare the power across difference reference levels. On the other hand, when the J subtypes have similar proportions among the n subjects and there is no adjusting covariate, one can show that the asymptotical distributions of the Qj’s are approximately equal to each other under the null hypothesis. Then it follows that the larger the statistic Qj is, the more likely one will reject the H0. Recall that 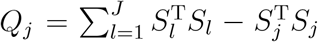 . This suggests that, to maximize the power, the level with the smallest
. This suggests that, to maximize the power, the level with the smallest 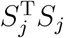 should be chosen as the reference. Our simulation studies confirmed this derivation (see Supplementary Material). The size of
should be chosen as the reference. Our simulation studies confirmed this derivation (see Supplementary Material). The size of 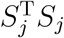 has practical interpretations. Recall that Sj is the inner product between
has practical interpretations. Recall that Sj is the inner product between 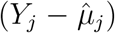 and G. Thus,
and G. Thus, 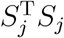 can be roughly seen as the correlation between Yj and genotype. This suggests the level that has the weakest correlation with the genotype should be chosen as the reference level, which well matches intuitions.
can be roughly seen as the correlation between Yj and genotype. This suggests the level that has the weakest correlation with the genotype should be chosen as the reference level, which well matches intuitions.
The above analysis provides theoretical insights into the power of the random effects score test. However, in practice, it is generally unknown which 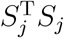 is the smallest among the J levels. This can be seen from the following. Taking S1 as an example, we have
is the smallest among the J levels. This can be seen from the following. Taking S1 as an example, we have
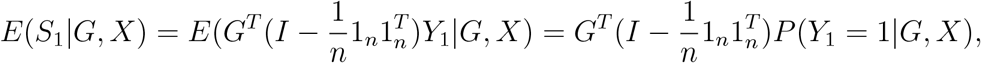 where P (Y1 = 1|G, X) is a n-length vector with each element being
where P (Y1 = 1|G, X) is a n-length vector with each element being
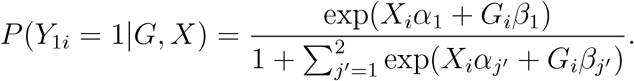 Clearly, E(S1|G, X) is a quantity related to G, X, α1, α2, β1, β2. Since α1, α2, β1, β2 are unknown parameters, it is difficult to evaluate the size of
Clearly, E(S1|G, X) is a quantity related to G, X, α1, α2, β1, β2. Since α1, α2, β1, β2 are unknown parameters, it is difficult to evaluate the size of 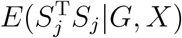 accordingly. Hence, practical data analysis will need statistical tests that are invariant to the choice of the reference level. In the following, we consider three procedures to tackle this issue, and compare the performance of the three methods through simulation studies.
accordingly. Hence, practical data analysis will need statistical tests that are invariant to the choice of the reference level. In the following, we consider three procedures to tackle this issue, and compare the performance of the three methods through simulation studies.
I. A Bonferroni procedure
We use each of the J levels as the reference level, and based on Qj’s, obtain the corresponding p-values P1, …, PJ. Then, use 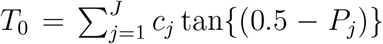 as the final p-value. The multiplication of J is a Bonferroni correction to ensure that correct type I error is maintained.
as the final p-value. The multiplication of J is a Bonferroni correction to ensure that correct type I error is maintained.
II. A Cauchy procedure
We propose to adapt to a Cauchy procedure (Liu and Xie, 2020) to combine the J p-values, P1, …, PJ. Specifically, let 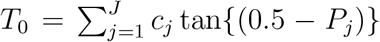 , where
, where 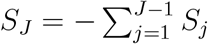 and cj is the pre-specified weight to accommodate prior knowledge on jth level. When there is no prior knowledge on the J levels, all cj = 1/J. Then under the null hypothesis, the p-value of T0 can be approximated by (1/2 − (arctan T0)/π) based on the Cauchy distribution.
and cj is the pre-specified weight to accommodate prior knowledge on jth level. When there is no prior knowledge on the J levels, all cj = 1/J. Then under the null hypothesis, the p-value of T0 can be approximated by (1/2 − (arctan T0)/π) based on the Cauchy distribution.
III. An integrative procedure
Consider a statistic L = (WDS)T (WDS), where W = diag(w1, …, wJ) ⊗ Ip, D = (IJ−1, −1J−1)T ⊗ Ip, and wj is a pre-specified weight for jth level. When wj’s are all equal, this statistic reduces to a statistic in Liu et al. (2021). Using the relationship that 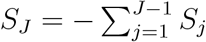 , we can show that
, we can show that 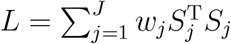 , which is invariant to the choice of the reference level. Alternatively, L can be written as
, which is invariant to the choice of the reference level. Alternatively, L can be written as  , where
, where 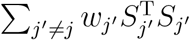 is a weighted version of Qj. Thus, L can be seen as an integrative statistic that consists of all the Qj’s. L asymptotically follows
is a weighted version of Qj. Thus, L can be seen as an integrative statistic that consists of all the Qj’s. L asymptotically follows 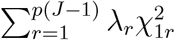 , where λr are the eigen values of WDV DTW T, and and
, where λr are the eigen values of WDV DTW T, and and  are independent
are independent 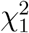 random variables.
random variables.
We conducted simulation studies to examine the type I errors of these procedures. We considered three levels for the response variable, and generated an adjusting covariate from N (0, 1). The regression coefficients for the intercept and the adjusting covariate were set as γ1 = (0.3, 1.2)T and γ2 = (0.3, 0.9)T. Next we simulated a p-vector of mutations with each element generated from a Bernoulli(0.05). To examine the type I error, we set ξj = 0 for j = 1, 2 and considered n ∈ {300, 500, 1000} for p = 10, 15. We evaluated the type I error at significance level α = 10−3. A total of 106 simulated datasets were generated for each setting. As shown in Table 1, all considered procedures are able to control the type I error. Next, we examined the power of these procedures. We considered two scenarios:
Empirical type I error (×10−3)
60% of ξjs’s were generated from Uniform(0.3, 1.5), and 40% of ξjs’s were generated from Uniform(−1.5, −0.3).
60% of ξjs’s were generated from N (0, 1.42), and 40% of ξjs’s were set to 0.
ξjs’s were fixed over all replicates. Each scenario was replicated 104 times. The power for scenarios I and II is summarized in Tables 2 and 3. The Bonferroni procedure has the lowest power, due to its conservativeness in controlling type I error. The integrative procedure properly accounts for the correlations among the J statistics, and tends to have the best performance among the considered procedures. Thus, we recommend the integrative procedure for practical data analysis.
Power for scenario I
Power for scenario II
In summary, we have shown that the random-effect score test for multinomial logistic regression is not invariant to the choice of the reference level. Our results provide analytical explanation to this issue, and simulation studies confirmed that the choice of the reference level influences the statistical power. We considered several procedures that can yield p-values (or statistics) that are not dependent upon the reference level, and the integrative procedure appears to have a more favorable performance. Overall, our study provides new insights into the random-effect score test for multinomial logistic regression, and will aid in the ongoing study of genetic heterogeneity for complex diseases.
Data Availability
Data used in this manuscript are simulated.



